1. Approach
Usual for programming on PC platform the floating point arithmetic is used. The decision is between single (float) or double. Whereas the existence of a double precision arithmetic processor suggest using double precision any time. This topic should not be discussed in this article, only a simple hint:
For good performance in C++, use float in all cases unless you actually need double.
You find some hints to this topic with this search text in internet. But notice, that some answers are related to PC programming or programming with high powerful processors. The world of embedded control uses often lower power (in electric consumption) and hence lower power in capability processors. Some of them have only float capability in there numeric hardware support, some have only fix point and some have not multiplication support. With this background read the bold message above.
The topic of this article is: Using fix point instead floating point.
1.1. Three reasons to use in some cases fix point also in a floating point environment.
-
1) The physical world is a fix point world. Measurement values are limited in range and solution. For example an electrical current may not greater than 1000 A, elsewhere the hardware is damaged. The meaningful resolution may be 0.01 A, no more if 1000 A can be measured.
-
2) Small processors (for low prices or low power consumption) often have not floating point arithmetic on chip. It is possible to calculate floating point in software, but it needs time and memory.
-
3) Often processors for embedded don’t support double arithmetic by hardware, they supports only single precision, float. But a float number has only 24 bit mantissa. There is a problem of integrators, the hanging effect: If the growth of an integrator is lesser than its resolution, the integrator does not change its value. That is given for example by a PID-Controller with a timing constant of about 10000 of step times or more, for example step time is 50 µs, a proper value for electric control, and the integration time is 500 ms, a proper value for smoothing an electrical direct current signal. If the integrator has a value of about 4.0f, and the input value is 0.001f, the input multiplied with the timing factor is 0.0000001f. And this value is too less, the integrator does not integrate it. Floating numbers have only 7..8 valid digits. - But if instead int32 is used, it has more as 9 digits. If the integer is proper scaled, this additional 8 bit or 2..3 digits are essential for such applications.
See also discussion in https://www.microchip.com/forums/m487270.aspx
1.2. Disadvantages of fix point
The advantage of floating point is obviously: There is no necessity to think about scaling, all multiplications runs well, scale from integer to float (measurement values), calculate in float, scale to integer for the actuator, ready, a simple obvious and manageable software.
Using fix point the scaling should not be a problem. Adding of different scaled values should not be a problem, but an manual programmed adaption of the scaling is necessary (which is done automatically by floating point addition). But each multiplying is a problem. Multiplying of two 16 bit values needs a 32 bit result, and then re-scale.
Using 16 x 16 ⇒ 32 bit multiplication in assembler using the best machine instructions is simple. But this is not supported by C/++. C/++ does not proper support such problems, as also not a fix point overflow. The programmer of this algorithm should know the machine instructions by thinking in C/++ statements.
1.3. Calculation time comparison
If a processor contains a floating point hardware arithmetic, it is optimized. For example a cosf() (float cosinus) needs only 50 ns on a TMS320F28379D processor (and for this family) with 200 MHz clock. In opposite the fix point cosinus variant with interpolation second order (quadratic) with 14 bit accuracy (it is enough) need 400 ns. Because: It needs about 40 machine instructions. The cosf in float is built-in in the hardware and hence fast in about 10 clock cycles. If the interpolation will be supported also in the hardware, it may be fast. But unfortunately it isn’t so.
But, only comparison of single operations (cosf - 50 ns vs. cos16_emC - 400 ns) is not the real truth. Not a standard, but a specific algorithm is always assembled with machine code statements. Though a cosf is faster in float arithmetic as in int16, the whole algorithm may need more time in floating arithmetic. But this depends from the machine instruction, memory access possibilities (32 bit float number versus 16 bit integer), register architecture of the processor, and some other things.
Of course, if a floating point hardware artithmetic is not present, but fix point multiplication, the fix point arithmetic is more fast. This is true for some cheap and power reduces processors. Often a fast assembler-written floating point library is available. It means floating point operation does not need a long time. It is tested for the TLE9879 Infineon processor with 40 MHz clock: 1.5 µs for a cos16_emC(…) 16 bit fix point operation, and 4 µs for the adequate cosf(..) float operations. It means using fix point is a quest of detail.
Some processors don’t have fix point multiplication, for example the MSP430 from Texas Instruments. Such processors are anyway not proper for fast step times (µs). They have libraries for fix point multiplication as well as floating point operations written in assembler. For such processors it is a quest of available memory (Flash and RAM) for a decision between fix and float numeric. The libraries need space in memory.
2. Scaling of fix point numbers
2.1. Simple integer
Fix point numbers can be first integer. This is the simple approach. For example for simple loop counters, or especially for indexing of arrays. Also a multiplication is usual, for more dimensional arrays or adequate things. The numeric range depends on the application, it is limited if the array size (and the memory) is limited. The decision is between 16 or 32 bit integer (or for very large approaches also 64 bit integer, but usual only for the address in a >4GByte memory). An Overflow can be excluded by testing the value ranges before addition or multiplication. An overflow is anyway a problem on addressing memory (using the results as index), and hence by the way prevented.
2.2. Integer numbers with Fractional part
But, it is also possible to use the integer presentation with a decimal point thought by usage. The position of the decimal point in the integer numbers is used in software for converting from or to float or double or from or to textual presentations. The position of the decimal point should also be regarded for ADD and SUB: The decimal point position should be the same. And it is also essential for MULT and DIV: The result should be adjusted in decimal point position. For this some considerations are necessary.
The possibility of overflow is an important topic, it can occur, saturation may be the solution.
Exception on overflow? An exception means, aborting the whole calculation. An exception should be only thrown on unexpected situation, then aborting and an error message is the solution. But this is not and never a good idea for control algorithm. Overflow should be force limitation or just saturation. Also a division by zero is not a reason for exception handling. Division by zero can occur in specific situations, where usual the result is not used by if-statements with several conditions. For floating or double arithmetic there are some presentation of "Not A Number". For fix point arithmetic also a limitation to the max or minimal value is sensible.
Independent of the question of scaling values in computer software, there are two systems to scaling or interpretation of physical values:
-
a) Using nominal values: This is an often used approach, because for controlling the 100% or just 0%..100% are in focus, and not the absolute physical value or capability. A power station may have currently 30% load factor, the other power station or generator also. Both have different nominal values, one 15 MW, the other 2 MW. But this is not in focus, both have 30% load. To image such values in software, especially in fix point arithmetic, there may be two approaches:
-
b) Using physical values. This may be exactly the SI-units, but also derived SI units, for example kA, MW, kV. The derived units are better readable on displays and especially also in debugging situations, if the software handles more with Megawatt than with Watt.
For a) Using nominal values two possibilities of scaling the fix point presentation are sensible:
-
a1) Using a value range from -1.0 till < 1.0 (or more exact 0.99999). This is a very simple format, having the decimal point in the integer presentation after the sign bit. Or just for unsigned values, having only fractional bits in range 0..0.9999. For this approach the nominal value should be never reached, 1.0 and a some times necessary 'overdrive' is not able to present.
-
a2) Using an interpretation as percent value from -128%..+127.999%. For that the highest byte of an int data type is used as integer percent part. The possible range is -128%..127%. If the nominal value of a voltage may be 230 V, it is mapped as 100% in the high byte, presented in debug mode as 0x64, well readable by a software programmer. The maximal presentable voltage is 1.27 * 230 V = 292 V which may be enough or too much on the output plugs. The same consideration for a power. A generator can have 2 kW nominal = 100%, but can feed till 2.5 kW a short time till the fuse comes. This is 125% and fits in range.
The approach b) seems to be generally better for floating point, but it is also able to adapt for fix point. The scaling should be generally determined by the user, or the application. But some things should be determined by the system.
For a system’s determination the approach a1) is proper. For example to calculate with sin and cos, the range is -1.0 .. 1.0. It is a general question how to map this value to fix point numbers, because the fix-point sin and cos should be work proper with it.
Note: in the oder text of this web page some determined values are proposed for the nominal value 1.0. One of them comes from Automation control software, the value 27648 for 100%. This is hexa 0x6c00, well readable for debugging, and also possible divide by 3 and 9 beside divide by 2. But this presentation is not proper using multiplications. See Scaling of values for multiplication and possible overflow
2.3. Angle representation in fix point also recommended for floating point environments
Especially for presentation of angles, for motion control or for electrical control (the reference angle) the integer presentation is much more better than float! Because, the integer wraps around 32767 +1 ⇒ -32768 in an adequate way as the angle rotates from -180° + 0.001 = +179.999°-. Here the overflow is desired, it is not an overflow, it is an surround incremented angle. To convert such an angle value from a given float (result of atan2(…) etc), you should only calculate:
#define angle16_rad_emC(RAD) (int16)((RAD) * (32768.0f/PI_float_emC) ) #define angle32_rad_emC(RAD) (int32)((RAD) * ((65536.0f*32768.0f)/PI_float_emC) )
and back again:
#define radf_angle16_emC(ANGLE16) ((ANGLE16)* (PI_float_emC / 0x8000)) #define radf_angle32_emC(ANGLE16) ((ANGLE32)* (PI_float_emC / 0x80000000))
Using only fix point arithmetic the atan2 and the other trigonometric functions should have immediately int32 using for the angle.
In opposite, for an angle presentation in float or double, it is anyway effort to adjust the angle if it increments over the PI value or the -PI value, and also to get angle differences between angles surround 180°.
Note: Use usual an int32 representation of the angle, and not a, int16, because the angle growth difference
for a reference angle or movement should have a proper resolution. For 50 µs step time and 50 Hz as grid frequency
for int16 you have only 32768 * 0.050 ms / 10 ms =~ 163 as growth in one step time. This is too non exact.
