Programmierung ist im Wesentlichen die Sortierung und Verknüpfung von Daten.
Seit den Anfängen der Rechentechnik hat sich dabei der Umfang dessen, was das sortiert und verknüpft wird, bedeutend erhöht.
Deshalb kommt man nicht mehr mit den einfachen Mitteln der handgestrickten Programmierung hin, sondern mußte solche Dinge
wie Objekrorientierte Programmierung und UML erfinden. Das ist das Sprachgerüst für das Beherrschen komplexer Programmieraufgaben.
Neben diesem formalen Gerüst sind aber noch einige Erfahrungen, wie man damit umgeht, von Nöten.
Ein als Quelltext vorliegendes Programm, egal in C, C++, Java, ... besteht aus mehr als 50% Text, den man schreiben muss,
weil es nur so richtig ist. In weit weniger als 50% drückt man das aus, was man selbst will. Das zeigt sich schon ein einem
weltbekannten einfachem Beispiel:
In diesem Programm sind drei Dinge selbst bestimmt:
Die Zeichenkette, die man ausgibt könnte auch eine ganz andere sein, direkt änderbar. Das ist ein frei bestimmbarer Sourcecode.
Die Tatsache, das man überhaupt etwas ausgibt, mit printf ausgedrückt. Hier hat man bestimmte, eher wenige Möglichkeiten. Das ist ein Sourcecode, bei der man aus Vorgaben auswählen
kann.
Die Programmstelle, an der unter welchen Bedingungen etwas ausgegeben wird. In diesem einfachen Programm gibt es nur eine
Stelle, im Body von main.
Der Rest, das Schreiben-Müssen von #include..., von void main(void) usw. ist notwendig ohne eine freie Entscheidung. Dabei kann man sich verschreiben oder nicht genau wissen, was da zu schreiben
ist. Ärgerlich für den Anfänger. Daher ist die Frage berechtigt ob man dies nicht auch weglassen könne. Im Ergebnis dessen
könnte etwa eine grafische Benutzeroberfläche entstehen, an der man in ein Fenster hello world oder etwas anderes passendes eingeben kann. Ein Auswahlfeld bestimmt dann ob mit printf oder fprintf oder.... Das wärs dann,
für alle einfach benutzbar. Ist dies der Weg? Ein Vergleich: Wenn man im Wald spazierengeht, kann man sich maßlos verlaufen,
trotz Ausschliderung mit Wanderwegzeichen. Man hat die freie Wahl des Weges, aber viele Wege führen im Kreis oder nicht dorthin
wo man will. Für eine geführte Wanderung etwa in einem Biotop könnte bzw. sollte man Absperrungen anbringen, an denen man
sich orientieren kann. Es gibt nur wenige, aber gute Wege. Würde man dies als Allgemein-Lösung vorschlagen, auch gültig für
etwa ein Archäaologenteam, das im Gelände noch unentdeckte Burganlagen sucht, es könnte nicht in den freien Wald gelangen.
Ähnlich ist es mit der freien Programmierung. Überall Badagen, wie sollte man dann das GUI-Programm überhaupt schreiben, das
für Otto-Normalbenutzer ganz einfach ist?
Nicht nur ein Anfänger kann sich damit behelfen, ein ähnliches bereits getestetes Programm als Vorlage für ein neues Programm
zu benutzen. Allgemeingültige Vorlagen kann man als Muster (engl. sample) bezeichnen. Der Begriff pattern ist dagegen anderweitig besetzt, er ist bezüglich UML umfassender gemeint.
Programmier-Entwicklungsumgebungen haben meist die Möglichkeit, nach ein paar grafischen Eingaben so ein Muster selbst zu
erzeugen. Man hat dann sehr viel Sourcecode vor sich, den man im Detail vielliecht gar nicht verstehen will, der aber an einigen
Stellen modifiziert bereits die gewünschten Erst-Ergebnisse bringt. Nach und nach wird man mit dem Rest des Sourcecodes vertrauter
und wird ihn souverän den eignen Anforderungen anpassen.
Korrektur- und Komplettierungsvorschläge des Editors
Heutige Rechentechnik ist schnell genug, um während des Tippens eines Quelltextes diesen zu analysieren und Korrektur- und
Komplettierungsvorschläge anzubieten. Dazu kommen noch gezielte per Menü auswählbare Muster, die den bereits bestehenden Quellcode-Kontext
berücksichtigen. Damit ist eine recht elegante Arbeitsweise gegeben, bei der man die Ebene des reinen Quelltextes nicht verlässt.
Typisch dafür ist beispielsweise Eclipse. Zusammen mit einer laufenden Compilierung, Syntaxfehleranzeige, wiederum mit auswählbaren Korrekturvorschlägen schrumpfen
damit die nervigen 50% des Schreiben-Müssen-Quellcode auf ein Lesen-Dürfen zusammen.
Ein Quelltext kann während des Schreibens oder jeweils in einer fertigen Phase analysiert werden. Der Inhalt lässt sich mindestens
als Browser-Baum von Strukturen darstellen. Noch besser ist beispielsweise eine UML-Darstellung. Allerdings ist die Information,
was wo in der zweidimensionalen Ansicht dargestellt wird, aus einem normalen Quelltext nicht entnehmbar. Es bedarf Zusatzinformationen.
Die geschickte Kombination von grafischen Infos eines UML-Tools mit den strukturellen Infos aus dem Programmquelltext ist
als Königsweg anzusehen, wenn man gern im reinen Quelltext arbeitet. Um zu einer UML-Darstellung zu kommen, kann man zunächst
einen Strukturbaum erzeugen. Die vorhandenen Strukturen kann man dann grafisch plazieren und deren Verbindungen anzeigen.
Wenn sich in der Programmstruktur etwas ändert, dann kann in der zugehörigen Grafik entweder eine Bezeichnung korrigiert sein,
oder ein nicht mehr vorhandenes Element ist irgendwie schraffiert dargestellt. Mit wenigen grafischen Bedienhandlungen kann
man dann entweder die UML-Darstellung korrigieren, oder etwa den Quelltext anpassen oder Elemente neu zuordnen, damit die
Grafik aktualisieren.
Meist wird die Grafische Programmierung als Gegenteil und Höherentwicklung der Text-Programmierung verstanden oder dahingestellt.
Unter Grafische Programmierung kann sehr viel verschiedenes verstanden werden, insgesamt alles, was auf keinem einfachen Quelltext beruht. Grafische Programmierung
und Quelltextprogrammierung sind aber mitnichten ein Gegensatz, sondern ergänzen sich. Eine rein grafische Programmierung
- ohne dass irgendwo etwas quelltextartiges eine Rolle spielt, hat so seine Schwierigkeiten. Das beginnt mit der Versionspflege
- wo sind die Unterschiede. Die Programmierung steckt meist in einer großen Datenbank - schwer handelbar. Eine solche grafische
Programmierung ist eher Endkunden-geeignet. Dort wo ein Quelltext keine Rolle spielen soll und gleichzeitig die außen sichtbare
Komplexität nicht allzu hoch ist.
Interessant ist eine grafische Programmierung, wenn es um Funktionsblöcke geht, die parametriert und verdrahtet werden sollen.
Das ist bekannt aus der Analogtechnik und sehr anschaulich. Viele Simulationstools basieren darauf.
Grundlage ist zunächst die Funktionseinheiten mit ihrer Parametrierung. Diese werden auf eine grafische Fläche gesetzt, folglich
hat man eine Position, gegebenenfalls eine geometrische Größe, abhängig von der Parametrierung bestimmte grafische Erscheinungen.
Das zweite Element ist die Verbindung der Funktionseinheiten. Die Verbindung kann parametriert sein oder auch nicht. Die Verbindungen
zwischen Funktionseinheiten können grafisch automatisch gezeichnet werden. Dann hat man dort keine extra Daten zu speichern,
aber man kann ein Layout eher schwer bestimmen (nur durch Umordnung der Funktionsblöcke), oder die Verbindungen haben beliebige
Verläufe, damit viele geometrische Informationen. Verbindungen können über Seiten gehen und brauchen dann Konnektoren.
Diese grafische Projektierung muss, um damit etwas machen zu können, in einen Ablaufcode generiert werden. Dieser Ablaufcode
gehört nicht mehr zum Thema Programmierung sondern ist Implementierung und kann verschiedenartig ausgeführt sein. Beispielsweise wird C-Quellcode generiert, der dann compiliert wird.
Jede grafische Programmierung lässt sich datenmäßig in einer Textform abbilden, oder binär codiert irgendwie ablegen. Ein
Textformat eröffnet die Möglichkeiten der Versionspflege wie bei der Quelltextprogrammierung. Der Textcode sollte grundsätzlich
lesbar sein, mindestens um Unterschiede von Versionen erkennen zu können. Denkbar ist es auch, neben der Grafik auch im Textcode
korrigieren zu können. Das kann aber nie frei geschehen, dazu sind meist zuviele Details zu beachten, sondern beispielsweise
toolgestützt. Die Komplexität dabei ist aber nicht viel anders als wenn man einen C-Code, bei dem auch Format und Syntax zu
beachten ist, editiert und die Richtigkeit vom Compiler prüfen lässt. XML aus Grundlage für ein Textformat ist durchaus geeignet.
Die grafischen Programmiertools sind hier sehr unterschiedlich. Manche speichern alle Informationen in einer binär codierten
Datenbank, nirgends Textcode. Die Speicherung in einem Textcode ist aber durchaus üblich. Allerdings ist dieser Text aus vor-XML-Zeiten
doch oft sehr speziell codiert, schwer lesbar und sollte nicht manuell geändert werden. XML-codierter Text ist semantisch
eher fassbarer, die Hilfe von XML-Editoren ist angebracht. Aber frivole Handänderungen können schnell daneben gehen.
Ideal wäre ein semantisch verständliches Format, was sowohl grafisch als auch textuell beeinflussbar ist. Textuelle Änderungen
sollten sofort auf Gültigkeit überprüft werden und grafisch repräsentiert werden können. Das wäre also eine Parallelität von
Grafik und Text-Eingabe. Manche Tools machen dies so.
1.2.2 Abbildung von Elementen eines Quelltextes in einem Baum
Ein Quelltext von Programmiersprachen ist immer strukturiert: Verzeichnisse, Files, Abteilungen in den Files, Klassen, Methoden,
Blöcke in den Methoden. Wenn der Quelltext geparst wird, entsteht automatisch ein Baum des Inhaltes. Die Darstellung als Baum
ist eine gute Unterstützung beim Programmieren, zum Erhalt eines Überblickes, Hilfe beim Suchen. Solche Bäume sind schon lange
Zeit Bestandteil fast jeder IDE (Integrated Development Enviroment). Mit Eclipse und Java wird der Baum während des Schreibens
aktualisiert, da sich der Java-Quelltext on-the-fly analyiseren lässt.
Ein solcher Baum der Struktur des Quellprogrammes ist eine äußerst gute Hilfestellung beim Quelltextprogrammieren. Änderungen
in der Struktur lassen sich oft direkt am Baum ausführen. Diese Baum-Darstellung möchte ich mit in die Kategorie der grafischen
Programmierung einordnen.
Die UML hat sich als grafische Programmierung der Objektorientierten Softwareentwicklung etabliert.
UML besteht aus mehreren Diagrammarten, die Ihre Bedeutung von der Architektur eines Gesamtsystems bis zu Implementierungsdetails
hat. An dieser Stelle sollen nur wenige Dinge genannt werden.
Programmierung ist ein großer Gesamtkomplex, doch sie kann aus mehreren Sichten betrachtet werden. Dieser Gedanke ist in der
UML stark vertreten. Ein Diagramm ist jeweils ein Abbild eines bestimmten Zusammenhanges. Folglich hat man es in der UML nicht
mit einer grafischen Programmierung zu tun sondern eher mit einer grafischen Abbildung der Programmierung. Die Gesamtheit
aller Elemente, die in einem UML-Modell vorhanden sind, werden daher nicht flächengrafisch, sondern meist in einem Baum dargestellt.
Die Elemente des Baumes enthalten oft viele detaillierte Parametierungen, beispielsweise und vor allen Dingen oft einen textuellen
Quelltext als Ablaufcode beispielsweise in Methoden. Dieser Ablaufcode ist nun das wesentlichste, jedenfalls aus Implementierungssicht.
Die Grafiken beziehen sich auf Übersichtsebenen. Daher Vorsicht mit der Interpreation, man hätte hier eine vollkommen grafische
Programmierung mit automatischer Code-Erzeugung.
1.3 Generieren von Quelltexten
Topic:Programming.ProgramWriting.SourceGenerator
Generierte Quelltexte sind eigentlich keine Quellen, sondern Generate. Da sie aber nicht anders aussehen als handgeschriebene
Quellen und sich im Generierprozess auch daneben einordnen, zudem als Quelle für die weitere Generierung (Compiler, Linker)
dienen, ist die Bezeichnung Quelltext nicht grundfalsch. Man kann von Sekundärquellen sprechen.
Die Primärquellen sind gegebenenfalls eine UML-Grafik...
Eine Software lebt lange, Algorithmen können Jahrzehnte überdauern. Dabei gibt es grundsätzlich zwei Möglichkeiten:
Man passt die Software der fortschreitenden Technik und Softwaretechnologie an.
Man belässt die Software-Quellen so wie sie sind, und vertraut auf Rückwärtskompatibilität bezüglich des Compilierens.
Im zweiten Fall wird man manchmal formelle Anpassarbeiten machen müssen, ohne den Kern des Algorithmus zu verändern. Der zweite
Fall ist der zunächst unaufwändigere. Zu berücksichtigen ist dabei, dass der Durchblick durch die Algorithmen entsprechend
der Menge der Befehlszeilen gegebenenfalls nicht vollständig gegeben ist und eine falsche Änderung einen großen Aufwand an
Fehlersuche nach sich zieht. Do not touch a running system ist hierzu der bekannte passende Spruch. Jedoch, sind Änderungen wegen neuer Anforderungen notwendig, dann ist der Arbeitsaufwand
da.
Das Problem bei Software ist oft eine nicht ganz optimale Strukturierung, die im Laufe der Zeit zunächst aufgrund weniger
gut entwickelter Softwaretechnologie, dann wegen darangestrickter Änderungen entstanden ist.
Der Idealfall der Softwarepflege sieht wie folgt aus:
Eine neue Anforderung wird formuliert, oder ein Fehler wird erkannt.
Es wird dasjenige Modul ermittelt, in dem zu ändern ist.
Es wird nur im betreffendem Modul korrigiert oder erweitert, alle Schnittstellen bleiben gleich.
In diesem Fall muss man nur ein Modul gedanklich durchdringen, gegebenenfalls lässt sich das Problem auf wenige Programmzeilen
reduzieren. Dieser Idealfall kann erreicht werden, wenn die Softwarestrukturierung gut ist. Eine gute Softwarestrukturierung
erreicht man aber nur durch fortlaufende Pflege. Warum?
Eine zunächst neu entwickelte Software hat eine bestimmte Strukturierung zur Grundlage, die durch Designstudien ermittelt
worden ist. Danach wird programmiert.
Wie das Leben so spielt, an der einen oder anderen Stelle hat man in der Designphase nicht alles durchdacht.
Meist ist aber zunächst keine Zeit und kein Geld vorhanden, eine ordnungsgemäße Korrektur durchzuführen. Die erste Fertigstellung
der Software wird also bereits mit gewissen Strukturschwächen vorhanden sein. Diese Software muss produktiv laufen, um sich
zu bewähren, getestet zu werden, Geld einzuspielen. Es macht keinen Sinn, Software ewig zu korrigieren bis sie tatsächlich
super-schön ist. Man hat dann nicht nur kein Geld verdient, sondern hat auch keine Einsatzerfahrungen.
Damit ist die Korrektur der Stuktur aber verschoben in die Zeit der Softwarepflege. Eine Software, die über ein Jahr im Praxiseinsatz
ist, kann in einer Parallelentwicklung schonmal umstrukturiert und neu herausgegeben werden. Äußerlich ändert sich eine Versionsnummer
- sonst eher weniger. Aber eine produktiv genutzte Software, die längere Zeit weiterlaufen soll, wirft genügend Zeit, Geld
und Motivation zur Pfelge ab. Diese Chance ist zu nutzen.
Wenn dann später weitere Features hinzukommen sollen, ist eine laufende Kontrolle der Strukturierung und gegebenenfalls deren
Korrektur angebracht. Dabei muss aber die gesamte Software beherrscht werden. Nur damit wird erreicht, dass eine Einzelkorrektur
tatsächlich nur in einem Modul stattfinden kann.
1.5 Teamarbeit
Topic:Programming.ProgramWriting.Team
1.5.1 Korrektur kleiner Wichtigkeiten
Topic:Programming.ProgramWriting.Team.FineCorr
Unter dem Stichwort Kleine Wichtigkeiten sollen diejenigen Dinge aufgeführt werden, die zwar die Gesamtfunktionaliät der Software nicht beeinträchtigen, jedoch immer
wieder zu kleinen Ärgernissen führen: Wozu muss man immer erst Taste X betätigen, damit Taste Y aktiv ist?. Wesentlich bei solchen Dingen ist oft, dass Person/Bedienerkreis A gern eine Korrektur haben möchte, eine andere Person
interessiert sich aber nicht dafür. Eigentlich hilft dann nur, den Kunden König sein zu lassen. Wenn der Kunde die Forderung stellt, könnte es sein, man bekommt die Änderung auch bezahlt. Allerdings sind Kunden oft geduldig,
sie wissen nicht, dass es auch besser ginge, vergessen die Forderung beim Gespräch, weil andere Dinge an der Tagesordnung
sind usw. usf.
Wenn die Software einer Komponente von einer Person oder Personengruppe allein verantwortet und bearbeitet wird, dann ist
eine Korrektur kleiner Wichtigkeiten eher schwierig, wenn die Bearbeiter darauf keinen Fokus haben. Man muss erst beantragen,
die Wichtigkeit herausstellen usw. Wenn aber Software temporär von einer größeren Gruppe von Entwicklern geändert werden kann,
und diese Gesamtgruppe gesamt-verantwortungsvoll mit der Software umzugehen versteht, dann können die kleinen Wichtigkeiten
von denjenigen eingebracht werden, denen es wichtig ist. Letzlich gewinnt durch diese Art Demokratie in der Softwaregestaltung die Gesamtsoftware an Qualität. Intensionen mehrerer Entwickler könnten auch verschiedene Intensionen von Kunden gut abbilden.
Folgende Regeln sollten dabei beachtet werden:
Vorraussetzung ist eine Führung der Quellen der Software in einem Software-Versionssystem mit Checkout, Lock, Checkin, Merge-Möglichkeiten,
Dokumentation wer wann was geändert hat.
Es muss einen Verantwortlichen geben, der letzlich entscheidet, ob eine Änderung drin bleibt, nochmals modifiziert wird oder
so nicht erfolgen darf.
Änderungen müssen vor ihrer Ausführung an den Softwarequellen verbal abgesprochen sein.
Der Stil der Softwaregestaltung muss abgesprochen sein. Jeder muss sich an einen gemeinsamen Stil halten.
Werden diese Regeln beachtet, dann ergibt sich beispielsweise folgendes Änderungsszenario:
Person A sagt dem Verantwortlichen, Funktionalität X könne man besser so oder so gestalten. Der Verantwortliche hat dafür
zwar keine Zeit und kein Interesse, sagt aber "mach mal, ich schaue es mir dann an". Es wird vereinbahrt, auf welcher Softwarebasis
(Checkpoint der Quellen) aufgesetzt wird.
Person A führt die Änderungen aus, generiert die Software und testet den Erfolg. Beim Test werden die typischen Benutzer,
zunächst ein gegebenenfalls vorhandenes Testteam mit eingebunden und deren Meinung zur Änderung eingeholt.
Person A berichtet dem Verantwortlichen über den Erfolg. Es wird dann ein 4-Augen-Review über die Änderung in den Quellen
durchgeführt. Das kann relativ kurz sein, wichtig ist dass der Verantwortliche den Überblick behält und erhält. Gegebenenfalls
kann die Lösung dann noch gemeinsam verbessert werden.
Nach Begutachtung wird die Software in den Hauptzweig des Versionsmanagements übernommen und damit als feste Eigenschaft manifestiert.
Wenn diejenige Quelle nicht gleichzeitig von anderen Bearbeitern geändert wurde, ist das sehr aufwandsarm. Ansonsten muss
ein Mergen erfolgen.
2 Objektorientierte Programmierung
Topic:Programming.ObjectOrientiation
Bei der Objektorientierten Programmierung werden Daten in Objekten zusammengefasst. Nicht die Bearbeitung der einzelnen Datenelemente,
sondern die Bearbeitung eines Objektes aus Daten steht im Vordergund. Die Bearbeitung erfolgt mit Methoden. Datenobjekte können
aus verschiedenen Sichten angesprochen werden.
Dies ist der Kerngedanke der Objektorientierten Programmierung. Alle anderen Eigenschaften leiten sich daraus ab.
Die Objektorientierte Programmierung ist als Softwaretechnologie entstanden, nachdem die Strukturierte Programmierung sich
etabliert hatte. Die Strukturierte Programmierung schaffte es, Programmabläufe sinnvoll zusammenzufassen. Daten waren aber
immer noch vereinzelt. Es gab zwar die Möglichkeit, Daten ebenfalls in Strukturen zu verpacken (C-struct{...}), aber dennoch wurden die einzelnen Datenelemente immer noch direkt angesprochen. Das geht, wenn man 100 oder 1000 verschiedene
Datenelemente hat, und eine nicht allzu komplexe Software darum. Aber bereits in dieser Größenordnung sind die Folgen einer
Änderung in den Daten nicht immer zu überschauen. Wo wird denn nun dieses Datenelement alles noch verwendet? - uups, vergessen, dass die Typänderung dort einen Überlauf erzeugen kann... - Ach, damals wurde ja das auch noch dort verwendet, obwohl es eigentlich falsch ist - 2 Tage Intensivdebugging!. Das sind so die Momente, die die Entwicklung der Objektorientierten Programmierung vorangetrieben haben.
Topic:Programming.ObjectOrientiation.Object
2.1 Abstraktion in der Objektorientierung
Topic:Programming.ObjectOrientiation.abstraction
Die Abstraktion ist ein abgeleiteter Kerngedanke der ObjektOrientierung. Wenn man ein Objekt hat, dann kann man es aus verschiedenen Sichten ansprechen. Schulbeispiel: Ein Datensatz eines Mitarbeiters dient für das Lohnbüro der Gehaltsabrechnung, für einen Mailverteiler als Zuordnung zu Abteilungen
usw.. Das Objekt Mitarbeiterdaten wird also für verschiedene Zwecke gebraucht. Da liegt es nahe, allgemeine Zwecke und speziellere Zwecke zu unterscheiden.
Die Beispiele dazu sind dem praktischen Umgang mit den Dingen entlehnt. Dazu wieder ein Schulbeispiel: Auto. Ein VW-Polo ist ein Auto, ein Mercedes-C ebenfalls, ein LKW aber auch, je nachdem wie ein Auto definiert wird. Von einem Auto kann man bestimmte Dinge verlangen: Fahren mit einer angemessenen Geschwindigkeit, Kupplungspedal links, Bremspedal rechts,
usw. Das Auto ist die Abstraktion mehrerer möglicher Ausprägungen. Wenn man nur von A nach B kommen will, reicht es irgendein Auto zu haben. Will man dabei aber gleichzeitig präsentieren, dann sollte es schon ein spezialisierter Typ eines Autos sein, mit den erforderlichen Eigenschaften.
In Java und C++ wird die Abstraktion sprachlich syntaktisch unterstützt durch die Möglichkeit, Basisklassen zu formulieren
und davon abzuleiten oder zu erben. Unmittelbar syntaktisch formuliert wird also nicht eine Abstraktion, sondern eine Verwendung einer (...mehr oder weniger
abstrahierten...) Klasse. Dass diese abstrahiert ist, ist nicht syntaktisch festgehalten, sondern folgt den inhaltlichen Gedanken
des Programmierers. Er kann also gut oder weniger gut abstrahieren, ohne dass der Compiler dabei hilft.
Es gibt aber auch die unmittelbar syntaktische Abstraktion, eine Klasse die nicht unabgeleitet verwendet werden kann. In C++
ist das eine Klasse, die abstrakte Methoden enthält. Abstrakte Methoden haben keinen Body. Statt dessen steht =0; hinten bei der Methodendeklaration:
In Java ist es ähnlich, nur dass man hier noch das deutliche Schlüsselwort abstract definiert hat, dass es zu verwenden gilt. abstract muss sowohl als Modifier vor einer Methodendeklaration stehen als auch vor der gesamten Klasse. Damit ist der Klasse bei
ihrer Deklaration schon anzusehen, dass sie abstrakt ist. Also einfacher sichtbar. Eine abstrakte Klasse darf abstrakte Methoden
haben, muss aber nicht. Abstrakte Methoden sind aber nur in einer abstrakten Klasse zulässig:
In Java kann eine abstrakte Klasse nicht selbst instanziiert werden, sondern nur eine ihrer Ableitungen, auch wenn sie nur
nicht-abstrakte Methoden enthält. In C++ kann eine Klasse, die abstrakte Methoden enthält, und deshalb abstrakt ist, nicht
instanziiert werden. - Kleine Feinunterschiede.
Das Prinzip der Definition einer Sichtbarkeit verbessert die Pflegemöglichkeit der Software. Das ist der eigentliche Dreh-
und Angelpunkt.
Java kennt 4 Möglichkeiten der Sichtbarkeit:
private: Nur in der jeweiligen Klasse direkt ansprechbar, nicht in abgeleiteten Klassen
protexted: Auch in abgeleiteten Klassen ansprechbar, aber nicht von außen.
public: Beliebig ansprechbar
Ohne Kennzeichnung, bezeichnet als package private: Beliebig ansprechbar von anderen Klassen innerhalb des selben Packages, aber nicht aus anderen Packages.
C++ kennt die selbe Definition von private, protected und public. Das package private ist unbekannt, weil es nicht die Packagestruktur von Java gibt. Dafür gibt es aber eine friend-Beziehung. Damit lässt sich adäquates wie package private machen, bezogen auf beliebig auswählbare Klassen. In Fachkreisen ist die freizügige Verwendung von friend umstritten, weil das Konzept der Sichtbarkeit damit aufgeweicht wird und am Ende keiner mehr durchschaut. friend sollte nur an bestimmten Stellen verwendet werden.
Die Kennzeichnung mit final in Java ist auch eine Frage der Sichtbarkeit. Ein public final-Element lässt sich von überall her lesen, aber nirgends beschreiben. Man kann sich also sicher sein, dass es in unbekannten
Softwareteilen nicht verändert wird - eine wesentliche Feststellung beispielsweise bei einer Fehlersuche.
Auf Daten kann einfacher zugegriffen werdne, wenn diese public sind. Der Nachteil ist, wie bekannt, dass schlechter kontrolliert
werden kann, wo diese Daten benutzt werden. Also ist die Softwarepflege schwieriger.
Wenn die Klasse, in der die Daten (Java-Fields) benutzt werden, selbst aber wieder private oder protected ist, dann kann nicht
einfach eine Instanz dieser Klasse irgendwo anders angelegt werden. Damit ist die Sichtbarkeit wieder in erforderlichem Maße
beschränkt. Jetzt kommt es auf die Sichtbarkeit der Instanzen der private-Klasse an, die in der eigenen Umgebung angelegt
worden sind.