The angle presentation is very simple. An angle between 0° and 360°, or better between -180° .. 0° .. 179.9999° can be represented with the full integer range:
-180° |
- PI |
0x80000000 |
-120° |
-2/3*PI |
0xaaaaaaab |
-90° |
- PI/2 |
0xc0000000 |
-60° |
- PI/3 |
0xd5555555 |
-30° |
- PI/6 |
0xeaaaaaab |
0° |
0 |
0x00000000 |
30° |
PI / 6 |
0x15555555 |
60° |
PI / 3 |
0x2aaaaaab |
90° |
PI / 2 |
0x40000000 |
120° |
2/3*PI |
0x55555555 |
+179.99999992° |
+0.9999999995* PI |
0x7FFFFFFF |
There is a very important advantage: The angle is full defined in a 360° circle. The difference (-181° - 179°) is as expected simple 2°. It is because integer arithmetic has no overflow handling. The values are closed between 0x7fff..0x8000. For example if a T1-FBlock (smoothing block) is necessary and the angle varies in range around 180°, no problem. For float representation it is a concise problem: Always overflow > PI and < -PI should be handled.
Hence it is better to use this angle representation also for floating point environments, with a simple conversion:
#define angle16_degree_emC(GR) (int16)(((GR)/90.0f) * 0x4000) #define angle16_rad_emC(RAD) (int16)((RAD) * (32768.0f/PI_float_emC) ) #define radf_angle16_emC(ANGLE16) ((ANGLE16)* (PI_float_emC / 0x8000)) #define gradf_angle16_emC(ANGLE16) ((ANGLE16)* (180.0f / 0x8000))
Calculation angle values, especially differences should be done using integer arithmetic. Before using the angle value as float, the simple multiplication above should be done.
3. Overflow and Saturation arithmetic
3.1. When an overflow can occur
Quite simply, when a sum of values leaves the representable value range. Or also when a multiply leaf the value range, whereby in this case it is an effect of shift left the result after multiply.
This is, if you have a range from -2m … 2 m measurement in mm present in an int32 with 1 bit sign, 11 bit pre-fractional bits, and the rest fractional bits. This may be also the range where a real existing movement is possible, the digital twin image is for simulation or for model calculation. What happens if a motor drives a spindle and the carriage on the spindle axis reaches the end point of movement range. Then the movement stops, the current in the motor goes high because the motor blocks. This situation should be detected by position switches, and a special handling (usual a state machine) should control the situation, so that the blocking end position should be never reached. Adequate it is in simulation, for the digital twin. But if the software is not ready, maybe, the end position is hardly reached. The simulated motor does not get hot, because it has not a temperature simulation .-). Now it is important that the end position is also limited as in real physics, and does not get any overflow.
Similar it is for a control algorithm where the control error is great. Then also a analog controller or a physical control mechanism goes in to the limitation value. If the temperature in a room is yet not enough warm, the heater has its maximum of power, and the room gets more and more warm.
The Ariane 5 rocket crashs in ~1997, because of an overflow in the arithmetic. The story is, the software was ready, the overflow was never reached in the test and practical situations, with the Ariana 3, 4. But the the Ariane 5 gets an higher speed, and because the occurring overflow, faulty signal are produced, which led the rocket to a fatal change of course.
The standard machine code statements of most of processors calculates integer arithmetic primary without overflow handling, but sets flags on overflow. This behavior was known as well as on the Z80 processor (Zilog) with the CY flag for unsigned overflow and the OV flag for signed overflow:
ADD 0x7FFE, 0x0002 => 0x8000, set OV flag ADD 0x7FFE, 0xFFFE => 0x7FFC, set CY flag, non setting OV flag.
With the flags it is simple to correct an overflowed result, in assembly language.
I don’t know what was realized in the Arithmetic Units of the Mini Computers in the 1960th. Maybe similar stuff, maybe very different in the different machines.
In C language this problem was unnoted. Using the flags was firstly not and then never in the brain of C language developers. Maybe, supposed, because of incompatible, not standardized flag handling in the Arithmetic Units. Maybe, the reason is, C was primary not used for control algorithm, more for job processing of the computer in the 1960th.
I guess, only first after crash of the Ariane 5, thinking of automatic overflow handling with limitation or saturation was first in the brains of processor chip development. Firstly the ARM processor technology and then also some other processors introduced so names saturation operations. This operations delivers an non overflowed result additional to the setting of an overflow flag. This result is anyway proper usable, without extra handling.
But this special statements are not available or not able to map to ordinary C language. They are proper usable in specialized assembler code.
The next considerations offers Macros for C (C++) which can be general adapted with specific asm statements for specific processors.
This adaption should be done in a specific compl_adaption.h (see ../Base/compl_adaption_h.html)
or just a specific header for this definitions called from the compl_adaption.h.
3.2. Saturation instructions in several processors
See for example
-
https://www.analog.com/media/en/dsp-documentation/processor-manuals/SC58x-2158x-prm.pdf, search to "saturation".
-
https://developer.arm.com/documentation/dui0553/b: Cortex ™ -M4 Devices
-
https://www.emmtrix.com/wiki/TriCore_Instruction_Set_Architecture: Infineon Tricore serie (Aurix)
-
https://www.infineon.com/dgdl/Infineon-AURIX_TC3xx_Architecture_vol2-UserManual-v01_00-EN.pdf
-
or better: https://www.infineon.com/dgdl/Infineon-AURIX_TC3xx_Architecture_vol2-UserManual-v01_00-EN.pdf?fileId=5546d46276fb756a01771bc4a6d73b70 Generic User Guide, chapter 3.7 Saturation Instructions
This operations are different for some processors but similar. But in C/++ language they are still not regarded as standard. Some different approaches are in use.
3.2.1. ARM
See https://developer.arm.com/documentation/ddi0487/latest/ gotten on 2025-04-28 of on https://developer.arm.com/documentation/dui0552/a/the-cortex-m3-instruction-set/saturating-instructions/ssat-and-usat?lang=en
The following text is copied from this link above:
Copyright 2013-2024 Arm Limited or its affiliates. All rights reserved. Non-Confidential F2.4.4 Saturating instructions Table F2-7 lists the saturating instructions in the T32 and A32 instruction sets. For more information, see Pseudocode description of saturation. Table F2-7 Saturating instructions
| Instruction | See | Operation |
|---|---|---|
Signed Saturate |
SSAT |
Saturates optionally shifted 32-bit value to selected range |
Signed Saturate 16 |
SSAT16 |
Saturates two 16-bit values to selected range |
Unsigned Saturate |
USAT |
Saturates optionally shifted 32-bit value to selected range |
Unsigned Saturate 16 |
USAT16 |
Saturates two 16-bit values to selected range |
F2.4.5 Saturating addition and subtraction instructions Table F2-8 lists the saturating addition and subtraction instructions in the T32 and A32 instruction sets. For more information, see Pseudocode description of saturation. Table F2-8 Saturating addition and subtraction instructions
| Instruction | See | Operation |
|---|---|---|
Saturating Add |
QADD |
Add, saturating result to the 32-bit signed integer range |
Saturating Subtract |
QSUB |
Subtract, saturating result to the 32-bit signed integer range |
Saturating Double and Add |
QADD |
Doubles one value and adds a second value, saturating the doubling and the addition to the 32-bit signed integer range |
There are some more specific operations for saturation, see ARM docu.
The saturation instructions SSAT and also USAT have the following signature:
SSAT[cond] Rd, #n, ,Rm [, LSL #s | , ASR #s|]
Rd is the destination register, Rm is the source register.
The shift operatios either LSL, Logical Shift Left or ASR Arithmetic Shift Right are optional.
The Logical Shift is intrinsic also an arithmetic shift, especially if the sign is used to saturate.
The values for #n and #s must be constants, cannot provide from a register.
The only one non reentrant possibility to use volatile values is, hold the machine instruction in RAM
and modify immediately the bits in the machine instruction. But this approach is not usual.
It is possible not only saturate to 0x7fffffff and 0x80000000 but also for example to 0x03ffffff and 0xfc000000
with #n=27. #n is the number of bits to use for the saturated result inclusively the sign for SSAT
and the number of positive value bits for USAT located in the low part of Rd.
SSAT sets the excluded high bits equal to the sign, USAT sets them to 0 and sets all other bits to 1 on saturation.
USAT is not the saturation for an unsigned value as maybe expected. The Docu of ARM says:
"USAT (Unsigned Saturate) saturates a signed value to an unsigned range."
It means, if the value in Rm is negative (MSB is 1), then it saturates to the value of 0x00000000.
#n = 32 for SSAT means use the full width of the Rd destination register, does no saturation.
#n = 32 for USAT it not admissible, #n = 31 for USAT saturates to range 0x00000000..0x7FFFFFFF,
whereby negative values in Rm results in 0x00000000 as result.
#n = 16 saturates to 16 bit both for SSAT with sign in the range 0xFFFF8000..0..0x00007FFF
and USAT as positive value in range 0x00000000..0x0000FFFF.
#n = 1 for SSAT produces the sign bit in bit0 of Rd. For USAT, It sets bit0 to 0 on 0 or negative values.
#n = 0 for USAT sets the destination register Rd to 0. For SSAT it is not admissible.
Some test examples:
USAT Rd, #0, Rm
results always in the value 0, because the value can have only 0 bits.
USAT Rs, #20, Rm with Rm = 0x00123456
results in 0x000FFFFF because the number value has only 20 bits, hence saturated.
USAT Rs, #31, Rm with Rm = 0x76543210
results in 0x76543219 because the value has 31 bits, hence not saturated. But:
USAT Rs, #31, Rm with Rm = 0x86543210
results in 0x00000000, it seems to be that 0x8…….. is interpreted as negative, hence saturated to 0.
It means the USAT is not for unsigned values to saturate. It is for an positive saturate of signed values.
This is tested with µVision AC6 compiler -mcpu=cortex-m3 with simulated TL9879QXA40 controller (Infineon).
This is for specific assembly operations, not used for emC. Only the standard values to saturate are used.
The possibility to shift is also optional. But using the n value it is possible to saturate before shift.
The SSAT16 and USAT16 works with two 16 bit halfwords at the same time.
QADD[cond] Rd Rn Rm
This is the 32 bit addition Rd = Rm + Rn with saturation to 0x7fffffff or 0x80000000.
If saturation occurs, the Q flag is set. The Q-flag is only reset with a MSR instruction,
and not reset with the next operation which does not saturate. It means it can be tested after some operations
which may cause saturation, and the reset with MSR.
3.2.2. Texas Instruments TMS320C28xx series
See https://www.ti.com/lit/ug/spru430f/spru430f.pdf: TMS320C28x CPU and Instruction Set
This processor has a SAT and SAT64 instruction which sets the accumulator to the saturation value
after an ADD, SUB instructions if this instructions has increment or decrement the overflow counter.
But unfortunately the shift left operation is not in focus of automated saturation handling.
It is interesting that an overflow handling can be done also only after some ADD or SUB instructions.
If a positive overflow occurs, the OVF counter is incremented. If after them a negative overflow occurs,
then this counter is decremented, reaches again 0, and the overflow situation is proper: no overflow:
0x7fff + 0x0002 + 0xfffd => 0x7fffe adequate 0x7fff + 2 - 3
It is not overflowed on end. The first operation causes the positive overflow, the second operation heal up the overflow situation.
3.2.3. Infineon Tricore
See https://www.emmtrix.com/wiki/TriCore_Instruction_Set_Architecture or also https://www.infineon.com/dgdl/Infineon-AURIX_TC3xx_Architecture_vol2-UserManual-v01_00-EN.pdf * or better: https://www.infineon.com/dgdl/Infineon-AURIX_TC3xx_Architecture_vol2-UserManual-v01_00-EN.pdf?fileId=5546d46276fb756a01771bc4a6d73b70
This instruction set has a arithmetic shift:
SHAS Dc Da #n SHAS Dc Da Db
This shifts left or right by the given number of bits #n or the content in Db bits 5..0.
Left shift may cause a saturation, sets then the V bit (Overflow).
But this bits are reset after the next instruction without overflow.
ADDS Dc, Da, #n ADDS Dc, Da, Db ADDS Da, Db
The left register is the destination. The ADDS Da, Db does Da += Db with saturation.
As the SHAS the V register is set on saturation or just reset if no saturation occurs.
There are of course also SUBS and some more saturation instructions.
3.3. Macros for calling saturation arithmetic for C language
In emC/Base/Math_emC.h there are defined some macros which can be adapted to proper assembly instructions,
especially for the different processor instruction sets for this saturating operations.
The standard implementation is defined in C language, proper but not full optimized for all processors.
Of course, this macros can be used for the typical use cases. They cannot be mapped to all possibilities of the instruction set, they may be too many cases. It may therefore also be necessary to write certain sequences in assembler code.
adds16sat_emC(R, A, B) 16 bit signed saturation add addu16sat_emC(R, A, B) 16 bit unsigned saturation add subu16sat_emC(R, A, B) 16 bit unsigned saturation sub adds32sat_emC(R, A, B) 32 bit signed saturation add addu32sat_emC(R, A, B) 32 bit unsigned saturation add subu32sat_emC(R, A, B) 32 bit unsigned saturation sub
shL16sat_emC(R, A, SH) 16 bit shift left with saturation for overflow preventing
shL32sat_emC(R, A, SH) 32 bit shift left with saturation for overflow preventing
sh15L32sat_emC(R, A, SH) 32 bit shift left with saturation, max 15 time to left (lesser register effort)
sh15L32satMask_emC(R, A, SH, MASK) 16 bit shift left with saturation,
max 15 time to left (lesser register effort), with given mask
The shift operations are specific usable for multiplication operations, see Signed or unsigned, 16 or 32 bit multiplication:
mpyadd16sat_emC(R, P, F) 16 bit multiply and incremental add. mpyadd32sat_emC(R, P, F) 16 bit multiply and incremental add.
The signed subtraction can anyway performed by using the negated value with signed add, though the ARM has also a signed saturation subtract.
Some more instructions, sometimes necessary, regard some especially assembly instructions of the ARM, maybe similar also in other processors:
add2s16sat_emC(R1, R2, A1, A2, B1, B2) 16 bit signed add with two values add2u16sat_emC(R1, R2, A1, A2, B1, B2) 16 bit unsigned add with two values sub2u16sat_emC(R1, R2, A1, A2, B1, B2) 16 bit unsigned sub with two values
This instructions which handles two operation with one assembly instruction may be necessary especially for 16 bit integer operations. The 8 bit saturation operations are not (yet) supported by macros. This operations are familiar for color calculations, not the focus of embedded algorithm. They can be created if necessary.
This macros are defined in C language in a common proper way in emC/Base/Math_emC.h.
For a specific processor this macros can be defined especially using the __asm(…) definition in the compl_adaption.h.
Because of #ifdef adds16Sat_emC etc. is tested, this specific definitions of the macros in compl_adaption.h are used.
Using this macros enables optimized usage of machine instructions though it is programmed in C/++.
3.4. Macros to detect a saturation
On ARM processor the saturation operations set the Q flag if a saturation occurs, and let it unchanged elsewhere.
The usage of this should due to the following pattern:
-
Reset Q flag
-
Do some operations, which may cause saturation
-
Test Q flag to detect whether the whole algorithm has saturated anywhere.
On saturation a warning or such can be noted. The saturated result is able to use, this is the approach of saturating arithmetic. Evaluating the Q flag is only for additional information.
But this additional information may be necessary. Hence the macros for saturation arithmetic in C language regard this too.
It is necessary to write the following macro in a statement block which uses the saturating macros:
DEFsatCheck_emC
To check whether saturation has occurred, it can be tested:
if(satCheck_emC()) { .....
clearSatCheck_emC(); //to clear the flag.
The usage of this flags are optional, if necessary. If this macros are not used,
the effort for the boolean variable in DEFsatCheck_emC is removed by optimizing compilation.
If this macros are adapted to a specific machine set (in compl_adaption.h), for the ARM processor it should check and clear the Q flag.
4. Signed or unsigned, 16 or 32 bit multiplication
Generally the multiplication of two 16 bit values results in 32 bit. The multiplication of two 32 bit values results in 64 bit. This is given by bit-mathematical correlations.
4.1. Specific machine code instructions for multiplication in several processors
Some middle powerful processors support multiplication in hardware and have this operation. For example for the ARM series which is the base of many processor architectures, there are multiply instructions
See https://developer.arm.com/documentation/ddi0487/latest/ gotten on 2025-04-28
The following text is copied from this link above:
Copyright 2013-2024 Arm Limited or its affiliates. All rights reserved. Non-Confidential
F2.4.3 Multiply instructions
These instructions can operate on signed or unsigned quantities. In some types of operation, the results are the same whether the operands are signed or unsigned.
-
Table F2-4 summarizes the multiply instructions where there is no distinction between signed and unsigned quantities. The least significant 32 bits of the result are used. More significant bits are discarded.
-
Table F2-5 summarizes the signed multiply instructions.
-
Table F2-6 summarizes the unsigned multiply instructions.
Table F2-4 General multiply instructions
| Instruction | See | Operation (number of bits) |
|---|---|---|
Multiply Accumulate |
MLA, MLAS |
32 = 32 + 32 32 |
Multiply and Subtract |
MLS |
32 = 32 - 32 32 |
Multiply |
MUL, MULS |
32 = 32 32 |
Table F2-5 Signed multiply instructions
| Instruction | See | Operation (number of bits) |
|---|---|---|
Signed Multiply Accumulate (halfwords) |
SMLABB, SMLABT, SMLATB, SMLATT |
32 = 32 + 16 16 |
Signed Multiply Accumulate Dual |
SMLAD, SMLADX |
32 = 32 + 16 16 + 16 16 |
Signed Multiply Accumulate Long |
SMLAL, SMLALS |
64 = 64 + 32 32 |
Signed Multiply Accumulate Long (halfwords) |
SMLALBB, SMLALBT, SMLALTB, SMLALTT |
64 = 64 + 16 16 |
Signed Multiply Accumulate Long Dual |
SMLALD, SMLALDX |
64 = 64 + 16 16 + 16 16 |
Signed Multiply Accumulate (word by halfword) |
SMLAWB, SMLAWT |
32 = 32 + 32 16 a |
Signed Multiply Subtract Dual |
SMLSD, SMLSDX |
32 = 32 + 16 16 - 16 16 |
Signed Multiply Subtract Long Dual |
SMLSLD, SMLSLDX |
64 = 64 + 16 16 - 16 16 |
Signed Most Significant Word Multiply Accumulate |
SMMLA, SMMLAR |
32 = 32 + 32 32 b |
Signed Most Significant Word Multiply Subtract |
SMMLS, SMMLSR |
32 = 32 - 32 32 b |
Signed Most Significant Word Multiply |
SMMUL, SMMULR |
32 = 32 32 b |
Signed Dual Multiply Add |
SMUAD, SMUADX |
32 = 16 16 + 16 16 |
Signed Multiply (halfwords) |
SMULBB, SMULBT, SMULTB, SMULTT |
32 = 16 16 |
Signed Multiply Long |
SMULL, SMULLS |
64 = 32 32 |
Signed Multiply (word by halfword) |
SMULWB, SMULWT |
32 = 32 16 a |
Signed Dual Multiply Subtract |
SMUSD, SMUSDX |
32 = 16 16 - 16 16 |
a. The most significant 32 bits of the 48-bit product are used. Less significant bits are discarded. b. The most significant 32 bits of the 64-bit product are used. Less significant bits are discarded.