2.3 Wiederverwendbarkeit und Vererbung
Topic:Programming.ObjectOrientiation.reusing-debt
Eine der Vorteile, die man der Objektorientierung nachsagt, ist die Verbesserung der Wiederverwendung von Software. Man meint,
die Ableitung von einer fertigen Klasse, die in etwa passt, die speziellen Anforderungen hinzugefügt, das wärs. Das ist ein
einfaches aber falsches Verständnis von Wiederverwendung. Dazu das Schulbeispiel aus OO-Seminaren:
Man hat eine Klasse, die ein Quadrat beschreibt. Als Attribut ist die Seitenlänge enthalten. Nun möchte man ein Rechteck.
In der Quadrat-Klasse ist schon einiges enthalten, was man verwenden kann. Also ableiten von Quadrat, ein Attribut, die zweite
Seitenlänge hinzufügen, Formel zur Flächenberechnung überladen, fertig. So einfach kann Softwareschreiben sein, wenn man wiederverwendet. - In diesem Beispiel ist ein Rechteck ein Quadrat. Eine Ableitung bedeutet nämlich, dass die Eigenschaften der Basisklasse
alle mit geerbt werden, es entsteht eine is a- Beziehung. Ein Porsche ist ein Auto, ein Polo auch, beide sind von Auto abgeleitet.Ein Rechteck ist ein Quadrat, weil aus
Wiederverwendungsgründen abgeleitet?
Der Fehler besteht darin, dass die Wiederverwendung oft nur einige Aspekte Nutzen will, andere aber anpassen will oder erweitern.
Da passt es nicht, ein fertigen Teil zu nehmen. Richtiger ist es, Die Dinge so zu bauen, dass eine Allgemeingültigkeit formuliert
wird. Die Allgemeingültigkeit kann dann leicht auch für andere Zwecke verwendet werden. Richtig ist es also, nicht erweitern
sondern abstrahieren. Um beim Beispiel Rechteck/Quadrat zu bleiben. Da hat jemand die Aufgabe erledigt, eine Klasse Quadrat zu erstellen. Fertig. Im Hinblick darauf, dass zukünftig noch weitere ähnliche Klassen für Rechteck, Parallelogramm usw. notwendig sind, sollte von der konkreten Aufgabe Quadrat abstrahiert werden und eine Basisklasse Polygon erstellt werden. Diese hat dann eine Zugriffsmethode zur Flächenberechnung getArea() und eine zur Umfangsberechnung getPerimeter(). Diese Basisklasse wird verwendet, wenn allgemeingültig auf die erste Ableitung, das Quadrat, zugegriffen wird. Die selbe
Basisklasse wird dann für das Rechteck verwendet. Die verwendende Software ist also eher fertig, und die noch zu erstellenden
Teile haben ein gutes Grundgerüst. Das ist Wiederverwendung nicht eines fertigen Codes, sondern eines Konzeptes.
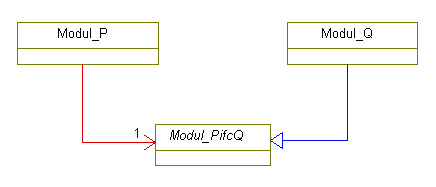
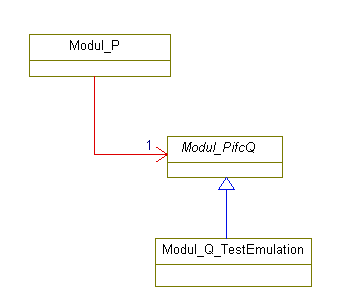
Wie im Kapitel über Interfaces noch gezeigt wird, ist es besser, nicht Reichtum, sondern Schulden zu erben. Gemeint ist damit, der Zwang zur Implementierung einer Zusage (Schuldenbegleichung) ist es, was Verlässlichkeit und Wiederverwendungsmöglichkeiten bringt. Die Zusagen sind die Eigenschaften von Basisklassen.
2.4 Das Interfacekonzept
Topic:Programming.ObjectOrientiation.interface
Das Interfacekonzept der ObjektOrientierung kann aus syntaktischer Sicht von C++ oder Java als eine Art der Abstraktion angesehen
werden. Es ist aber vom Grundansatz etwas anderes:
Interfaces sind Zugriffsspezifikationen. Mit Interfaces wird beschrieben, wie auf beliebige Objekte zugegriffen werden soll,
ohne etwas zu den Objekten selbst festzulegen. Die Objekte müssen das Interface dann implementieren, das heißt die Zugriffsspezifikation
irgendwie geartet erfüllen.
In C++ kann man diese Eigenschaft mit einer Klasse mit ausschließlich abstrakten Methoden nachbilden. Ausschließlich deshalb,
weil ein Interface ja selbst nichts implementieren soll sondern nur deklarieren. Eine ausprogrammierte Methode ist bereits
eine Implementierung. Man kann aber sprachsyntaktisch in C++ mischen, etwas schnell mal implementieren, obwohl die Klasse
als Interface gedacht war ... Der Compiler stört sich daran nicht.
Ein reines objektorientiertes Interface in C++ formuliert mit einer Klasse mit ausschließlich abstrakten Methoden hat also
keine Implementierung, kein zugehöriger obj-File. Interfaces werden nie selbst compiliert sondern werden includiert und verwendet.
Damit sind C++-Interfaces für den Datenaustausch mit Libraries geeignet. Die Libraries implementieren Interfaces, die Anwendungen
oder die Libraries selbst benutzen Interfaces. die Interfaces selbst sind aber nicht Bestandteile einer bestimmten Library.
Damit sind Libraries austauschbar.
In Java ist das Interfacekonzept in seiner reinen Form syntaktisch vorhanden. Es gibt Klassen, mit dem Schlüsselwort clazz, und gleichberechtigt Interfaces, mit dem Schlüsselwort interface. Der Versuch, in einem interface eine Methode zu implementieren, scheitert an der daraus resultierenden Compilerfehlermeldung. Man wird damit gezwungen, nach
den reinen objektorientierten Konzepten zu programmieren. Letzlich macht sich das in gut strukturierter und pflegbarer Software
bezahlt.
Java-Interfaces dürfen auch keine Daten enthalten, eine Zugriffsspezifikation ist nur eine Vertragsformulierung, ohne Inhalt.
Also gehören Daten dort nicht hinein. innerInterfaces innerClasses interfaceExtension
interface Example //Java
{ final double conversionValue = 234.4;
}
Das Schlüsselwort final kann man weglassen, es ist dennoch final. Schreibt man es hin, wird es für den Leser deutlicher.
3 Modularität in der Programmierung
Topic:Programming.ModulStructure
3.1 Module oder Komponenten
Topic:Programming.ModulStructure.ModulOrComponent
Komponenten werden im allgemeinen über den Modulen angesiedelt: Eine Komponente besteht aus mehreren Modulen. Die Komponenten
sollten eher eigenständig aufgefasst, funktionstüchtig oder zu gebrauchen sein. Von einem Modul muss man nicht voraussetzen,
dass es eine unabhängige anwenderorientierte Funktionalität besitzt.
Wo der Schnitt zwischen Komponente und Modulen ist, kommt aber ganz auf die Anwendung an. Das kann unterschiedlich sein. Eine
Einrichtung in einer Fertigungsstraße kann durchaus als Modul bezeichnet werden, aus Sicht der Gesamtfertigung. Daher wird in diesem Artikel der Begriff Modul allgemeingültig verwendet. Alle Aussagen betreffs Modul können auch auf Komponenten bezogen werden. Modularität ist eine allgemeingültige Herangehensweise. Begriffe wie Komponentenorientierter Softwareentwurf können in anderen Sachzusammenhängen durchaus ihre Berechtigung haben. Dieser Artikel bezieht sich auf das Zusammenspiel
von Softwareteilen insgesamt und allgemeingültig.
Man kann Klassennicht nur auf Fileebene definieren, sondern auch innerhalb einer anderen Klasse, innerhalb eines Interfaces
oder selbst innerhalb von Anweisungsblöcken in Methoden. Im letzten Fall ist die Klassen nur innerhalb des Anweisungsblockes
nutzbar. In den ersten beiden Fällen wird die innere Klasse über den Typ der umgebenden Klasse oder des Interfaces angesprochen:
class Example
{ class Innerclass
{ ... }
}
//using:
Example.Innerclass aInstance =
new Example.Innerclass();
Eine Klasse, die innerhalb eines Anweisungsblocks definiert ist, hat deutlich sichtbar nur einen begrenzten Einsatzzweck.
Eine solche lokale Klasse zu haben ist schon für bestimmte Fälle gut und hilfreich. Klassen fassen Daten zusammen oder kapseln
Daten:
void method(int x)
{ class TempValues
{ float a; double b;
}
//(in C würde man hier eine struct im Stack anordnen)
TempValues temp = new temp();
temp.a = x / Math.PI;
In dem hier konstruiertem Beispiel sollen ein paar zusammengehörige temporäre Werte gespeichert werden. Anstatt ein paar Variable
zu definieren, denen man die Zusammengehörigkeit nicht ansieht, ist es besser, eine lokale Klasse zu definieren. In C wäre
der maschinentechnische Aufwand (dort mit einer lokalen struct) exakt der selbe. In Java kann nur mit einem new eine Instanz creiiert werden. Diese liegt dann wahrscheinlich nicht im Stack (bei Realtime-Java gibt es hier Erweiterungen).
Private innere Klassen können selbstverständlich nur innerhalb der umgebenden Klasse instanziiert werden. Zweckmäßig ist dabei,
die Instanziierung im Konstruktur vorzunehmen, wenn es sich um eine composite-Beziehung handelt. In Java kann dann die Referenz
auf die innere Klasse final sein:
class ExampleOuter
{ protected static class ExampleInner
{ ...}
final ExampleInner role = new ExampleInner();
Im Beispiel ist die Instanziierung gleich in der Definitionszeile der Referenz ausgeführt, damit ist die kompositiorische
Bindung (composite) deutlich. Die selbe Schreibweise kann auch gewählt werden, wenn die innere Klasse nicht static ist. Implizit wird dann die Referenz auf die instanziierende Instanz, also die umgebenden Klasse, übergeben und gespeichert.
Auf diese Weise kann die nicht statische innere Klasse auf die Elemente der umgebenden Klasse zugreifen - so der Sprachgebrauch
aus statischer Programmierersicht. Sie greift natürlich nicht auf die Elemente einer Klasse zu, sondern auf die einer Instanz
der Klasse, die jenige,die das new ausgeführt hat.
Die Begründungen dafür, dass Funktionalitäten überhaupt in mehrere Klassen aufgeteilt werden sollten, ist hierfür die Basis.
Eine Aufteilung sei gewünscht oder angemessen. Es geht um die Frage der Benutzung innerer Klassen oder von eigenständigen
Klassen für diesen Zweck.
Oft erscheint es einfacher, in die eine Klasse, die man bereits hat, weiter alles hineinzupacken. Die Aufteilung in Klassen
ist ja bereits zuvor vom Softwarearchitekt durchdacht worden. Die Klasse wächst. Es kommt noch die eine oder andere Funktionalität
hinzu. Dann ist die Klasse so komplex, wie früher zu Zeiten der strukturierten Programmierung es ein ganzes Programm war.
Der Durchblick wird schwierig.
Die Aufteilung der Funktionalität, die im Design zunächst einer Klasse zugeordnet wurde, in nochmals weitere Klassen ist oft
im ersten Designentwurf so nicht sichtbar gewesen. Designentscheidungen für die Aufteilung in weitere Klassen müssen getroffen
werden. Die Komplexität ist aber gewachsen nicht etwa aus Entwurfsgründen oder wegen neuer Anforderungen, sondern weil die
Implementierung dies erfordert. Damit liegt die weitere Klassenaufteilung erstmal nicht auf dem Tisch des Softwarearchitekten.
Man sollte also zusammengehörige Klassenelemente: Attribute, Referenzen (Fields in Java) und Methoden in eine eigene Klasse
verschieben. Die Designentscheidung ist nun: Wird das eine innerere Klasse, oder eine weitere Klasse des Moduls. Man kann
zunächst innere Klassen bilden. Damit ändert sich nichts am Fileaufbau. Die Entscheidung kann hinausgezögert werden. Es ist
kaum schwierig, zunächst eine innere Klasse zu bilden und sie später als eigene Klasse im Package zu etablieren oder umgekehrt.
Nur wenige Handgriffe mit Unterstützung der Entwicklungsumgebung und des Compilers sind für die Korrektur dieser Entscheidung
notwendig. Die folgenden Punkte der Empfehlung der Benutzung einer extra inneren Klasse gelten damit an sich genauso wie für
die Empfehlung einer eigentständigen Klasse im Package:
Nachfolgend sind Gründe genannt, die für die Benutzung von Inneren Klassen anstatt eigenen Klassen sprechen. Dabei muss in
Java stark unterschieden werden zwischen
statischen Inneren Klassen: Diese sind lediglich in der Sichtbarkeit in einer anderen Klasse angeordent.
nicht statischen Inneren Klassen: Diese spielen eine Sonderrolle in Java, man kann direkt auf die Elemente der umgebenden
Klasse zugreifen, genaugenommen auf die Elemente der Instanz der umgebenden Klasse, die bei der Instanziierung der inneren
Klasse angegeben wurde.
3.2.1.2.1 Verschiedene Interfaces mit einer Klasse implementieren
Angenommen, eine Klasse besitzt die entsprechenden Funktionalitäten, um mehrere Interfaces zu implementieren. Man kann nun
diese Interfaces direkt implementieren, in dem man schreibt:
class MyFunctions implements Aifc, Bifc, Cifc{....}
Dann muss diese Klasse die Methoden aller Interfaces enthalten. Gibt es dabei Namensüberschreitungen, dann handelt es sich
entweder um gleiche Funktionalitäten, die zwar von diesen verschiedenen Interfaces unabhängig erfordert werden, aber nur einmal
implementiert werden. Andererseits hat man dann bereits ein Problem.