Table F2-6 Unsigned multiply instructions
| Instruction | See | Operation (number of bits) |
|---|---|---|
Unsigned Multiply Accumulate Accumulate Long |
UMAAL |
64 = 32 + 32 + 32 32 |
Unsigned Multiply Accumulate Long |
UMLAL, UMLALS |
64 = 64 + 32 32 |
Unsigned Multiply Long |
UMULL, UMULLS |
64 = 32 32 |
-
end of citation
Similar it is for example for Texas Instruments series C2800, source of the next lines is:
https://www.ti.com/lit/ug/spru430f/spru430f.pdf: TMS320C28x CPU and Instruction Set
-
MPY 16 X 16 Multiply (to 32 bit result)
-
MPYA 16 X 16-Bit Multiply and Add Previous Product.
-
MPYB Multiply Signed Value by Unsigned 8-bit Constant
-
MPYS 16 X 16-bit Multiply and Subtract
-
MPYU 16 X 16-bit Unsigned Multiply
-
MPYXU Multiply Signed Value by Unsigned Value
-
QMACL Signed 32 X 32-bit Multiply and Accumulate (Upper Half)
-
QMPYL Signed 32 X 32-bit Multiply (Upper Half)
-
QMPYSL Signed 32-bit Multiply (Upper Half) and Subtract Previous P
-
QMPYUL Unsigned 32 X 32-bit Multiply (Upper Half)
-
QMPYXUL Signed X Unsigned 32-bit Multiply (Upper Half)
-
SPM This instruction clarifies a bit shift after multiply.
Low cost and low power consumption processors haven’t hardware multiplication, instead specific operations in the C libraries are used, immediately supported by the compiler and often written in assembly language. Usual algorithm on such processors run in a slow calculation time (seconds for temperature control or such). For fast calculation time it should be considered whether it is more practicable to multiply only with a power of two, because this is a simple shift operation.
But programming in C/++ language don’t regard this relationships. As also for add/sub arithmetic the width of the operands and the result are the same. Maybe some given libraries for C or C++ do it better, but special libraries maybe written in assembler for a special processor are not a contribution to an "embedded multi platform" C/++ programming style, they are not commonly useable.
For example to support a 16 * 16 ⇒ 32 bit multiplication inside Texas instruments processor it should be written, originally copied from: https://www.ti.com/lit/an/spra683/spra683.pdf.
INT32 res = (INT32)(INT16)src1 * (INT32)(INT16)src2;
But this is a special writing style from Texas Instruments for its compiler, it may not be a hint for all processors.
See also https://www.ti.com/lit/an/slaa329a/slaa329a.pdf: Efficient Multiplication and Division Using MSP430™ MCUs
There seems to be the situation that effective machine code is only possible to use assembly language, or very specific compiler and a proper language syntax. Or - alternatively - using ready to use libraries for that and that from the vendors. But these approaches go away from general approach to solve problems, in C(++) commonly use language, or in other common languages, or in graphic programming with common (not vendor-specific) approaches.
But on the other hand, detection and optimization is done by the target processor specific compilers. If you want to have only a 16 bit result from the higher part of the 32 bit multiplication result, you can write in C language:
int16 res = (int16)((int32)(int16)(X1) * (int32)(int16)(X2)) >>16);
The compiler uses the machine code instruction for mpy 16 x 16 ⇒ 32, detects the >>16
and uses only the high word.
or for the Texas Instrument TMS320C28xx compiler:
int32 res = (int32)((int64)(int32)(X1) * (int64)(int32)(X2)) >>32);
But this is not guaranteed, depends from some options and may need manual check of the assembler file result. That’s why some macros are defined in the emC environment which can be written specified for the processor to use the optimal statements. One time adapted the macros - always usable for common approach programming. The standard implementation of this macros uses the above shown casts and operations on C level, which may be also produce a proper result.
Because of this macros should be able to adapt to asm statements in C language, it is not possible to write it as a part of a inline expression. Instead the form is always as extra statement:
4.2. Macros for multiplication, simple readable and possible for adaption
There are also some "add and multiply" instructions, and some instructions to detect overflow. Reading some manuals of processors, it seems to be adequate to program such parts in assembler. The link: https://www.quora.com/How-much-could-we-optimize-a-program-by-writing-it-in-assembly discuss some of good or bad reason to program in assembler, see there the contribution from Hanno Behrens: "Do people still write assembly language?".
From position of producers of tool or processor support, it is appropriate to deliver some libraries for expensive mathematical and control algorithm (including PID-control with some precaution of integral windup and such things). The application programmer can use it, no necessary for own mathematics. But this approach obliges a user to the one time selected hardware platform. The programs are not portable. There is no standard (for C/++) to unify such libraries.
The C/++ language allows constructs to implement specific assembly instructions. That is an advantage of C language. In this kind specific macros or inline functions can be defined as interface, which can be simple implement by inline-assembly statements or macros with specific castings (one time written) for any processor, respectively a standard implementation with C-code exists, which may be enough fast for first usage.
The emC concept is predestinated to support such ones, because it is "embedded multi platform C/++". Hence it do so.
The following operations (may be specifically implement as macro or inline in the compl_adaption.h) are defined and pre-implemented in C (emC/Base/types_def_common.h):
void muls16_emC(int32 r, int16 a, int16 b); //16 bit both signed, result 32 bit void mulu16_emC(uint32 r, uint16 a, uint16 b); //16 bit both unsigned, result 32 bit void mul32lo_emC(int32 r, int32 a, int32 b); //32 to 32 bit result lo 32 bit void muls32hi_emC(int32r, int32 a, uint32 b); //32 to 32 bit signed, result hi 32 bit void mulu32hi_emC(uint32 r, uint32 a, uint32 b);//32 to 32 bit usigned, result hi 32 bit void muls32_64_emC(int64 r, int32 a, int32 b); //32 to 64 bit signed void mulu32_64_emC(uint64 r, uint32 a, uint32 b); //32 to 64 bit unsigned
Additional there are some more instructions which supports the "mult and add" approach.
void muls16add32_emC(int32 r, int16 a, int16 b); void mulu16add32_emC(uint32 r, uint16 a, uint16 b); void mul32addlo_emC(int32 r, int32 a, int32 b); void muls32addhi_emC(int32 r, int32 a, uint32 b); void mulu32addhi_emC(uint32 r, uint32 a, uint32 b); void muls32add64_emC(int64 r, int32 a, uint32 b); void mulu32add64_emC(uint64 r, uint32 a, uint32 b);
This operations cannot be a part of an expression, they are in form of statements. For that it is sometime more simple to build proper macros or assembly expressions.
TODO using inline operations in C/++ allows using inline expressions. It is tested, but not full qualified.
Why a signed or unsigned distinction is not necessary for the mul32lo_emC? Because:
The lo part of a multiplication is the same independent of the sign of the inputs.
This is adequately similar also for a mul*16_emC.
The essential thing is: The inputs should be exactly enhanced to its 32 bit form,
then multiplicate 32 * 32 bit, and use the lower result. But: That is more effort.
The multiplication 16*16 bit to 32 bit needs lesser time and hardware resources.
Only the sign should be automatically correct expanded.
That’s why usual embedded processors have often machine instructions for multiplications:
-
16-bit signed, result 32 bit
-
16 bit unsigned, result 32 bit
-
32 bit, presenting the lower part
-
32 bit signed and unsigned, presenting the higher part
That are the same as the mul*_emC instructions above. That are the usual necessary ones.
4.3. Scaling of values for multiplication and possible overflow
If you use multiplication for less numbers, for example indices of a 2- or more dimensional array,
then this are integers. if the index range is less [0..299][0..3][0..1] then such operations don’t cause an overflow.
it may be important that the range of input values are checked before.
But this is anyway necessary to prevent faulty memory access (index out of bounds preventing).
Only think about whether a 32-bit result is able to expect.
Multiplying two factors and using the high part of result (16 x 16 bit multiplied to a 32 bit result and using the high 16 bit of this result, or the same just for 32 x 32 bit to 64 bit result and using the high 32 bit) does primary never cause an overflow. More as that, if you multiply signed values, you can shift the result one time to left, without overflow:
For example 0.9999 * 0.9999 result in ~ 0.9998, as register values in hexa
this is 0x7fff * 0x7fff ⇒ 0x3fff0001 using 16 X 16 ⇒ 32 bit multiply, using the high word,
and shift the high word one bit to left results in 0x7ffe which is the proper result in sufficient accuracy.
The same done for 32 bit using a 32 bit multiplication with result to the upper 32 bit word,
for the TI c28.. series this is QMPYL, for ARM this is SMMUL,
0x7fffffff * 0x7fffffff ⇒ 0x3fffffff shifted 1 left is 0x7ffffffe
But multiplication of -1.0 * -1.0 force an overflow, because the result 1.0 is not able to present:
0x8000 * 0x8000 ⇒ 0x40000000 shifted 1 left and used the upper 16 bit is 0x8000.
Multiplication with a positive value without sign, with decimal point left from all bits,
means 0.9999 is presented by 0xffff does never force an overflow and does not need shifting.
Multiplication with a positive or negative value between -0.9999 till 0.9999,
with the decimal point after the sign, means with 15 or 31 fractional bits needs a shift of 1 to left,
which does never produce an overflow. Do not use the possible value -1.000. Exclude it before.
Hence, for multiplication of values with any decimal point with a second value which is scaled to max. 0.999 is the simplest and fastest kind of multiplication. This may be regard in writing software. Often a value should be multiplied with another value which is significant less than 1, especially in control algorithm as growth for an integral. Using an 32 bit value which can map a factor of 2.3*10-9 with 0.01 solution, or just 16 bit which can map 0.00003 may be a better idea than making a more complex solution with shift.
If both of the factors have its decimal point on any position, the following situations can occur. But first let us see an example for this scaling:
If you have a voltage in fix point presentation which does never overruns 1000 V, for example in a converter for the 230 V grid, there are at max ~650 V internal "direct current link voltage", then you can map this values to 10 bit + sign + 5 bit after decimal point (S11.5). But if you want to proper read voltages also in debug mode, you may use 12 bit (3 hexa digits) for sign and integer part, and only 4 bit for the decimal part with a resolution of the voltage less than 100 mV (S12.4). If the current is always less than 100 A (in maximum), you may use sign + 7 bit (1 Byte) for the integer part, with a resolution of 1/256 A (4 mA) (S8.8). If you want to calculate the power with this both values, without overflow, multiplying both values and use the high part shift 1 to left, then you get a max 255 kW with a resolution of 8 W, because the Last Significant Bit is 8 W. But your power station may have a maximal power of only less than 10 kW. Or as time value at last 20 kW. It means scaling to 32 kW or more exact 32767 W = 0x7fff is the better choice. It means you need to shift the result not one but 4 times to left. Example calculation:
230 V * 10 A => 2300 W 0x0e60 * 0x0a00 => 0x008fc000 <<4, use hi part => 0x08fc
How many shift to left? If you want to have the same unit as the first factor, you must shift adequate the number of integer part bits of the second factor. For this example to scale to 2000 W adequate 2000 V, you should shift left 8, because the current has 8 integer bits with the sign bit. This consideration is sensible if you multiply the same unit with a simple factor. But here the power is another unit with another scaling. The best possibility is: make an example calculation. Or also: Add the number of integer part bits to get the information how many integer bit should have the result, here 12 + 8 = 20 integer bits. That is the simple machine code multiply consideration. Then subtract the number of desired integer bits, here 16 to scale +-32767 W, this is 4 to shift left.
But now you can have the overflow problem. If you have a short current situation and the measurement current is in peak 101 A, this is 0x6500 for the current, and the ordinary voltage is in peak 325 V =^ 0x1450, the raw multiply result is 0x08039000. If you shift it 4 to left and get the high part, it is 0x8039. This is a negative power of (-32.711 kW) which may decrement an integral value instead increment and prevent the over power detection. This is a similar situation as for the Ariane 5 crash, but you have only a fire in your house. But fortunately you have also some fuses (simple electrical) in your circuits.
That’s why the sift left must have an overflow detection and automatic saturation. Then you get the greatest positive value of 0x7fff which switches of your device for a short time.
Pre-Fractional parts and overflow problems
Problems with overflow occurs if the interpretation of the integer bit pattern includes a pre-fractional part.
For example to map a value for a voltage in range till max 1000 V, it is sensible to set the decimal point
after the bit 5 in an int16 representation. For that the voltage has a resolution of 1/32 or 0.03 Volt.
Or better use only 4 bit fractional, because the value is readable and interpretable also while debugging
as hexa value, 0x0e60 are 230 V, 0xe6 = 230. 0x100 is 256 that is commonly known.
If such an voltage as difference is multiplied with a factor in range ~10.0 to build a controller error for any control, and the differences are in range (0..50 V), multiplying is ok. If the difference is higher, because of special situations, for example start up, load a capacitor, which has 0 as initial value, the controller should go in limitation to load the capacitor so fast as possible, but not too fast. That is controlling as usual. The difference 230.0V * 10.0 is not able to present, the multiplication forces an overflow.
How does a multiplication with different fractional and integer parts are done? Remain the example. The voltage has 12.4 bit, whereby the highest bit is the sign. The used proportional part gain may have a range till max. ~50, but not a too high necessary resolution in fractional parts. So the decision is: Use 8.8 bit, also possible as negative gain, means in range -128..127.994 with steps of 0.004. Then the formally multiplication is done:
230.0 * 10.0 = 2300.0 0x0e6.0 * 0x0a.00 = 0x008fC.000
The result has the decimal point on 20.12 because (12 + 8) . (4 + 8) bits of the components.
The number 0x8fc is the 2300.
To get the value in 16 bit with the same 12.4 bits you should shift the result 8 to left.
That is the number of integer (pre-fractional) bits of the second multiplier.
This shifting results in 0x8fC0 which is a negative number. We have an overflow.
To detect the overflow it should be tested before shifting, whether all bits which are shifted out
and the highest bit of the result (position for the sign) have the same value, either all 1 or all 0.
All 1 is a valid negative result.
Here the mask to test should be 0xff800000 and not all bits are 0 with this mask.
It’s an overflow.
What about if one argument is negative:
-230.0 * 10.0 = -2300.0 0xf1a.0 * 0x0a.00 = 0xff704.000
Here also 0xff704000 & 0xff800000 results in 0xff00000 where not all bits are the same,
or otherwise tested ~0xff704000 & 0xff800000 =^ 0x008fbfff & 0xff800000 ⇒ 0x00800000 which is not 0.
On overflow the operation result should not be used (test the situation, throw an exception) or it should be set to the greatest or just negative greatest possible presentable value (saturation, limitation). The decision to throw an exception is usual worse in an environment where a controller algorithm is calculated, because it is not an except situation, it is a normal limitation situation. But see discussion about saturation also for Add and SUB in Overflow and Saturation arithmetic and especially Macros to detect a saturation
Here is the complete algorithm for Multiply 16 x 16 ⇒ 16 bit with flexible position of the decimal point (number of fractional bits) and saturation:
//#define mpySSS_emC
#define MPYSSS_emC( Y, X1, X2, F1, F2, FR) {\
int32 y32; muls16_emC(y32, X1, X2); \
int sh = 16 - (F2) + (FR) - (F1); \
int16 _y_; \
if(sh == 1) { \
_y_ = (int16)( y32 >> 15); \
} else if(sh <= 0) { \
_y_ = (int16)(y32 >> (-sh + 16)); \
} else { \
int32 y2; sh15L32sat_emC(y2, y32, sh); \
_y_ = (int16)(y2 >>16); \
} \
Y= _y_; \
}
extern_C int16 mpySSS_emC ( int16 x1, int16 x2, int f1, int f2, int fr); //, int m1, int m2);
INLINE_emC
int16 mpySSS_emC ( int16 x1, int16 x2, int f1, int f2, int fr) {
// // but then also an saturation cannot be detected.
int32 y32; //--------vv first calculate a 32 bit result, formally with inputs
muls16_emC(y32, x1, x2); // Use the macro can be optimized for special processors.
int sh = 16 - f2 + fr - f1; // this is shift the result to left. It is 1 for 15 fractional bits.
int16 y;
if(sh == 1) { //--------vv typical case for left side decimal point, 15 fractional bits.
y = (int16)( y32 >>15); // there is never an overflow, use result bits 30..15
} else if(sh <= 0) { //--------vv the result as equal or more pre-fractional bits space.
y = (int16)(y32 >> (-sh + 16)); // shift to right, use the high bits shifted.
} else { //--------vv shift to left maybe detect saturation,
GET_ThreadContext_emC(); // used for notice overflow, macro is empty if there is no ThreadContext.
int32 y2;
sh15L32sat_emC(y2, y32, sh); // because result has lesser pre-fractional bits as both inputs.
y = (int16)(y2 >>16); // access the high part of int32 as 16 bit register access.
}
return y;
} The core operation is the 16 X 16 = 32 bit multiplication. This is written as macro to optimize it for special CPUs. The number of necessary shift of the result (to left or to right) depends on the desired position of the decimal points. It is
4.4. How to use 32 bit multiplication to lower 32 bit, overflow problem
A multiplication operation 32 * 32 bit to 32 bit lower part is often offered as machine code instruction.
Generally the 32*32 bit multiplication using the lower 32 bit result may have an overflow problem. Then the result is not usable. But:
If the sum of the relevant input bits does not exceed 32, then the result is correct.
In contrast to the 16*16 bit multiplication, it is possible for example to use 24 bit resolution of a signed number for one factor,
multiplied with a factor which needs only 8 bit.
That can be a gain from 0..15 with resolution 1/16 or for the user: 0.1.
It is fine enough for some applications. The gain is scaled 1.0 =^ 0x10.
Example multiply -1.5 * 1.0667, the scaling of the first factor is 1.0 ^= 0x00'400000,
which allows a 24-bit-range -2 .. +1.999, but before multiplication a limitation may be done to prevent overflow. -1.5 ^= 0xFF’A00000
0xFFA00000 * 0x00000011 => 0x10'F9A00000
It is important that the both 32 bit factors are exactly expanded with the sign.
It means the 24 bit value 0xA00000 (negative) is expanded to 0xffA00000 and the 0x11 (positive) is expanded to 0x00000011.
The result is correct if the sign of the factors are correctly expanded.
A difference between signed and unsigned multiplication is not done.
The resulting value is 0xF9A00000, the higher part 0x00000010 of the theoretical 64 bit result is not built.
The result should be shifted 4 bit to right because the second factor has 4 dual digits in the fractional part:
0xF9A00000 >> 4 => 0xFF'9A0000
This is near the input value, only multiplied with 1.0666, presenting
-0x9A0000 / 0x400000 ^= 0x660000 / 0x400000 ^= 1.59375
Note: The negative 24 bit number 0x9a0000 is 0x660000 negated, usual 32 bit arithmetic is used, -0xff9A0000 ⇒ 0x00660000.
4.5. Adaption of the macros of fix point multiplication to the machine code
If you want to multiply 16 * 16 bit signed or unsigned to 32 bit, you should expand the input values exactly like necessary for the sign, and simple multiply. To better understand, the numbers have its decimal point after 4 bits, the input range is -8.0 .. -7.9999. The decimal point of the result is with 8 bits before.