Eine andere Möglichkeit ist, mehrere nicht statische Innere Klassen zu definieren, die dann jeweils für bestimmte Interfaces
zuständig sind. Die Referenz auf die interfaceimplementierende Instanz ist dann nicht die Gesamtklasse, sondern es muss die
Referenz auf die entsprechende innere Klasse verwendet werden. Aber der funktionale Zusammenhang ist nicht geändert. Die Interfaceimplementierungen
können sich in beiden Fällen die Leistungsfähigkeiten der äußeren Klasse benutzen:
class MyFunctions
{ int data; //data, core functionality
/**The Interface-Implementer*/
Implementer_Aifc
{ int methodIfc()
{ return data; //access to outer-class
}
};
Aifc theAifc = new Implementer_Aifc();
}
Das Interface wird also von der umgebenden Klasse, und dort von der theAifc-referenzierten Instanz implementiert. Die Instanz selbst ist nicht weiter interessant und enthält auch keine eigenen Daten,
sondern dient lediglich dem Zugriff auf die äußere Klasse zwecks der Interfaceimplementierung. Diese Instanz enthält implementierungs-datentechnisch
einen outer-Zeiger.
Man kann auch darauf verzichten, diese Instanz zu benennen. Damit wird Schreibarbeit gespart und nichts namentlich definiert
was nur an einer Stelle benutzt wird. Der Code ist dann gut leserlich, wenn man dieses Konstrukt kennt und oft genug benutzt:
class MyFunctions
{ int data; //data, core functionality
/**The Interface-Implementer*/
Aifc theAifc = new Example_Ifc()
{ int methodIfc()
{ return data; //access to outer-class
}
};
}
Mit dieser sogenannten anonymen Klasse entsteht also genau das Gleiche.
Man kann zusätzlich noch einen Provider oder etwas ähnliches in der umgebenden Klasse unterbringen, damit man außen die Interfacereferenz
bekommen kann ohne dass man die Referenz auf den Implementierer kennen muss. Das wäre aber ein anderes Thema. Extrem ist das
folgende Konstrukt:
class MyFunctions
{ int data; //data, core functionality
/**Method gets the Interface-Implementer*/
Aifc getAifc()
{ return new Example_Ifc()
{ int methodIfc()
{ return data; //access to outer-class
}
}
}
}
Das Problem an dieser Lösung ist, dass sie zwar richtig ist aber nicht mehr gut überschaubar. Die Implementierung der Interfacemethode
verschindet in einer anderen Methodenimplementierung. Das ist in einem UML-Klassendiagramm nicht mehr darstellbar. Es fehlt
außen bereits schon die Information, dass das Interface implementiert wird. Es ist zu vieles implizit und nicht deklarativ.
Der Unterschied zur obigen Lösung ist weiterhin, dass bei jedem Aufruf der Zugriffsmethode auf die interfaceimplementierende
Instanz diese neu angelegt wird - meist ein unerhebliches Detail, manchmal Arbeit für den Garbage collector.
3.2.1.2.2 Kapselung von spezifischen Daten einer Klasse
Enthält eine Klasse mehrere private Daten, von denen bestimmte Daten sachlich stärker zusammenhängen, dann ist es zweckmäßig
diese in einer eigenen inneren statischen Klasse zusammenzufassen. Das geschieht nur aus Gründen der Struktrurierung. Der
Schreib- und Rechenzeitaufwand steigt. Vergleichbar ist dies mit dem Zusammenfassen von Daten in einer struct in C, anstatt sie flach ungeordnet nebeneinander zu legen.
Diese innere Klasse kann dann ein Keim für eine eigene Klasse sein. Zunächst kann man diejenigen Methoden, die ausschließlich
mit diesen zusammengefassten Daten arbeiten, in diese Klasse nach und nach hineinverschieben. Da eine solche Klasse statisch
sein soll, ist der Zugriff aus dieser Inneren Klasse heraus auf die umgebenden statische Klasse nicht möglich. Damit entsteht
eine erzwungene Ordnung. Verschiebt man eine Methode in die neue Klasse, die zwar meist mit den inneren Daten arbeitet, jedoch
noch auf andere Daten zugreift, dann wird man mit einem Compilerfehler belohnt. Man muss nun überlegen, ob und wie man gegebenenfalls
besser strukturiert. Es kann ja auch sein, dass die besagte Methode irgendwo überladen ist und mit abgespeckt in die Innere
Klasse passt und auch hineingehört.
Eine solche Innere Klasse kann dann auch sehr leicht nach außen geschoben werden. Man sollte dies dann tun, wenn die Klasse
unabhängig außen gebrauchsfähig ist oder geworden ist.
3.2.1.3 Gründe gegen die Benutzung innerer Klassen
Software entsteht oft in mehreren Schritten und Gedankengängen. Daher kann es sein, dass eine Klasse als Innere Klasse ausgeführt
ist, mittlerweile aber dafür die Begründung fehlt.
Wan sollte eine Klasse nicht als Innere Klasse ausgeführt werden?
Erster Grund: Wenn sie von außen genutzt wird, ohne dass der / die Nutzer einen Zusammenhang mit der umgebenden Klasse brauchen.
Wichtig in der Objektorientierung ist Kapselung und Unabhängigkeit. Die Nutzung einer inneren Klasse bedeutet, dass eine Abhängigkeit
mindestens bezüglich Quellcode zur umgebenden Klasse besteht. Wird der Quellcode (der Quellfile) geändert, dann muss geprüft
werden, ob dies nicht Funktionalitäten der Nutzung beeinflusst. Wenn der Quellcode aber an Stellen geändert wird, die überhaupt
nichts mit der Nutzung aus einer anderen Klasse heraus zu tun hat, so entsteht unnötiger Mehraufwand. Dieser ist vermeidbar,
wenn die betreffende außen genutzte Klasse nicht unnötigerweise eine Innere Klasse wäre.
Wenn dagegen ein Zusammenhang mit der äußeren Klasse besteht, der aber nicht eigentlich mit der Nutzung der Inneren Klasse
zu tun hat, dann besteht die Begründung gegen die Innere Klasse aus dieser Sicht nicht. Man muss dann anderweitig abwägen.
Zweiter Grund: Wenn die innere Klasse selbst eine komplexe Funktionaltiät hat, die neben der Funktionalität der umgebenden
Klasse besteht, dann sollte eine Trennung erwogen werden. Die Trennung ist auch dann günstig, wenn die Funktionalitäten von
Innerer und umgebender Klasse zusammenhängen. Man kann trennen und beide Klassen über eine Aggregation verbinden.
Die Pflege der unabhängigen komplexen Funktionalitäten (Fehlerkorrektur, Erweiterungen) erfolgt damit in verschiedenen Quellfiles,
was für eine Nachvollziehbarkeit in einem Source-Konfigurationsmanagement günstig ist. Ein anderer wichtiger Grund ist auch
die Überschaubarkeit. Wenn man mit der Editierung der umgebenden Klasse beschäftigt ist, kann es eher wegen der komplexen
Innere Klasse zu Verwechselungen kommen.
3.2.2 Spezialinterfaces für jeden Zweck oder allgemeine Interfaces
Der Kapitelüberschrift folgend: Die Wahrheit liegt wie oft in der Mitte.
Wenn man für jede Assoziation von Klassen, die eines Interfaces bedürfen, ein spezielles Interface erfinden, dann würde man
für ähnliche, fast oder vollkommen gleiche Arten der Verbindung zwischen Verschiedenen Partnern jeweils eigene Interfaces
haben. Wie das Software-Leben so spielt wären diese sicherlich nicht gleich, auch nicht fast gleich, aber beim dritten bis
fünften Hinschauen fragt man sich, ob das nicht besser sein könnte.
Das richtige Designen der Interfaces muss unabhängig vom Designen der Beziehungen zwischen Klassen erfolgen. Dazu muss man
sich in Erinnerung rufen, das Interfaces nicht die Beziehungen selbst darstellen sondern so etwas wie ein Vertragsformular
sind. Einen Auto-Kaufvertrag kann man sehr verschieden gestalten, abhängig davon wer von wem kauft und welche Formulierungsgewohnheiten
er hat. Es geht aber immer um dieselben Dinge. Schon damit man nichts vergisst, ist ein allgemeingültiges Formular so schlecht
nicht.
Wenn man für ein Modul ein Provider-Interface und für alle Assoziationsaspekte die passenden Interfaces als innere Interfaces
des Modulinterfaces bereits designed hat, wird man es mit der Allgemeingültigkeit bestimmter Interfaces es schon schwer haben.
Da hilft nur: Software umschreiben. Das ist nicht schwierig. Aus konkreten Festlegungen lässt sich besser abstrahieren, dann
muss man nur Umbenennen, Umschieben und Löschen. Eine Arbeit, bei der beispielsweise Eclipse und der Java-Compiler hilft.
Ein Interface für alles ist das Gegenteil. Dieses Allgemein-Interface kann es nur geben, wenn das Ansinnen, der Aspekt, Allgemeingültigkeit
hat. Solche allgemeinen Interfaces sind bespielsweise java.util.List.
Für abstrakte und Basisklassen gelten ähnliche Überlegungen.
3.2.3 Interface- und Klassendefinition innerhalb von Interfaces
Genauso wie es innerhalb von Klassen die Möglichkeit der Definition von inneren Klassen oder Interfaces gibt, gibt es auch
bei Interfaces diese Möglichkeit. Die Frage, die es hier zu beantworten gilt, ist:Welchen Zweck kann dies haben?
In erster Linie ist das eine Strukturierungsmöglichkeit. Bei Klassen gibt es die nicht-static-Variante. in diesem Fall kann aus einer Instanz der innereren Klasse alle Elemente der äußeren Klasse benutzt werden. Bei
Interfaces gibt es dies nicht, weil es keine Implementierung gibt, also niemand benutzt. Demzufolge ist das immer wie static. Eine Sichtbarkeit ist ebenfalls kein Grund. Methoden in Interfaces sind immer public. Eine private-Klasse innerhalb eines Interfaces würde niemand benutzen können. Also verbleibt tatsächlich nur der Grund der Strukturierung.
Interfaces sind Sichten für einen Zugriff. Wenn man nur 2 Klassen hat, dann können diese bereits mit mehreren Interfaces assoziiert
sein. Warum mehrere? Weil die Klassen gegebenenfalls mehrere Dinge tun, es also mehrere Gründe der Verbindung gibt. Damit
Ordnung in die Software kommt, soll man nicht alles vermixen sondern jeden Aspekt mit einem eigenen Interface versehen. Wenn zwei Ehepartner beide in der gleichen Firma arbeiten, dann haben sie auch zwei verschiedene Aspekte der Verbindung. Die
Vermischung des einen mit dem anderen tut oft nicht gut.
Wenn mehr als 2 Klassen miteinander assoziiert sind, dann arbeitet die eine Klasse sicherlich aus anderen Aspekten mit einer
anderen zusammen als die dritte. Hier empfielt es sich ebenfalls, für jeden Aspekt ein eigenes relativ kleines Interface zu
benutzen. Das dokumentiert, wie die Klassen zusammenarbeiten. Die Softwarepflege ist damit wesentlich erleichertert. Eine
Klasse kann problemlos mehrere Interfaces implementieren. Enthalten diese die gleichen Methoden, dann werden diese Methoden
mit nur einer Methode implementiert. Eine Überschneidung von Funktionalitäten der Beziehung ist also kein Problem.
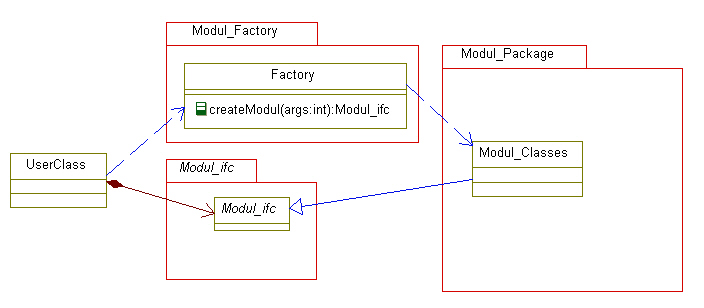
Es kann sein, dass ein Modul mehrere Klassen enthält, die mehrere Interfaces implementieren. Wenn das Modul von außen angesprochen
wird, kann es günstig sein, dass es einen Interface-Provider gibt. Damit gibt das Modul insgesamt seine Interfaces nach außen
und braucht nur mit einer Assoziation außen bekannt zu sein:
Das Provider-Interface wird von der Fassadenklasse des Moduls implementiert. Im Modul können diese Interfaces von verschiedenen
Klassen implementiert werden. Das ist bereits ein notwendiger Grund für mehrere Interfaces.
Damit gibt es aber eher mehr Interfaces. Interfaces. Interfaces die irgendwie zusammengehören, können nun unter dem Dach eines
gemeinsamen (Dach-) Interfaces zusammengefasst werden. Das oben gezeigte Provider-Interface kann beispielsweise die einzelnen
Interfaces des Moduls aufnehmen.
In C hat man bezüglich Arrays recht einfache Konstrukte: Ein Array ist eine Folge von Daten gleichen Typs im Speicher hintereinander.
Bei der statischen Anlage von Arrays, egal ob global, stacklokal oder innerhalb einer struct gibt man in [] einfach die Anzahl der Elemente an:
ArrayElementType exampleArray[123]; //statisches Array in C
Der Bezeichner exampleArray wird vom Compiler damit automatisch als ein Zeiger auf den Typ eines Elementes des Arrays geführt. Das ist praktisch und
nützlich, aber gegebenfalls manchmal etwas verwirrend. Der Bezeichner einer ähnlich zu definierenden Struktur struct {...} name wird vom Compiler nicht als Zeiger sondern als die Instanz selbst interpretiert.