0xc000 * 0xc000 => 0xffffc000 * 0xffffc000 => 10000000 -4 * -4 => +16.0 0xc000 * 0x4000 => 0xffffc000 * 0x00004000 => F0000000 -4 * 4 => -16.0
In C it is:
#ifndef muls16_emC
#define muls16_emC(R, A, B) { \
R = ((int32)(int16)((A) & 0xffff) * (int32)(int16)((B) & 0xffff)); }
#endif
#ifndef mulu16_emC
#define mulu16_emC(R, A, B) { R = ((uint32)(uint16)(A) * (uint32)(uint16)(B)); }
#endif
That are the standard definitions of the both macros. The usage is:
int16 a,b; ... int32 result; muls16_emC(result, a, b); uint16 p,q; ... uint32 uresult; mulu16_emC(uresult, p, q);
That delivers anyway the correct results. The compiler may recognize that the inputs have only 16 bit because of the mask and type casting. It is able to expect that the compiler uses its best machine code which may be a 16 * 16 ⇒ 32 bit multiplication.
It may be possible, depending on the compiler properties, that the following term is sufficient:
int16 a,b; ... int32 result = a * b;
But that is not sure in any case. Hence this writing style is not portable. See also
It may be possible that the result has 16 bit and it is expanded to 32 bit, or it works exact. Unfortunately the C standard does nothing guarantee.
For some compiler an __asm(…) statement can be used to select the desired machine code. This can be written as:
#define muls16_emC(R, A, B) \
{ R=(int16)((B) & 0xffff); __asm("MUL %0, %1, %0": \
"+r" (R): "r" ((int32)(int16)((A) & 0xffff))); }
#define mulu16_emC(R, A, B) \
{ R=(uint16)((B) & 0xffff); __asm("MUL %0, %1, %0": \
"+r" (R): "r" ((uint16)((A) & 0xffff))); }
This is an example for ARM processors. The ARM M3 has the 32 * 32 ⇒ 32 lo-bit multiplication, see chapter above, but not dedicated 16 * 16 ⇒ 32 bit multiplication machine statements because the ARM machine has always 32 bit width. The MUL instruction works with two registers, one operand should be the same as the destination. Hence there is no possibility for a optimization. The compiler produces similar results on using the standard macros.
It depends of the type of processor. The Texas Instruments TMS320C2xx processor has the 16 * 16 ⇒ 32 bit MPY statement, but the C2000 compiler does not support __asm(…) instructions with self defined register, it supports only simple static machine code. But the compiler is optimzing too without the asm macros.
For writing the __asm macro for gcc compiling, and also for ARM compiling (AC6) see:
4.6. Example algorithm of a smoothing block with 16 bit input and output but 32 bit state
The data are defined in emC/Ctrl/T1_Ctrl_emC.h as:
typedef struct T1i_Ctrl_emC_T {
/**This value is only stored while param call. It is not used. */
float Ts;
/**The difference q-x for usage as smoothed differentiator.
* dxhi is the representative int16-part regarded to input.
*/
Endianess32_16_emC_s dx;
/**The output value and state variable.
* qhi is the representative int16-part regarded to input.
*/
Endianess32_16_emC_s q;
/**Factor to multiply the difference (x-q) for one step.
* This factor is calculated as 65536 * (1.0f - expf(-Tstep / Ts))
* to expand the 16-bit-x-value to 32 bit for q.
* A value Ts = 0, it means without smoothing, results in 0xffff because only 16 bits are available.
* The largest Ts is 65000 * Tstep, results in 1 for this value.
* Larger Ts does not work.
*/
Endianess32_16_emC_s fTs;
} T1i_Ctrl_emC_s;
The 32 bit values are also accessible as 16 bit parts by building a unit. Therefore a struct Endianess32_16_emC_s is used which contains only a unit to access the 32-bit- and the 16-bit hi and lo parts. This struct is defined depending on the endianness of the processor.
The T1-factor is built with:
bool param_T1i_Ctrl_emC(T1i_Ctrl_emC_s* thiz, float Ts_param, float Tstep) {
thiz->Ts = Ts_param;
float fTs = (Ts_param <= 0 ? 1.0f : 1.0f - expf(-Tstep / Ts_param)) ;
fTs *= 0x100000000L;
thiz->fTs.v32 = fTs >= (float)(0xffffffff) ? 0xffffffff : (int32)( fTs + 0.5f);
return true;
}
To convert the factor, floating point arithmetic is used. In a cheep 16 bit processor it is calculated by software, needs a longer time but the factors are usual calculated only in startup time or in a longer cycle. It is possible to give factors also without conversion, or via conversion over a table, to speed up it. The factor has the decimal point left, and up to 32 fractional bits.
The calculation usual called in a fast cycle is simple. It uses a 16 * 16 ⇒ 32 bit multiplication, which is fastly usual available also in cheep processors. The 32 bit result is used for the integration. The result value uses the higher 16 bit part of this integrator.
static inline int16 step_T1i_Ctrl_emC(T1i_Ctrl_emC_s* thiz, int16 x) {
thiz->dx.v32 = (uint32)(thiz->fTs.v16.hi) * ( x - thiz->q.v16.hi);
thiz->q.v32 += thiz->dx.v32;
return thiz->q.v16.hi; //hi part 16 bit
}
The possible higher accuracy of (x - thiz→q) is not used in this algorithm. But this may be necessary for longer smoothing times. The algorithm above limits the smoothing time to about 65000 * Tstep, because the used high part of fTs is then 0x0001, for greater times it is 0x0000 and nothing occurs.
If it is necessary to use longer smoothing times, it requires a 32 * 32 ⇒ 32 bit multiplication, where the higher part of the 64-bit-result is used. A further improvement may be possible to use a 64-bit-width integrator, but this is not realized here. It is a quest of calculation time effort. The better step routine for longer smoothing times can be called in the application:
static inline int16 step32_T1i_Ctrl_emC(T1i_Ctrl_emC_s* thiz, int16 x) {
thiz->dx.v32 = (int32)(((uint64)(thiz->fTs.v32) * ( (int32)(x<<16) - thiz->q.v32))>>32);
thiz->q.v32 += thiz->dx.v32;
return thiz->q.v16.hi; //hi part 16 bit
}
Right shift (…)>>32 takes the one 32 bit result register from the multiplication, ignores the lower multiplication result. But that is true for this algorithm.
Right shift (…)>>32 takes the one 32 bit result register from the multiplication, ignores the lower multiplication result. But that is true for this algorithm.
The dx part can be used as differtiator with smoothing, simple accessible after this calculation with
static inline int16 dx_T1i_Ctrl_emC(T1i_Ctrl_emC_s* thiz, int16 x) {
return thiz->dx.dx16.dxhi;
}
The outside used values are all 16 bit, for a 16 bit controlling algorithm on a 16 bit controller. But the internal state of the smoothing block is stored as 32 bit. Both, it results in the machine execution of the multiplication, and (!) for the resolution of the smoothing. You can use a great smoothing time, and get exactly results without hanging effect.
If floating point arithmetic is used, the algorithm is more simple to write and understand, but you get the hanging effect for lesser smoothing time (disadvantage of the implementation) and you need always more calculation time, also if a floating point calculation hardware is present.
5. How to scale and prevent overflow or prevent overflow detection effort
This chapter is written also in regard of graphical programming, see www.vishia.org/fbg/html/Videos_OFB_VishiaDiagrams.html. The difference between manual programming in C/ with knowledge of assembler and graphical programming is: Graphical programming is done by people, which knows mathematics and controller algorithm, and also should know the bit image of numbers, but usual do not know assembly language and do not know sophisticated C/-code. That’s why the solution should be addressed to this knowledge.
If you have the following simple situation:
 On the picture right side there is an output 'pos' for 'position' as
On the picture right side there is an output 'pos' for 'position' as int32 with 20 bits after decimal point.
This is a user decided scaling using fix point.
With the 12 bit before decimal point a range from -2048..+2047 is able to map,
which may be the physical range for a position in mm. More is not necessary.
The int32 format is used to add less parts in the step time, here 1 ms.
For a slow movement only 1 µm may be added, for 1 mm/s velocity.
1 µm distance in this presentation is a difference of 0x00000419 to add, which needs 32 bit artithmetic.
The output of the controller has also 32 bit, here interpreted as percent value from -100..100 with overdrive, it means we have 24 bit after dot. That is more as enough, not really necessary because this is the motor voltage which cannot be so fine controlled. But anyway, there are two smoothing blocks which are calculated with 16 bit. This is enough. It simulates a delay of the movement motors. The output after the second Tsi FBlock is the velocity of the motor.
But note, that this Tsi smoothing FBlocks uses internally 32 bit for growth. Only the output is 16 bit. But this is enough resolution for the velocity.
Because the decimal point of the int32 on yCtrl is on bit24, and for the input of the t1 it is on bit 8 for 'int16',
the code generator generates a shift so that the value is placed correct with decimal point.
For this situation exact the high word (16 bit) of yCtrl is used.
That is simple, and that was also the intension of the graphic programming.
But now look on the right FBlock in the image. it is an integrator, because its own value is added. The own value is a 'Zout', delayed for one step time. It is adequate:
pos = pos_z + t2.y * fPos;
and later in an update operation:
pos_z = pos;
The graphic allows presentation of a multiplication factor in the adder expression.
The multiplication factor is a variable, build in another step time, in int16 presentation,
but with 22 fractional bits. Given as type 'S.22'.
how can a int16 have 22 fractional bits?
Simple, it is a number which is interpreted in range till max. 0.0078122 = 1.0 / 222 * (215 -1).
The output value of 100% ( = 0x6400) multiplied with the maximal factor 0.007812 (= 0x7fff)
should result in a movement of 0.7712 mm in 1 millisecond, or a velocity of 771.2 mm/s.
This should be the fastest movement (~1 m/s). But the factor can be tuned, for example to move maximal 10 cm/s.
Then the factor should be 0.001 (0.1 mm in 1 millisecond for 100%),
which is a hex value of fpos = 0x1039 = 0.001 * 222
But this calculation is done by the generated code for the fPos variable which is:
thiz->fPos = ((((int16)((1L<<22)*(fPosf)))));
This is generated code with a little bit to many paranthesis, which does not disturb the compiler.