Der Zugriff auf die Array-Elemente ist auf zweierlei Weise möglich. Entweder man folgt der Interpretation des Namens des Arrays
als Zeiger und kann also mit dem * davor auf das erste Element zugreifen, mit der üblichen Zeigerarithmetik damit auch auf alle anderen. Oder man schreibt intuitiv
besser für den Zugriff den Index in Klammern:
*(exampleArray+12) == exampleArray[12]
Der als Beispiel gezeigte Vergleich wird auf die Inhalte der Elemente ausgeführt, da beide Ausdrücke links und rechts das
Element selbst bezeichnen.
Dynamische Arrays in C kann man sehr einfach mit alloc anlegen. Dabei hilft, dass der Zugang zu einem Array nichts anderes als ein simpler
Zeiger auf den Array-Element-Typ ist. Ein wenig casting ist erforderlich, weil das Allokieren selbt typfrei ist. size ist die erforderliche Anzahl der Feldelemente.
In C++ hat man zunächst genau die selben Möglichkeiten wie in C, simple aber mit all den Problemen. Zusätzlich gibt es in
C++ üblicherweise noch einige Library-Klassen, meist mit Templates, die Arrays in einer objektorientiert genehmen Weise verwalten.
Hier büst man aber wiederum die Einfachkeit ein. Wie ein Template ein Array anlegt, ist dann nicht mehr simple. Daher wird
man in vielen Fällen es doch wieder simple und easy C-like machen.
Bezüglich des Compilerens gibt es außer den Irritationen Zeiger oder nicht keine Probleme. Aber zur Laufzeit können sich erhebliche
Probleme ergeben, wenn man nicht sorgfältig genug codiert:
Keine Längenüberprüfung: Per se kann man mit den Array-Zeigern beliebig herumoperieren, alles wird compiliert und läuft irgendwie. Sowohl exampleArray[-1] geht als auch ein zu großer Index. Es wird halt im Speicher herumgegriffen. Ein solcher Fehler wird gegebenenfalls nicht
bemerkt, wenn halbwegs plausible Werte gelesen werden oder wenn irgendwohin fälschlicherweise geschrieben wird, wo es (zunächst)
nicht auffällt. Das Problem sind ja nicht die konstanten Indizes, sondern berechnete Werte oder von außen erhaltene Werte.
Eine gute Programmmierung wird von außen erhaltene Indexwerte grundsätzlich überprüfen ("Wareneingangskontrolle"). Wenn die
Werte für den Index jedoch innerhalb gebildet werden, kann auch die Richtigkeit des Algorithmus feststellbar sein, eine zusätzliche
Überprüfung bei jedem Zugriff auf Array-Elemente ist dann sicherlich übertrieben. Am einfachsten lässt sich das mit einer
Laufanweisung überprüfen:
Fallen bei der Pointerarithmetik: Der Ausdruck exampleArray+7 bezeichnet die Adresse des 7. Elelentes des Arrays. Der Compiler berücksichtigt automatisch die Byteanzahl des Typs und multipliziert
diese mit rein. Das ist ganz nett. Was ist, wenn man beispielsweise *exampleArray+7 schreibt und denkt, den Inhalt des 7. Elements zu bekommen. Das ist ein dummer Fehler, Klammenr vergessen! Aber fällt das
auf? Weitere beliebige Verwechselungsmöglichkeiten gibt es, das liegt daran das Pointerarithmetik mit numerischer Artithmetik
durcheinandergebracht werden kann, ohne dass es der Compiler merkt. Nur der sorgfältige Leser und Tester des Programmes könnte
es bemerken, wenn er Klammern richtig zählt.
Wo steht die Länge des Array: Für Indexüberprüfungen oder Laufanweisungen muss man die Länge kennen. Die steht aber irgendwo. Damit gibt es eine Verwechslungsgefahr.
Am einfachsten ist das mit statisch definierten Arrays. Hier hilft der sizeof()-Compilerbefehl. Er ermittelt die Byteanzahl
eines Arrays, wenn man den Instanzbezeichner angibt. Das tut er so, obwohl der Instanzbezeichner bei Verwendung für einen
Zugriff ein Zeiger ist. Mit einer kleinen Arithmetik:
int nrofElements = sizeof(exampleArray) / sizeof(exampleArray[0]);
kann man die Anzahl der Elemente ohne weitere Hilfsmittel bestimmen. Die daraus sich ergebende Konstante wird zur Compilerzeit
berechnet. - Das funktioniert aber nur bei statischen Arrays.
In Java hat man bei der Sprachschöpfung die Probleme, die seit 20 Jahren in C bekannt gewesen sind, berücksichtigen können.
Ein Array in Java wird von der Syntax/Semantik her ähnlich notiert wie in C, ist aber von vornherein etwas komplexer:
Das ist ein einfaches int-Array mit 12 Elementen. Auffallend ist die Notwendigkeit des Operators new. Ein Array wird nicht einfach im Stack angelegt, oder innerhalb einer Klasse, oder global, sondern so wie in java üblich
immer über den Heap.
Die eckigen klammern können in Java wie in C/C++ hinter dem Instanzenbezeichner notiert werden. Möglich, üblich und besser
ist die Notation hinter dem Typ. Der Typ wird als Array qualifiziert:
int[] exampleArrayInt = new int[12];
Der Zugriff auf Array-Elemente erfolgt wie in C mit eckigen klammern. Eine alternative Zeigerartithmetik gibt es aber nicht:
int value7 = exampleArrayInt[7];
Der Bezeichner exampleArray referenziert das Array. Dieses Array hat eine Kopfstruktur, die von java.lang.Object abgeleitet ist. Außerdem ist dort die Länge des Arrays gespeichert:
int length = exampleArrayInt.length;
Die Länge ist also am Array immer richtig gespeichert. Bei einem Zugriff wird der Index gegen die Länge gecheckt. Das erfolgt
immer, der Anwender kann hierbei nichts vergessen. Allerding wird nicht immer Rechenzeit verbraten. Dazu gibt es schließlich
intelligente Vorverarbeitungen wie JIT (Just in Time-Compiler). Dabei werden Optimierungen ausgeführt.
Arrays aus strukturierten Daten, in Java sind das Klassen, sehen erstmal so ähnlich aus wie Arrays aus simplen (skalaren) Daten:
Typ[] exampleArray = new Typ[12];
Hier werden aber nicht etwa 12 Instanzen von Typ angelegt, sondern nur 12 Referenzen auf mögliche Instanzen, die also mit null initialisiert sind. Die Instanzen selbst muss man dann mühevoll in einer Schleife anlegen:
Das erscheint zweckfrei, wenn man genau diesen Typ ohne weitere Parameter braucht. Aber selbstverständlich sind auf den 12
Speicherplätzen des Arrays auch Referenzen auf abgeleitete Typen speicherbar, außerdem jeweils mit verschiedenen Initialwerten
(Konstruktor-Argumenten). Das sind Grundeigenschaften der Objektorientierung, die immer gehen müssen. Nur der simpelste Fall
hat gegenüber der Einfachheit von C diesen gezeigten Grundaufwand:
for(int idx = 0; idx < exampleArray.length; idx++)
{ Data data = Database.getData()
if(data.testX) { exampleArray[idx] = new TypX(data.getValueX()); }
else { exampleArray[idx] = new TypY(data.getValueY()); }
}
In diesem Beispiel muss also TypX und TypY beide von Typ abgeleitet sein. Angelegt wrid der abgeleitete Typ. Gespeichert wird
aber die Referenz auf den Grundtyp. Mit den Möglichkeiten des dynamischen Bindens (dynamischer Methodenaufruf) werden die
jeweils richtigen Operationen ausgeführt.
Ein mehrdimensionales Feld aus simplen (skalaren) Typen sieht wie in C aus und wird wie in Java üblich adäquat angelegt:
int[][] exampleArray2Int = new int[12][15].
Der Zugriff wird genauso wie in C geschrieben:
int value = exampleArray2int[7][3].
Schreibt man
int[] vector = exampleArray2int[7];
dann erhält man das eindimensionale Array, das auf der 2. Dimension auf der 7. Position steht. Dessen Länge kann ausgelesen
werden, dieses Array kann als Instanz des int[]-Typs weiterverarbeitet werden. In C würde man einen Zeiger auf irgendwie das erste Element der 7. übergeordneten Dimension
bekommen, oder, wenn man das Array sich im Speicher flach vorstellt, einen Zeiger auf das 7*15 Element. Wieviel Elemente
dazugehören, ... muss man irgendwo selbt programmieren.
Bei Arrays aus strukturierten Typen sieht das grundsätzlich genauso aus.
Schreibt man einen Algorithmus in Java und übersetzt ihn mit dem Java2C-Translator nach C, dann bekommt man etwas in C gut
anwendbares mit Java-like touch, nämlich Arrays mit einer Kopfstuktur. Für die Implementierung von einfachen strukturierten
Daten sind aber die C-Gepflogenheiten berücksichtigt. Das wesentliche dabei ist, dass man in embedded Anwendungen die Daten
nicht irgendwo in einem Heap verstreut haben will, sondern gegebenenfalls in bestimmten Speicherbereichen und jedenfalls zusammen.
Das kann man (fast) mit Java-Standard-Sprachmitteln ausdrücken:
final int embeddedArrayint = new int[123];
/** @Java2C=embeddedArrayElement. */
final Type[] embeddedArray = new Type[12];
Das embeddedArrayint kann und wird deshalb an dieser Stelle nicht referenziert sondern wird innerhalb der Struktur angelegt, weil seine Größe
auch in Java feststeht. Da die Elemente simple, skalar sind, wird kein anderer Speicherbereich allokiert, alles liegt beieinander.
Bei dem embeddedArray aus strukturierten Daten kann mit den reinen Sprachmitteln an dieser Stelle nicht sicher entschieden werden, ob auch die
Array-Elemente embedded sein können. Sie werden in Java hier noch nicht initialisiert. Daher ist eine Hilfe angebracht, die
gezeigten @java2C=-Annotation im Kommentar. Wenn dann in der weiteren Programmierung dazu ein Wiederspruch auftreten sollte, darf das der Java2C-Translator
als Fehler melden, obwohl es in Java ginge. Beispiel dafür ist die für Java gezeigte Initialisierung mit einer abgeleiteten
Klasse. Das geht dann nicht. Man muss sich also entscheiden: Möchte man ein einfaches Speicherlayout, dann kann man auch nur
einfache Strukturen anlegen. Im embedded Bereich passt das aber meist miteinander.
Man hat also Kopfdaten mit der Länge, und danach die Feldelemente, zusammengefasst in einer Gesamt-Struktur.
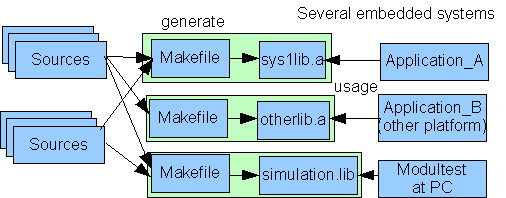
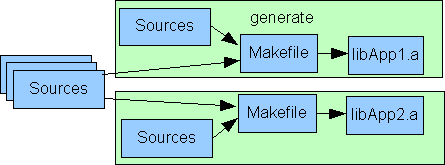
3.3 Verknüpfung von Modulen
Topic:Programming.ModulStructure.ModulConjunction
Es gibt mehrere Möglichkeiten der Verknüpfung von Modulen, die zunächst unabhängig entwickelt werden. Die Verknüpfung muss
spätestens zur Laufzeit bei Notwendigkeit vorhanden sein. Gegebenfalls ist eine feste Verknüpfung bereits beim Start einer
Applikation oder Anlage erwünscht, möglicherweise aber schon bei der Erstellung. Man spricht hier von früher oder später Bindung.
Die Verknüpfung von Modulen ist unter verschiedenen Gesichtspunkten zu betrachten. Erstens abhängig von der frühen oder späten
Bindung, zweitens abhängig davon, was unter einem Modul verstanden wird, ob es eine feste räumliche Beziehung gibt oder Module
verteilt komminizieren müssen, drittens hängt es auch von den Konkreta der technischen Ausgestaltung ab. Nachfolgend sind
gängige Mittel und Praktiken genannt, die jeweils ihr Anwendungsgebiet haben.
Die Verbindung von Modulen kann als eng oder weit betrachtet werden, mit folgenden Kriterien:
Anordnung in einer Executable, statisch oder dynamisch gelinkt.
Anordnung in einer Hardwarekomponente, in verschiedenen Executables, aber mit einem gemeinsamen Speicher, Abarbeitung vom
selben Prozessor möglicherweise mit mehreren Cores.
Anordnung in Hardwarekomponenten, die direkt hardwaretechnisch miteinander verbunden sind, aber verschiedene Speicher haben
(verschiedene Prozessoren).
Verteilte Anordnung in einer Anlage oder räumlich stärker getrennt.
Die enge oder weite Bindung hat entscheidende Auswirkungen auf die Beständigkeit der Schnittstellengestaltung. Module, die
in einer Executable zusammengelinkt sind, müssen nur für den Buildprozess dieser Executable passende Schnittstellen haben.
Spätere Builds können auch die Schnittstellen ändern, wichig ist nur das man immer zueinanderpassende Revisionen linkt. Dabei
können formelle Tests sicherstellen, dass alles korrekt ist. - Anders bei weiter Bindung. Hier kann ein Anwender auch beliebig
austauschen oder mixen. Daher ist eine Schnittstellenverträglichkeit über viele Versionen notwendig. Wenn das Zusammenspiel
immer nur für bestimmte Versionen getestet und freigegeben ist und mit anderen Kombinationen in der Tat nicht funktioniert,
ärgert man die Anwender.