6. Trigonometric and sqrt routines for fix point arithmetic
The sin, cos, sqrt etc. are part of the standard C/++ libraries for floating point, single and double precision, but not for fix point.
The other question is: calculation time.
6.1. Linear and quadratic approximation

The red curve should show the really function.
The blue lines are the tangents. Near the point itself the linear approximation is accurate as possible. But between the points a greater abbreviation is given. This can be redeemed by a second order (quadratic) approximation, not shown here. As tested the quadratic approximation delivers errors less or equal 4 for 16 bit numbers, with only 16 supporting points, a well useable result.
dx := (x - xp);
y := yp(xp) + gp(xp) * dx + g2p(xp) * dx2;
Where gp is the tangent (the exactly deviation of the curve) or the quotient
gp = (yp+1 - yp-1) / (xp+1 - xp-1);
and g2p is the difference of the gp of the left and the right point:
g2p = ( (yp+1 - yp) / (xp+1 - xp) ) - ( (yp - yp-1) / (xp - xp-1) );
If the step width between the points in x are equidistant: xpp, it is more simple:
gp = (yp+1 - yp-1) / ( 2*xpp);
g2p = ( (yp+1 - yp) - (yp - yp-1) ) / xpp;
This is the same as shown for example in https://www.astro.uni-jena.de/Teaching/Praktikum/pra2002/node288.html, (visited on 2021-04-13), only the term for the quadratic part is shown there more 'mathematically', but it is the same: `( (yp+1 - yp) - (yp - yp-1) ) == (yp+1 - 2 * yp + yp-1). The left form prevents overflow in calculation with fix point arithmetic.
Simple linear approximation but with middle-correct of abbreviation
But the algorithm for a linear approximation is very simple:
y := yp(xp) + gp(xp) * (x - xp)
xp is the x value where the nearest point is found. gp and yp are read from the table. dx = x - xp is left and rigth side from the point.
The green lines are slightly shifted. The error on the supporting points are approximately equal to the error in the middle, the error is halved. But this is not the most important effect. More important may be that an integration does not sum up the deviations only in one direction. It can be seen on cos values: Its integration should deliver sin values, and the area or the range -Pi .. Pi should be 0. The calculation is the same, but the values are corrected in the table.
For the C/++ implementation the tables contains valued immediately given as hexa values. But this values are calculated by a Java program, using the double precision functions, with the named correctures. See org.vishia.math.test.CreateTables_fix16Operations (https://github.com/JzHartmut/testJava_vishiaBase).
In C language the core algorithm for the linear approximation is written as (emC/Base/Math_emC.c):
#define LINEARinterpol16_emC(X, TABLE, BITSEGM) \ uint32 const* table = TABLE; \ uint32 valTable = table[( X + (1 <<(BITSEGM-1) ) ) >>BITSEGM]; \ int16 dx = ( X <<(16 - BITSEGM) ) & 0xffff; \ int16 gain = (int16)(valTable & 0xffff); \ muls16add32_emC(valTable, dx, gain); \ int16 y = (int16)(valTable >>16); \
It is a macro used in some functions, see below. The expanded macro is well for compilation. Using an inline function may have disadvantages, for example calculation (16 - BITSEGM) as compiler constant. This macro is defined only in the compiling unit emC/base/Math_emC.c locally, not common useable.
valTable: For faster access on 32 bit processors only one value with 32 bit is read from the table. The high part is the supporting point, the low part is the gain. The gain is dispersed in the next line.
Index to the table: The x value in range 0x0000 .. 0xffff supplies the index to the supporting points. Depending on the size of a segment, given in BITSEGM as number of bits, the x value is shifted to right. Adding (1 <<(BITSEGM-1) before shifting gets the index of the right point for the right part of a segment. The index calculation are a few operation in a 16 bit register. The value (1 <<(BITSEGM-1) is calculated as constant by the compiler anytime. Example: BITSEGM = 9 means, a segment is for example from 0x3c00 .. 0x3e00, 9 bits. For a value 0x3d65 a 0x100 is added (1 << 8), and after right shift from 0x3e45 the value 0x1f as index to the table results.
dx: The difference value inside the segment is taken from the x value shifting to left, shift out the index bits. The dx is positive or negative. Example: For the value 0x3d65 a shift to right with (16-9 ⇒ 7) bits is done and results in 0xB280. The operation & 0xffff is optimized because the compiler may or should be detected that it is only a 16 bit operation. Visual Studio may detect a run time error because it expands the numeric range to int32 and checks the follwing casting, if & 0xffff was not written there, though x is an int16 and the operation should be performed as int16 operation. Java does similar, but for Java it is defined in the standard, that all integer operations are executed with at least 32 bit.
muls16add32: The multiplication uses both 16 bit values. The useable result is located only in the high bits 31..16 of the multiplication result. Hence the addition with the whole table value with the supporting point in bit 31..16 would add correctly 16 bit with round-down if the lo bits 15..0 of valTable would be set to 0. The Savings of this operation gives a possible overflow, an error of only one bit. This is not relevant, calculation time saving is more relevant.
int y: The operation (int16)(valTable >>16) uses 32-bit half register operations or uses the 16-bit-register immediately. As expected all compiler detects this situation, and do not produce the >>16 operation, except it is a 32 bit processor without access to half register.
Adequate the (int16)(valTable & 0xffff) is a optimized half-register optimization, without mask with 0xffff which would need loading a constant in machine code.
Hence this operation is so fast as possible.
6.2. cos and sin, algorithm of linear interpolation in C language
sin and cos are adequate, only shifted by 90°. Hence the cos is programmed, and the sin is derived with:
#define sin16_emC(ANGLE) cos16_emc((ANGLE)-0x4000)
The cos is symmetric on y-axes and point-symmetric for 90°. The interpolation need only be executed between 0° and 90°:
int16 cos16_emC(int16 angle) {
int16 x = angle;
int16 sign = 0;
if(angle <0) { // cos is 0-y-axes symmetric. .
x = -x; // Note: 0x8000 results in 0x8000
}
if(x & 0xc000) {
x = 0x8000 - x; // cos is point-symmetric on 90?
sign = -0x8000;
}
//now x is in range 0000...0x4000
Because the reduced x range only 32 and not 128 supporting points are need. This reduces Flash memory amount. But the preparation increases the calculation time. Hence it may be dismissed.
More simple is, using 64 supporting points and only build the absolute value. Results from positive and negative angles are exactly the same.
int16 cos16_emC ( int16 angle) {
int16 x = angle;
if(angle <0) { // cos is 0-y-axes symmetric. .
x = -x; // Note: 0x8000 results in 0x8000
}
//now x is in range 0000...0x4000
//commented possibility, using interpolqu, extra call, more calctime
//int16 val = interpolqu16(angle1, cosTableQu);
// // access to left or right point
LINEARinterpol16_emC(x, cosTable, 9)
/*
uint32 const* table = cosTable;
uint32 valTable = table[( x + (1<<(9-1) ) >>9];
int16 dx = ( x <<(16 - 9) ) & 0xffff;
int16 gain = (int16)(valTable & 0xffff);
muls16add32_emC(valTable, dx, gain);
int16 y = (int16)(valTable >>16);
*/
return y;
}
This is the whole cos16_emC operation, with all comments for experience (2021-04-07).
The cosTable looks like (shortened):
static const uint32 cosTable[] =
{ 0x7ffffffb // 0 0
, 0x7fd3ffb2 // 1 200
, 0x7f5dff64 // 2 400
, 0x7e98ff15 // 3 600
.....
, 0x0c8bf9c0 // 30 3c00
, 0x0648f9bb // 31 3e00
, 0x0000f9b9 // 32 4000
, 0xf9b9f9bb // 33 4200
, 0xf376f9c0 // 34 4400
.....
, 0x80a4ff63 // 62 7c00
, 0x802dffb2 // 63 7e00
, 0x8000fffa // 64 8000
};
The value for 0° is set to 0x7fff which is 0.99997, because the value of 1.0 cannot presented. 90° is exactly 0, and 180° (angle 0x8000) is exactly 0x8000, which is -1.0. The error of approximation is at max -8..8, tested. It is greater in the ranges around 0° and 180°, lesser near -1..1 in the range around 90°. Using the sinus with the same operation (only the angle is shifted) means, a sin in the linear range around 0° has only an interpolation error from -1..1 related to 32768.
6.3. Calculation of the tables for supporting points in Java
The Java algorithm to get the supporting points and gain uses double algorithm and rounding. It is written commonly for any mathematic function. See snapshot of org.vishia.math.test.CreateTables_fix16Operations.java:
public class CreateTables_fix16Operations {
/**The functional interface for the operation as lambda expression.
*/
@FunctionalInterface interface MathFn {
double fn(double x);
}
Firstly an internal interface is defined for all the functions.
The common operation to create a table is:
/**Create a table for linear interpolation for any desired math operation
* @param bitsegm Number of bits for one segment of linear interpolation (step width dx)
* @param size Number of entries -1 in the table.
The table get (size+1) entries, should be 16, 32, 64
* @param scalex Scaling for the x-value,
this result is mapped to 0x10000 (the whole 16 bit range)
* @param scaley Scaling for y-value, this result of the operation is mapped to 0x8000.
* @param fn The math function as Lambda-expression
* @param name of the file and table as C const
* @param fixpoints array of some points [ix] [ yvalue] which should be exactly match
* @return The table.
*/
public static int[] createTable(int bitsegm, int size, double scalex, double scaley
, MathFn fn, String name, int[][] fixpoints) {
....
}
It is a common operation for all mathematic functions to support tables. Invocation for the cos is:
public static int[] createCosTable() {
int[][] fixpoints = { {0, 0x7FFF}, {1, 0x7FD3}, {32, 0x0}, {64, -0x8000} };
int[] table = createTable(9, 64, Math.PI, 1.0, (x)-> Math.cos(x), "cos", fixpoints);
return table;
}
There are some manual given points, especially 0x7fff and 0x8000 for the first and last point. Elsewhere the algorith calculates a value of 0x7ffc and a gain of 0 for the first segment. The point {32, 0x0} is the value for 90°, which should exactly much. But the value is calculated to 0 also without this setting because the cos is linear and point symmetric in this range.
The segment size is 9 bit =^ 0x200. With 64 values the range 0x0..0x8000 is produces. The Math.PI is the x scaling for this range. 1.0 is the y scaling regarded to 0x8000.
The expression (x)→ Math.cos(x) is a "Lambda expression" in Java, a simple kind to provide a function.
"cos" is the name of the table "cosTable". This routine generates all points, test all points with printf-output for manual view and writes the file yet to T:/<name>Table.c.
Java is a more simple programming language and hence proper for algorithm tested on PC, as preparation for embedded software. Same written and tested in C++ is more complicated. It is not necessary. The advantage of Java is: It has the same approaches for integer processing as C/++.
6.4. arctan2
An important function to get the angle from a complex presentation is the arctan2 operation. Normally it divides both values and uses either the arctan or the arccot operation.
int16 arctan(int16 im, int16 re) {
if(re > im) {
return arccotan(im/re);
} else {
return arctan(re/im);
}
}
This is the proven concept, uses stable mapping of mathematic functions and prevent division by zero. But: It needs a division which is not a cheep operation for fix point arithmetic.
There is another way to calculate:
Usual either the values for the { re, im } vector are normalized or the magnitude is a point of interest, and the normalization is a more cheap and by the way occurring operation.
Hence the arctan is defined for normalized values and uses a arccos table. The arccos does not need a decision, it is a continuous table.
int16 atan2nom16_emC ( int16_complex x ) {
short re1 = x.re; short im1 = x.im;
int quadr = 0;
if(im1 <0) {
im1 = (short)-im1;
quadr = 2;
}
if(re1 <0) {
re1 = (short)-re1;
quadr |= 4;
}
int xasin;
if(re1 < im1) {
xasin = re1;
quadr |= 1;
} else {
xasin = im1;
}
LINEARinterpol16_emC(xasin, asinTable, 10);
switch(quadr) {
case 0: return y;
case 1: return 0x4000 - y;
case 5: return 0x4000 + y;
case 4: return 0x8000 - y;
case 6: return 0x8000 + y;
case 7: return 0xc000 - y;
case 3: return 0xc000 + y;
case 2: return -y;
default: return 0;
}
}
This is the whole algorithm, see emC/Base/Math_emC.c. Simple comparisons determine one of the 8 segments of the result. The input for the linear interpolation is always in range 0x0000 .. ~ 0x2d80 which is a proper range for the approximation.
The normalization of the x-input is 0x4000 for 1.0. Hence the lesser value of re and im part is never greater then ~sqrt(2)*0x4000 which is approximately 0x2d41. But less errors for the normalization may force a slightly higher value. But the asinTable goes to 0x4000.
The calculation time of this solution for 16 bit fix point is approximately the same as a floating point atan2f(im, re) operation of the math.h standard library for C, measured on the TMS320F28379 Processor from Texas Instruments, which has Floating point support. In opposite most int16 or int32 operations needs about 150% of the calculation time compared with the floating point calculations on that processor,
How to normalize:
-
Use either
rsqrt16_emC(….)from the sum of the squares of the components, and multiply the components with that factor (reciproke of square root), -
or use
Nom_int16_complexas step routine in a continouos control algorithm.
The normalization is often anyway necessary. To get the magnitude (not only the revers magnitude) either a division can be used, or it is gotten also with the Nom_int16_complex.
6.5. sqrt
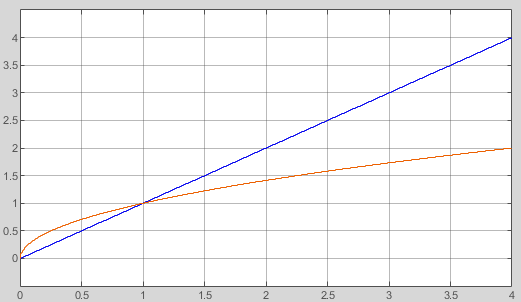 The square root is only defined for positive numbers. Hence the input range can be from 0… <4.0 mapped to 0x0 … 0xffff. The sqrt is then in range 0..<2.0 which can be mapped to 0x0…0x7fff. The result can be used than as signed value.
The square root is only defined for positive numbers. Hence the input range can be from 0… <4.0 mapped to 0x0 … 0xffff. The sqrt is then in range 0..<2.0 which can be mapped to 0x0…0x7fff. The result can be used than as signed value.
int16 sqrt16_emC ( uint16 x);
is defined in that kind. The value 0x4000, mapped to 1.0, results in 0x4000.
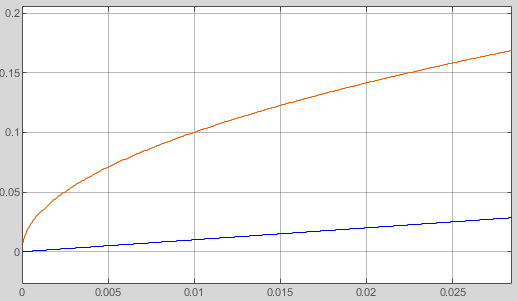 The sqrt function has a problem in 0-range. The deviation of sqrt is
The sqrt function has a problem in 0-range. The deviation of sqrt is 1 / (2 * sqrt(x)). This is infinitive for exact 0. The right image may show that the sqrt line (red) is perpendicular at the point 0. If the linear approximation is used with equal distances in x, it has a problem in the first segment. The linear connection does not represent useable values.
But: Is an exact sqrt necessary for values near 0? Often values in the nominal range are the point of interest. It means between 0.5 … 2 of the nominal values. In that range the simple linear approximation of the sqrt is well useable. The test of results of the sqrt16_emC(…) uses values started from 0x600 only, it is ~ 0.1. From this value the abbreviation is <9, it is <0.1% regarded to the value 0x4000 =^ 1.0.
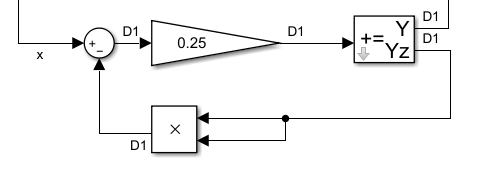 To get the sqrt in controlling systems there is another possibility shown in the right image. The x-value (the quadrat) is delivered as the input of a controller feedback. The feedback is the output multiplied with itself. This is compared with the input, and the controller will control it to the equal value (zero-deviation). Hence the output of the controller is the sqrt because the feedback is the square. See also chapter #Nom_int16_complex
To get the sqrt in controlling systems there is another possibility shown in the right image. The x-value (the quadrat) is delivered as the input of a controller feedback. The feedback is the output multiplied with itself. This is compared with the input, and the controller will control it to the equal value (zero-deviation). Hence the output of the controller is the sqrt because the feedback is the square. See also chapter #Nom_int16_complex
This can be used anytime if the input value x does not change in a wide range for one to the next step, as given in usual controlling systems. But also for the step response of the control loop only a first deviation is given. It is fast.
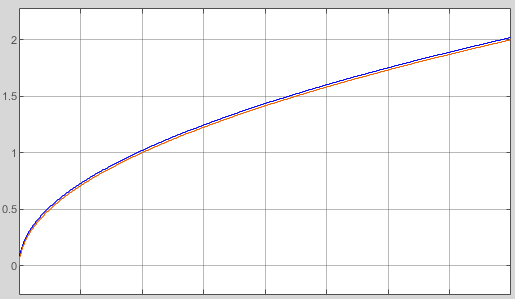 The gain of this controller loop should depend on the max possible value of the output, with multiplication the gain in loop should be < 1.0. This is true for the right image for input values less than 4.0.
The gain of this controller loop should depend on the max possible value of the output, with multiplication the gain in loop should be < 1.0. This is true for the right image for input values less than 4.0.
The right image shows the controller output and the calculated sqrt. Both curves lie on top of each other. An additional offset of 0.02 is only used to see both curves in the diagram.
6.6. rsqrt - reciprocal square root
The reciprocal or inverse square root can be used to normalize a value. The value should be multiplied with the reciprocal square root of the quadratic sum of the components:
rm := rsqrt(y.re * y.re + y.im * y.im);
ynom(re, im) := y(re, im) * rm;
The magnitude itself is not calculated with this, but the division, more expensive for simple controller, is prevented.
m := sqrt(y.re * y.re + y.im * y.im);
ynom(re, im) := y(re, im) / m;
…needs two divisions, for real and imagine part, instead two more cheap multiplications.
But, the value for 0 is infinitive. It is mapped to the max possible value, it is 0x7fff =^ 1.9993. Lesser values than 0x14a0 =^ 0.322 deliver a result which is lesser as expected. It means using for normalization delivers to less values. The supporting point table has 33 entries. Values from 0x14a0 = 0.322 till 0x27a0 =^ 0.641 may have an abbreviation till 42/16384. Values from 0.641 .. 1.9993 may have an abbreviation ⇐10 / 16384 which is < 0.1%. It means for values near the nominal value 1.0 =^ 0x4000 it is proper useable.
int16 rsqrt16_emC ( int16 x);
works in range 0 … 1.9993 mapped as 0x0 .. 0x7fff and delivers a value in range 1.9993 … 0.5 mapped to 0x7fff .. 0x2000 as int16 result.
6.7. reciprocal
If the sqrt16_emC() is used for normalization or for any other reason the reciprocal value may need:
y := 1 / x;
Because a division is a non-cheap operation on some controller without specific division hardware support, using a linear approximation is also possible and evident to use.
6.8. Nom_int16_complex
This is a class for a controlling algorithm to get the nominal values of a vector and/or the magnitude.