Abhängig von enger oder weiter Bindung, statischem oder dynamischen Linken kommt der Schnittstellengestaltung eine höhere Bedeutung zu als der Funktionalität. Schnittstellen müssen/sollten auf Jahrzehnte kompatibel oder abwärtskompatibel bleiben. Positives Beispiel dafür ist das
sonst oft kritisierte Betriebssystem MS-DOS und MS-Windows. Wenn man Schnittstellen festlegt, dann kann man Slots für die
Zukunft einplanen und offenhalten, die zunächst nicht oder nur formell funktionell realisiert werden. Der Softwareentwurf
muss sich mit den Schnittstellen beschäftigen, nicht mit den kleinlichen Details der Funktionalität. Das kommt danach - und
gehört selbstverständlich zu einem abgerundetem Ergebnis. Aber wenn die Schnittstellen nicht gut durchdacht sind, gibt es
zunächst den schnellen Erfolg mit nachfolgenden Desaster in den darauf folgenden Jahren.
Statisches Linken ist der klassische Weg und bereits bei der Assemblerprogrammierung gängige Praxis. Das Prinzip wurde dann
in C übernommen, C ermöglicht das Einbinden von Assemblerprogrammen mit in C formulierten Schnittstellen.
Bei der Compilierung oder Assemblierung entstehen Objectfiles. Diese enthalten als Ergebnis der Übersetzung den Maschinencode
und dazugehörige Symboltabellen. Es gibt Symbole (Labels), die benötigt werden (external) und Symbole, die in diesem Objectfile bereitgestellt werden (public). Die Labels bezeichnen Speicheradressen, entweder für den Startpunkt einer Subroutine oder für einen Speicherbereich (struct, external Variablen).
Der Linker bringt diese Labels zueinander. Etwas, was irgendwo benötigt wird, muss von einem anderen Objectmodul bereitgestellt
werden. Da die Objectmodule in ihrem Maschninencodeanteilen oder Datenbereichen aneinandergehängt werden, ist dann auch die
Adresse, die dem Label zugeordnet wird, bekannt. Bei der Adressbildung muss noch ein Offset für die Ladeadresse berücksichtigt
werden, das soll aber nicht hier detailliert behandelt werden (Locater). Die gebildetet Adresse eines Labels wird dann an
den Stellen, an denen das Label benötigt wird, in den Maschinencode eingetragen. Damit wird der Maschninencode komplettiert,
die Module, hier Inhalte von Objectfiles, sind mit den festen Adressen verbunden. Die Subroutinen aus anderen Modulen können
nun direkt ausgeführt werden, auf die Daten kann direkt zugegriffen werden.
Die andere Aufgabe des Linkes ist, Objectmodule zu sortieren. Das ist insbesondere für Anwendungen im Embedded-Bereich, wo
verschiedene Prozessoren und differenzierte Speicherorganisationsbedingungen vorliegen, entscheident. Auf einem PC ist Speicher
im Allgemeinen reichlich und gleichartig vorhanden. In einer Embedded-Hardware gibt es ROM (Flash)-Speicher auf bestimmten
Speicheradressen, bestimmte RAM-Bereiche, möglicherweise intern im Prozessor mit schneller Zugriffszeit und zusätzlicher Speicher
außen, aber langsamer. Dazu kommen Dual-Port-RAM-Bereiche für die Kopplung mit anderen Hardwarebestandteilen und FPGA-Adressbereiche
oder andere Memory-Mapped-IO-Bereiche. Die Speicherbereiche haben also verschiedene Eigenschaften, Daten und Programm müssen
passend dort plaziert werden.
In C werden die Labels aus den Identifier der jeweiligen Elemente gebildet, als aus den Namen der Routinen und dem Namen der
Datenelemente. In der Regel wird ein Unterstrich vorangestellt, um einen eigenen Namensraum gegenüber manuell in Assembler
vergebenen Labels zu bekommen.
Ob ein Label extern ist, stellt der Compiler selbst fest: Dann wenn es benutzt wird aber nicht definiert wird. Die extern-Deklaration im Headerfile ist nicht direkt dafür verantwortlich, siehe übernächsten Absatz.
Namensräume für Labels: Wenn man Bezeichnungen von Routinen und Daten nach belieben ausführt, dann ist die Wahrscheinlichkeit einer doppelten Benutzung
des selben Labels etwa im mittleren Bereich, muss nicht auftreten. Aber die Gefahr eines Konfliktes ist hoch. Dieser kommt
meist dann, wenn man nicht damit rechnet und ihn nicht gebrauchen kann: Bei kleinen Softwarekorrekturen wegen Bugs. Man bindet
nur schnell noch ein anderes Modul hinzu, das die korrekte Funktion enthält, aber man wusste vorher nicht, dass der Kollege
X die selben Bezeichner für andere Sachen genutzt hat.
Um nicht alle Bezeichner eines Programmes in den Konfliktbereich der doppelten Labels zu bringen, hat man in C mit dem Schlüsselwort
static:
static struct XY data;
static int myRoutine(){...}
die Möglichkeit erfunden, diese Bezeichner nicht als externe Labels in die Sichtbarkeit des Linkers zu bringen. In Assembler
gibt es die Möglichkeit ebenfalls, mittels Weglassen der global-Bezeichnung.
Es gibt in C für die Namenskonflikte keine allgemeingültige Lösung. Üblich ist es oft, alle Bezeichnungen für global sichtbare
Funktionen und Daten mit einem Prä- oder Postfix zu kennzeichnen. Wenn der Prä- oder Postfix projektweit abgestimmt ist, dann
ist dies das Mittel der Namensraumvergabe.
In C++ hat man einiges für die Label-Namensräume getan: Die Labels werden hier nicht mehr aus den einfachen Bezeichnungen gebildet, sondern sind wesentliche länger. Bestandteile
des Labels ist der Klassenname, in deren Kontext eine Routine oder static Daten definiert wurden. Damit brauchen nur noch
die Klassen eindeutig gekennzeichnet sein. Um auch dort Konflikte zu vermeiden, hat man den namespace erfunden: Klassen werden einem benannten namespace zugeordnet, der ebenfalls Bestandteil des Labels ist. Damit braucht projektweit nur noch der namespace abgestimmt werden. Doch was ist, wenn man Quellen aus einem anderen Projekt übernimmt? Eine weltweit eindeutige Abstimmung
ist nicht angedacht (im Gegensatz dazu bei den Java-Packages schon).
Bestandteile des Labels von Methoden sind auch die Typen der Parameter. Damit sind die gleichnamigen aber parameter-unterschiedenen
Methoden möglich.
Letzlich enthält ein Label in C++ noch einige Einstellungen der Art des Aufrufes von Methoden. Damit wird verhindert, dass
Fehler entstehen, wenn verschiedene Module mit verschiedenen Compilierungsoptionen zusammengebunden werden, die an sich nicht
zusammenpassen. Das ist nicht vordergründig ein Problem des Namespaces, aber nutzbar: Man kann dem Linker verschieden compilierte
aber sonst inhaltsgleiche Objectfiles anbieten, er findet das passende.
Die somit gebildetete Labels sind unlesbar-lang, werden aber vom Linker ansonsten genauso wie in C verarbeitet. Man kann bei
Linkerfehlern auch die Labels selbst analysieren, zumindestens in Object- oder Libraryfiles textuell suchen.
Die Deklaration von Daten und Methoden in Headerfiles hat für Labels und Linken keine Bedeutung:
Die extern-Deklaration von Daten oder ein Funktionsprototyp in einem Headerfile erzeugt keine extern-Deklaration dieses Labels im Objectfile,
sondern dient der Überprüfung des Bezeichners beim Compilieren. Sonst würden viele deklarierte Bezeichner von includierten
Headerfiles mit nicht benötigten Bestandteilen den Objectcode aufblähen, tun sie aber nicht. Nicht benötigte Quellzeilen mit
Deklarationen beschäfttigen nur den Compiler mit Rechenzeit, hinterlassen sonst keine Spuren. Der Compiler prüft die Rechtmäßigkeit
eines Bezeichners mit der Deklaration. Ansonsten gilt die Regel: Nur ein irgendwo benötigter Bezeichner wird als extern im Objectfile eingetragen.
Bei der Compilierung ist ein Modul einem anderen zunächst nur als Schnittstelle über den Headerfile bekannt. Die tatsächliche
Verbindung schafft dann der Linker, indem die Aufrufadresse von Routinen oder die Speicheradresse von statischen Daten an
den Aufrufstellen eingetragen wird. Klassisch in C ist das sehr einfach. Maßgebend ist der Name der Routine/der Daten. Der
Linker sucht aufgrund des Vorkommens des Namens in einem beliebigen Object-Modul. Falls irgendwas mit diesem Namen gefunden
wird, dann ist es das. Damit sind aber Fehler möglich. Wenn ein vollkommen falscher oder etwas falscher Headerfile beim Compilieren
benutzt wurde, dann merkt dies der Linker nicht. Man hat dann Datensalat oder Abstürze, die schwer zu finden sind. Daher
wird in C++ das Linklabel nicht einfach aus dem Namen der Routine/der Daten gebildet, sondern enthält weitere Bestandteile.
An sich ist das ein Nebeneffekt der Tatsache, dass der einfache Routinenname sowieso nicht ausreicht, sondern mindestens noch
die zugehörige Klasse. Außerdem müssen Routinen mit verschiedenen Argumenttypen aber gleichem Namen als verschiedene Routinen
erkannt werden. Passen Headerfiles nicht zu Objectmodulen, dann hat man eine größere Chance, dies als Linkerfehler zu bemerken.
Bei der Compilierung werden Segmentnamen vergeben. Damit kann der Linker gleichartige Daten oder Maschinencode aus verschiedenen
Object-Modulen miteinander in einem Speicherbereich vereinen, andere Daten oder Maschinencodes dagegen in den dafür geeigneten
Speicherbereich bringen.
Einem C/C++-Programmierer für den PC begegnen die Segmentnamen nur, wenn er in Dialogboxen hineinschaut, die er meist nicht
braucht. So wie beispielsweise bei dem legendärem Visual-Studio 6 im Dialog
Die Headerfiles enthalten Deklarationen, die dem Compiler ermöglichen, die Richtigkeit einer Verwendung oder einer Definition
zu überprüfen. Damit stellen die Headerfiles für C und C++ die wesentlichsten Schnittstellen der Module dar.
In der Anfangszeit von C war eine Vorwärtsdeklaration von Methoden nicht unbedingt notwendig und wurde auch nicht praktiziert,
wenn eine Methode nur int-Parameter hatte. Jetzt noch ist eine fehlende Vorwärtsdeklaration in C nur eine Warning wert. In C++ ist eine fehlende Deklaration dann endlich ein Compilerfehler. Diese Herangehensweise - automatisch deklarieren
wenn benutzt - war in den Anfängen der Softwareentwicklung üblich: BASIC, PL1. Man wollte Schreibarbeit sparen und die Programme
waren noch zu überschauen.
Eine Verbindung der Module mittels statischem Linken ist möglich, auch wenn es grobe Fehler in den Headerfiles und bezüglich
deren Verwendung gibt. Der Linker arbeitet nicht auf Basis von Informationen in den Headerfiles, sondern kennt nur Labels.
In C kann nicht festgestellt werden, ob eine Subroutine mit einem bestimmten Namen (Label) korrekt aufgerufen wurde. In C++
gibt es diesbezüglich Verbesserungen. Hier werden die Label-Namen aus mehreren Eigenschaften der Definition der Methode oder
der Daten zusammengesetzt.
Nur die richtige Verwendung von Headerfiles sichert, dass der Linker nur Passendes zusammenbindet. Das geschieht aber dadurch,
dass der Compiler unter Kenntnis der Deklarationen nur zueinander passende Labels bildet.
3.3.3.1 Korrekte Formulierung und Nutzung von Headerfiles
Bezüglich der korrekten Formulierung und Nutzung von Headerfiles beziehungsweise Deklarationen werden häufig grobe Fehler
gemacht, die aber oft Programmierern nicht so auffallen oder nicht im Bewusstsein liegen. Solche Fehler sind:
Fehler: Deklaration des selben Elementes in verschiedenen Headerfiles oder in einem C-File direkt. Meist wird copy'nPaste
verwendet und die Deklarationen sind identisch. Dann ist nichts falsch. Aber bei Softwareänderungen können Deklarationen vergessen
werden zu korrigieren. Dann laufen die Deklarationen auseinander. Ein Fehler fällt oft nicht sofort funktional auf, sondern
dann wenn man beim End-Test ist.
Ursache für diesen Fehler:
Bequemlichkeit: Was benötigt wird ist sowieso bekannt und geklärt und muss nur aus formellen Compilergründen deklariert werden, also am einfachsten
direkt im C-File, selbst verständlich ganz ordentlich in einer extra Abteilung EXTERNALS. Das ist falsch.
Deklaration in einem Header, der bisher nicht eingezogen wurde und mit dem es anderen Ärger (Unverträglichkeit) gibt, also
wird die Deklaration in einen eigenen Header kopiert und schon ist sie zweimal vorhanden.
Richtig: Deklarationen dürfen nur genau einmal in nur einem Header vorhanden sein. Die Headerfiles müssen gut strukturiert
sein, damit ein Includieren nicht Nebenprobleme verursacht. Es muss eine klare Top-down-Ordnung für Header geben. Ansonsten
kann es Probleme mit zyklischen Includes geben. Ist das beachtet, dann ist das Includieren des benötigten Headers auch kein
Problem.
Richtig: Header müssen selbst diejenigen Header includieren, deren Deklarationen sie selbst benötigen. Test: compiliert man
einen Header allein (C-File nur mit dieser #include <test.h>-Zeile, dann muss das ohne Compilerfehler gehen. Das ist die bessere Methode gegenüber der, die Includes im C-File vorzuschreiben.
Sie funktioniert, wenn die Header Top-down organisiert sind.
Richtig: Jeder Header muss mit #ifndef __Name_h__ gegen doppeltes includieren des Inhaltes geschützt sein. Die Bezeichnungen dieses Defines der bedingten Compilierung darf
nicht in verschiedenen Headers dopelt auftreten.
Falsch: In Headerfiles werden Datenelemente definiert oder Routinen definiert. Der Fehler kommt gegebenenfalls auch dadurch
zustande, dass man eine Regel beachtet: Includiert werden dürfen nur Header. Diese unrichtige Regel führt dann dazu, dass man maschinencodebildende Bestandteile, die includiert werden sollen, etwa
wegen Variantenbildung, also in einen Headerfile schreibt.
Richtig: Man kann in einen C-File andere Files mit beliebigen Extensions includieren. Man kann auch andere C-Files includieren,
die dann freilich nicht nochmal compiliert werden dürfen. Günstig ist es, Files, die für das Includieren vorgesehen sind,
passend zu kommentieren oder kennzuzeichnen.
Insbesondere in C++ ist die Verwendung von Dynamic Link Libraries (dll) unter Windows beziehungsweise shared libraries unter UNIX bekannt. Das Konzept solcher Dynamischen Bibliotheken hat einige Vorteile. So kann eine Gesamt-Funktionalität mittels Bereitstellen verschiedener Teil-Bibliotheken als Files zur
Laufzeit variiert werden.
Java verwendet ausschließlich das Konzept des dynamischen Linkens. Alle Klassen sind in Jar-Files oder als einzel-class-Files
vorhanden und insoweit einzeln zusammenstellbar Sie werden geladen, wenn sie benötigt werden. Zur Laufzeit, vor dem Start
oder auch vom zuvor laufenden Programm selbst, kann ausgetauscht werden.
Die etwas höhere Aufrufzeit von Routinen, wenn deren Programmcode noch nicht geladen ist, wird teils von schnellen Filezugriffen
und schnellen Prozessoren wett gemacht. Für zeitkrirische Anwendungen kann aber der entsprechende Programmcode gleich zu Anfang
komplett geladen werden. Dann hat man immer noch den Vorteil der Zusammenstellbarkeit vor dem Programmstart.
Das Thema Kommunikationswege gehört genauso zur Verknüpfung der Module wie das statische und dynamische Linken.
Die Kommunikationswege bei gelinkten Modulen liegen im direkten Datenzugriff im gemeinsamen Speicherbereich (Adresse über
Label verlinkt), in der Tatsache des Aufrufes der richtigen Subroutine zum richtigen Zeitpunkt (das ist ein Event) und der
damit verbundenen Parameterübergabe im Stack. Daten können auch referenziert werden, wenn der Zeiger übergeben wird.
Auch bei direkt gelinkten Methoden, die also im selben Prozessraum ablaufen, ist eine Kommunikation beispielsweise über Socketverbindungen
möglich. Das ist dann zweckmäßig, wenn die Module diese Kommunikationsart sowieso enthalten weil aus anderen Gründen notwendig.
Man muss also nicht eine solche Kommunikation ausbauen, weil es im gleichen Prozessraum einer Applikation nicht notwendig
ist.
Einige Kommunikationsmechanismen sind auch dann einsetzbar, wenn Module räumlich getrennt sind. Der verbreitetste und damit
wichtigste Mechanismus ist hier die Socketkommunikation.
Andere Kommunikationswege sind oft betriebssystemspezifisch und werden gern in betriebssystemangelehnten Applikationen verwendet.
Darauf wird hier nicht weiter eingegangen.
Die genaue Ausprägung einer Kommunikationsverbindung (Protokolle, OSI-Schichten, Events, Remote Procedure Call usw. usf) sind
eigene Themen, die den Zweck dieser Darstellung sprengen. Wichtig ist: Das gehört auch zur Verbindung von Modulen.
Module benötigen häufig Daten. Es gibt Fälle, in denen ein Modul bei Aufruf etwas berechnet, dabei aber weder gespeicherte
Daten benötigt (Parameter) noch statisch vorhandene Daten (über den Aufruf hinweg) verändert. Damit wird ein Paradigma der
Funktionalen Programmierung erfüllt. Module sind aber oft so organisiert, dass sie sich selbst Daten merken, dass nachfolgend aufgerufene Methoden den
zuvor mit anderen Methodenaufruf eingestellten Zustand nutzen können. Das ist ein Paradigma der Objektorientierten Programmierung, was diesbezüglich der [Funktionalen Programmierung]] genau entgegengesetzt steht.
Wenn die notwendigen Daten zu einem Modul angelegt werden, dann entsteht eine Instanz des Moduls. Ein Modul als Ergebnis der
Softwareerstellung ist im Objektorientiertem Sinn als Klasse (class) aufzufassen.
Ein Modul kann sich demnach mehrfach instanziiert finden. Die einmalige Instanziierung wird als singleton bezeichnet und ist ein Sonderfall.
Statische Daten werden angegelegt, in dem in C oder C++ Daten direkt definiert werden:
int x;
int a = 0;
Type data = {0};
Die Daten können sowohl innerhalb einer Subroutine (C-Funktion) angelegt werden und sind dann nur dort sichtbar, dabei ist
das Schlüsselwort static zusätzlich erforderlich, oder die Daten können in einem C-File außerhalb von Funktions-Bodies angelegt werden. Das Beispiel
zeigt drei Varianten:
Anlage einer einfachen Variable ohne Initialiisierung,
Anlage einer einfachen Variable mit Initialisierung,
Anlage eines strukturierten Types mit Initialisierung.
Aus Sicht einer guten Softwaretechnologie ist nur der dritte Fall gut zu gebrauchen.
Insgesamt ist die Verwendung von statischen Instanzen differenziert zu bewerten:
Es handelt sich Objektorientiert um Singeltons. Damit werden Klassen bezeichnet, die nur einmalig instanziiert werden. Singletons sind in einer vielfältigen Softwareumgebung
nur eingeschränkt verwendbar. Gleiche Aufgaben parallel sind mit Singletons nicht zu realisieren. Singleton sind Objektorientiert
nur dann zu vertreten, wenn die Problemstellung singelton ist - nur eine einzige Instanziierung zulässt.
Anders ist es jedoch in C in der Verwendung in Embedded Systemen mit abgegrenztem Funktionsumfang. Hierbei geht es nicht um
Singletons als Software-Charakteristika, sondern schlichtweg darum, dass sowieso nur eine Instanz benötigt wird. Man denkt dabei nicht
über Singletons oder nicht nach, sondern instanziiert einfach.
Der Zufriff auf einzelne Daten aus einer statischen Instanz geschieht auf Maschinencodeebene direkt. Es ist die schnellste
Art, auf Daten zuzugreifen. Dabei macht es keinen Unterschied, ob es sich um einfache Variable handelt (hierbei ist es klar,
dass maschinentechnisch dessen vom Linker festgelegte konstante Adresse direkt benutzt wird) - oder ob es sich um ein Element
in einer Struktur handelt. Auch in diesem Fall berechnet der Compiler die direkte Adresse. Der Maschinencode ist also nicht
anders gestaltet als bei einem Zugriff auf eine einfache statische Variable.
Aus dem letzt dargestellten Sachverhalt ergibt sich die Aussage, dass es keinen Vorteil bringt, einzelne Variable statisch
zu definieren. Man kann besser zusammenhängende Daten in einer struct zusammenfassen und diese struct dann statisch instanziieren. Der Vorteil ist, dass die Zusammengehörigkeit von Daten in der Software klar definiert wird.
Das ist ein starker struktureller softwareentwurfstechnischer Vorteil.
Statisch instanziierte Daten können auch referenziert benutzt werden. Wenn ein anderes Softwaremodul also referenzierte Daten
eines bestimmten Types erwartet, dann kann diesen Subroutinen auch eine Referenz (Zeiger) auf diese Daten übergeben werden.
Eine statische Instanz erzeugt also keinerlei Nachteile für eine referenzierte Verwendung.
Folglich sollten statische Instanzen in zwei Fällen verwendet werden:
Objektorientiert, große universelle Software: Dann, wenn das Problem singleton ist.
Einfach in C, wenn klar ist, dass nur eine Instanz notwendig ist.
Instanzen solten statisch nur dann angesprochen werden, wenn diese Instanzen im Kontext bekannt sind (Singelton-Denkweise). Sind Gründe gegeben, dass mit mehreren Instanzen zu rechnen ist, oder wird der maschinentechnisch optimale Zugriff
nicht benötigt, dann sollten statisch angelegte Daten referenziert angesprochen werden. Also: Es wird nicht mit der statischen
Instanziierung gerechnet. Diese Module können die Daten dann sowohl statisch singleton, als auch multi-instanziiert verarbeiten.
Eine einfache in C populäre Herangehensweise ist die Anlage der Daten neben dem Programmcode eines Moduls im selben C-File:
int store;
int myRoutine(int value)
{ store += value; //kummuliert
return store;
}
Damit sind die Daten gleich mit angelegt, wenn das Modul vom Linker erfasst wird. Alles erledig.
Doch:
Die Verwendung von statischen Variablen innerhalb der Software eines Moduls verhindert eine mehrfache Instanziierung.
Die Daten liegen unstrukturiert flach, möglicherweise im Quellcode verteilt vor.
Die mehrfache Instanziierung mag für einige Anwendungen als nicht notwendig oder gar abwegig erscheinen. Es kommt aber auf
die Einsatzfälle an. Eine bestrittene Notwendigkeit der Mehrfachinstanziierung gilt nur für einen Zeitpunkt und gegebenfalls
nur als Meinung einer Personengruppe. Es zeigt sich in der Praxis häufig, dass die Gewohnheit der einfachen direkten Anlage
von Daten im Modul dann doch die Notwendigkeit der Mehrfachinstanziierung aus neuen Anforderungen resultierend, erschwert.
Auch aus dem zweiten oben genannten Grund sollten alle Daten eines Moduls grundsätzlich in einer gemeinsamen struct in C zusammengepackt werden. Wird diese struct dann statisch instanziiert und nicht referenziert benutzt, dann ergeben sich keinerlei Nachteile. Der maschinencodetechnische
Zugriff auf die Daten ist identisch mit dem Zugriff auf einzelne direkte Daten. Aber es ist mit wenig Umstellungsaufwand möglich,
eine Mehrfachinstanziierung zu realisieren.
Diese Regel der Bildung einer zusammenhängenden Datenstruktur pro Modul entspricht der Objektorientierten Programmierung.
Im Standard-C ist es recht einfach möglich zu notieren:
int myRoutine(int value)
{ static int store = 0;
store += value; //kummuliert
return store;
}
Diese Routine liefert bei Mehrfachinstanzierung des Moduls Ergebnisse, die von allen Modul-Instanzen abhängt. Jeder Aufruf
der Routine unabhängig von der Instanz benutzt den selben Speicherplatz. Zudem ist dieses Verhalten nach außen wenig dokumentiert.
Bitte vermeiden.
In Java sind statische Daten verwendbar, allerdings sind diese Daten im Verband der Klasse definiert und daher geordneter
auffindbar. Eine freie Definitionsmöglichkeit der Daten außerhalb von Klassen gibt es nicht. Die Problematik der nicht-Mehrfachindizierbarkeit
ist die selbe. Jedoch ist in Java die Verwendung von Klassendaten die gängige Programmierpraxis. Statische Daten sind der
fast höhere Aufwand. Die Notation beim Zugriff auf die Daten unterscheidet sich nicht (erkennt der Compiler selbständig),
lediglich das Schlüsselwort static ist zusäztlich erforderlich.
Die Daten einer Applikation sollten so organisiert werden, dass es eine Main-Instanz der Applikation gibt, die alle anderen
Daten entweder enthält (embedded) oder referenziert. Man kann auch die Daten der Module einzeln anlegen und so wie notwendig
miteinander referenzieren. Doch ist damit ein Überblick über die Daten schwerer möglich als bei einer hierarchischen Organisation
3.3.6.2.1 Struktur von Daten und deren direkte Instanziierung als Singleton
Die Instanziierung der MainData kann so erfolgen, dass diese statisch in einem C-Modul definiert wird. Es entsteht damit ein
Singelton, das entweder referenziert benutzt werden kann (dann ist für die Benutzung eine Anlage im Heap identisch), oder die Daten
werden an geeigneter Stelle direkt als der Singleton-Instanz angesprochen. Damit hat man die schenllste Variante bezüglich
der Verarbeitung im Maschinencode:
extern MainData mainData; //im Headerfile, von allen sichtbar.
mainData.data12 = 34; //direkter Speicherzugriff, ohne Adressarithmetik
MainData* pMain = &mainData; //Zeigerbildung
pMain->data12 = 34; //indizierter Zugriff, kaum länger.
In Java werden Daten grundsätzlich nur im Heap angelegt werden. Die erste Instanz einer Applikation wird in deren Main-Routine
angelegt:
class MainType {
public static void main(String[] args)
{ MainType main = new MainType();
main.execute();
}
...
}
Es geht genauso mit:
class MainType {
static MainType main = new MainType();
public static void main(String[] args)
{ main.execute();
}
...
}
Im zweiten Fall legt der ClassLoader beim Laden der Klasse die Daten im Heap an und speichert die Referenz dazu in der Variablen
main. Man kann einen Haltepunkt an diese Stelle oder in den Konstruktor setzen (Beispiel Eclipse-debugging), der Haltepunkt wird
erreicht bevor main(String[]) aufgerufen wird. Diese Programmierweise ist nicht so sehr üblich in Java, denn in diesem Fall kann die Main-Instanz nicht
mehr abhängig von den Aufrufparametern gebaut werden. Aber ansonsten wird das selbe Resultat erzeugt.
Auch wenn die übergeordnete Datenstruktur des Hauptzweiges nur als Singleton benötigt wird und dauerhaft angelegt bleiben
soll, kann sie im Heap dynamisch beim Hochlauf allokiert werden. Man braucht den Zeiger auf die Daten nirgends global ablegen,
sondern kann den Zeiger jeweils gerufenen Routinen oder anderen danach gestarteten Threads im Stack übergeben (Subroutinenparameter).
Das ist die pure nicht Globaldaten-Lösung. Allerdings ist es für Debugzwecke günstiger, den Zeiger zusätzlich statisch abzulegen.
Man kann dann im Debugger die Haupt.-Datenstruktur leichter finden. dies nur als Praktischer Tip.
Diese Referenz auf die Haupt-Daten soll als Firstlevel-Referenz bezeichnet werden. Man kann eine oder mehrere solcher Firstlevel-Referenzen haben. Klassenorientiert (C++, Java) lässt sich
eine solche Referenz als static-Member anlegen.
Man kann die Daten zu weiteren Modulen ebenfalls statisch anlegen. Dabei ist eine mehrfache Instanzzierung möglich, in dem
man mehrere Daten anlegt, die Module müssen dann diese Daten per Referenz ansprechen. Sind die Module als Singleton gedacht,
dann kann in den Modulen die Daten direkt verwendet werden, vermittels einer Deklaration:
Im Header für das Modul:
extern Modul_X modul_X_Data;
In einer Compilierungseinheit: Anlage der Daten:
Modul_X modul_X_Data;
In der Compilierungseinheit des Moduls:
modul_X_Data.element = 1234;
In diesem Fall ensteht optimaler Maschinencode, aber die Möglichkeit der Mehrfachinstanziierung ist verbaut. Man kann unter
Ausnutzung von defines aber beides haben. Das kann notwendig sein, wenn ein Modul in einer Applikation nur singelton aber
extrem optimal laufen soll, in einer anderen Anwendung dagegen multiinstanziiert. Beispiele: Zielplattform singleton und schnell,
Modultest am PC: Mehrere Module, die sich sonst auf verschiedenen Hardwareeineiten befinden, werden in einer Executable im
Zusammenspiel getestet:
In einem define, dass zielsystemabhängig verschieden ausgewählt wird, hier für die referenzierte Instanz:
#define modul_X (*modul_X_p)
oder für die direkt angesprochene Instanz:
#define modul_X modul_X_data
Die jeweils richtige Variante des Defines wird im Compiliervorgang ausgewählt.
Grundsätzlich sollte wenig mit Defines bzw. Makros gearbeitet werden. In diesem Fall ist es aber notwendig, daher berechtigt,
und einfach, daher zu erlauben.
Daten werden dann statisch instanziiert, wenn sie in Java als final static gekennzeichnet wurden und in der selben Zeile mit new initialisiert werden. Wenn diese Daten mit dem dort vergebenen Namen referenziert werden, dann wird ein statischer Zugriff
(unmittelbare Adressierung) ausgeführt.
Daten werden dann eingebettet in die Struktur der definierenden Klasse, wenn sie in Java als final gekennzeichnet wurden und in der selben Zeile mit new initialisiert werden.
3.3.6.3.3 Im Heap allokierte und referenzierte Daten
In klassischen C-Programmen für embedded Control ist die Anlage von Daten in einem Head (malloc) eher seltener. In C++-Programmen ist die Nutzung eines Heaps oft gängige Praxis, insbesondere bei Programmen auf dem PC,
bei denen von Haus aus ein entsprechend großer Heap bereitsteht. Der Heap ist der dynamisch allokierbare Speicher, der vom
Betriebssystem verwaltet auch für große Daten genutzt werden kann.
Es kommt also auf die Laufzeitumgebung und die Anforderungen an. Braucht man keine feste Speicherbindung und ist der Heap
genügend groß, kann es sinnvoll sein alle Daten im Heap anzulegen. Die Daten werden dann immer über Referenzen angesprochen.
Es gibt in C und C++ ein paar kleine Probleme zu beachten:
Freigabe des Speicherbereiches: Es gibt zwei Fehlerfälle:
Der Speicher wird freigegeben, obwohl die Referenz auf diesen Speicherbereich noch existiert, es erfolgt nach der Freigabe
noch ein Zugriff. Das kann schwere Störungen im Gesamtsystem verursachen, da der Speicherbereich bereits neu in anderer Größe
allokiert sein könnte. Insbesondere können die Strukturen der Heaporganisation überschrieben werden, dann crasht das gesamte
System.
b) Der Speicher wurde vergessen freizugeben. Dann gibt es bei langer Laufzeit ein Problem mit dem notwendigem Speicherbereich
einer Applikation.
Überschreiben des Speicherbereiches: Fehler in der Programmierung: Zeigerarithmetik, Indexüberlauf können die Speichergrenzen
verletzen. Dann gibt es zusätzlich das Problem, dass die Organisationsdaten des Heaps zerstört werden können. Abhilfe für
sicherheitskritische Programme kann eine Speichersegmentierung mit Schreibschutz sein.
Häufiges Allokieren und Deallokieren verschieden großer Speicherbereiche führt dazu, dass die genutzen Bereiche des Heaps
eher wie ein Flickenteppich aussehen (fragmentiert) und das möglicherweise irgendwann kein zusammenhängender Speicher der
erforderlichen Größe bereitgestellt werden kann, obwohl die Gesamtanzahl der freien Bytes genügend groß ist.
Man kann daher schon dahin tendieren, dass Heap-Bereich nicht für alle kleinen Speicheranforderungen benutzt werden sondern
nur für die großen Komplexe, die nur beim Hochlauf der Applikation angelegt werden müssen. Der Vorteil der Heap-Nutzung liegt
dann darin, dass die Speichergröße beim Anlauf der Applikation von den Anlaufparametern abhängen darf. Statisch angelegter
Speicher ist demgegenüber in seiner Größe zur Compilezeit festgelegt.
Java in der Standardausprägung der virtuellen Maschine (VM) auf einem PC benutzt Speicher grundsätzlich im Heap. Der referenzierte
Speicher ist das Grundkonzept von Java, da damit die größtmöglichste Flexibilität erreicht wird.
Die oben genannten C/C++-Heap-Probleme sind in Java wie folgt gelöst:
Falsche Speicherfreigabe: In Java braucht man die Freigabe nicht selbst zu programmieren. Ein Garbage Collector der Java-Organisation (in der VM) testet im Hintergrund oder bei Speicheranforderungen, ob auf die allokierten Bereiche noch
Referenzen bestehen. Die Freigabe erfolgt dann, wenn keine Referenzen mehr vorhanden sind. Damit ist gegenüber diesem Thema
eine Sicherheit garantiert. Allerdings kann eine Anwendung noch Speicher referenzieren, obwohl die Referenz im weiteren Ablauf
nicht mehr benötigt wird. Dann geht auch bei Java der Speicher aus. Man sollte Referenzen nicht stehenlassen sondern mit null belegen.
Überschreiben des Speicherbereiches: Ist bei Java daher nicht möglich, weil es keine Zeigerarithmetik gibt und indizierte
Zugriffe geprüft werden.
Fragmentierung des Speichers: Da die virtuelle Maschine die Referenzen auf die Speicher kennt, ist es möglich, die Abarbeitung
für eine notwendige Zeit (Millisekunden, kann auch mal Sekunden sein) anzuhalten und den Speicher neu zu organisieren. Damit
ist dieses Problem auch gelöst.
Die Speicherverwaltung in Java ist also sicher gestaltbar. Insbesondere wegen der Defragmentierung ist allerdings die Abarbeitungszeit
nicht garantiert (kein Realtime). Für die typischen Anwendungen der Serverorientierten Architektur ist eine Pause von bis
zu einer Sekunde wegen Defragmentierung nicht kritisch, da das im Bereich verträglicher Antwortzeiten liegt. Ansonsten ist
Java sehr schnell und kann damit den hohen Datendurchsatz bewältigen. Aber für schnelle Echtzeitverarbeitung geht das nicht.
Abhilfe: Es gibt Real-Time-Java-Versionen mit besonderen Mechanismen.
Bei Nutzung von Java2C insbesondere für Realtimeanwendungen wird das Problem der Echtzeitanforderung und Heap wie folgt gelöst:
Es gibt die Möglichkeit, mit statischen oder embedded Instanzen zu arbeiten, bei entsprechender Formulierung im Java-Quellcode.
Die Java-Abarbeitung verwendet also Heap-Speicher, wogegen in der nach C übersetzen Variante statischer oder embedded Speicher
verwendet wird.
Im Java2C-Laufzeitsystem gibt es einen sogenannten BlockHeap, ein Heap, der gleichgroße Blöcke verwaltet. Das ist für Instanzen gedacht, die auch in Realtime-Anwendungen dynamisch allokiert
werden müssen, aber typischerweise dort einen begrenzten Speicherumfang haben. Das sind etwa Event-Daten, aufbereitete Zeichenketten
für Logmeldungen und dergleichen. Dieser Blockheap wird mit einem Garbage-Collector verwaltet. Allerdings kann dieser Garbage-Collector
unterbrochen werden, blockiert also nicht die CPU. Belegte Blöcke werden nicht verändert.
Speicherüberschreiber: Sind immer nicht entdeckte Softwarefehler. Wenn man ein Programm in Java unter möglichst vielen Bedingungen
vortestet, dann werden diese Softwarefehler dort auffallen und korrigiert werden. Die nach C übersetzten Files führen automatisch
keine Indexüberwachung bei Arrayzugriffen aus. Zeigerarithmetikfehler sind deshalb ausgeschlossen, da aus Java heraus solche
nicht programmiert werden, außer in bestimmten ausgetesteten Bedingungen. Hier gilt ebenfalls, dass beispielsweise ein Casting
auf einen abgeleiteten Typ beim Test in Java bereits entdeckt werden sollte und daher im C-Programm korrigiert ist. Instanztyptests
werden auch in C ausgeführt und können die Sicherheit der Programmierung erheblich erhöhen.
3.3.7 Instanziierung und Compositions zur Laufzeit
Wird eine Composition- oder Aggregation-Beziehung von Modulen über Interfaces benutzt, dann ist der entscheidende Schritt
der Composition der der Instanziierung. Zu einem Interface können verschiedene Modul-Typen bzw. Klassen instanziiert werden,
abhängig von Konfigurationen oder auch verschiedene an unterschiedlichen Stellen. Damit wird eine höhere Flexibilität erreicht
als beim statischen oder dynamischen Binden. Ersteres ist eine Grundlage, die Instanziierung baut darauf auf.
Es gibt nun mehrere Möglichkeiten der Instanziierung:
Instanziierung notwendiger Module im Modul selbst (UML-Composition): Damit muss das Modul seine genutzten Module kennen. Es ergibt sich kein Vorteil zum dynamischen Binden.
Instanziierung notwendiger Module außerhalb. Das Prinzip wird auch als Dependency Injection bezeichnet. Hierbei gibt es sozusagen ein übergeordnetes Modul, dass alle Instanziierungen vornimmt.
Zuordnung von Modul-Verknüpfungen (UML-Aggregations) von außen: Hier setzt der Erbauer / Builder eines Systems die Aggregationen, die in diesem Fall für sichtbar (nicht private oder protected) oder setzbar über Setits...-Methoden sein müssen.
Abfrage der Instanzen für Modul-Verknüpfungen (UML-Aggregations) nach außen und Setzen innen: Hier muss jemand vorhanden sein, der gefragt werden kann und alle Module des Systems kennt.
Die Aktivität kommt aus einem Modul heraus, dieses weiß genau, was es setzen soll, nur nicht womit. Derjenige, der alle Module kennt, kann der Builder sein, oder ein als Broker bezeichenbare Instanz oder Schnittstelle.
3.3.8 Verbindung von Modulen, Aggregation-Beziehung
Module müssen andere Module kennen, um Daten auszutauschen. In einem Embedded System sind solche Modul-Verbindungen oft stabil. Die Module und deren Verbindungen werden beim Startup festgelegt und bleiben dann
fest. In diesem Sinne sind die Modulverbindungen als Aggregationen nach der UML-Denkweise zu bezeichnen. Mehrere Module sind gemeinsam zu einem gesamten Aggregat verbunden. Ein Modul kann
nicht arbeiten, wenn nicht das andere Modul etwas bereitstellt/entgegennimmt.
Es scheint, dass hiermit ein großer Komplex von in sich verzahnten Modulen entstehen könnte. Das soll nicht sein. In einer
UML-Darstellung (Klassendiagramm) kann sehr genau aufgezeigt werden, wer wen und auf welche Weise kennt. Module, die in einem
Prozessraum zusammengebunden sind und statisch über dynamisch gelinkt sind, kennen sich nur bezüglich der globalen Labels.
Das können auch wenige sein. Globalität beißt sich oft mit Mehrfachinstanziierung und Wiedereintrittsfähigkeit. Die statisch
gelinkte Adresse auf Daten zielt auf globale Daten.
Damit sind die Referenzen zwischen Modulen ein gleichrangiges Thema neben dem Linken und den Schnittstellendeklarationen in
Headerfiles oder Interface-classfiles.
Bei Aggregationsbeziehungen muss der Nutzer nicht alle Details des genutzten Moduls kennen. Es genügt die Kenntnis der Schnittstellen.
Diesbezüglich gibt es in C, in C++ oder in Java sehr verschiedene Konzepte. Die Reduzierung der Aggregationsbeziehungen auf
Schnittstellen ist ein ganz wesentliches Mittel, um Softwareteile (Module) unabhängig bearbeiten zu können.
3.3.8.1.1 Headerfiles, Funktionsprototypen und Vorwärtsdeklarierte Zeigertypen in C
Im klassischem C gibt es die Headerfiles als Schnittstellendefinition zu anderen Modulen:
Funktionsprototypen definieren eine aufrufbare Subroutine mit ihrem Namen, Parameter und Returnwert, ohne die Implementierung
der Routine mit einzubeziehen. Die Implementierung kann unabhängig geändert werden. Nach Änderungen gibt es keine Auswirkungen
auf den Aufrufer (solange die Schnittstelle nach außen unverändert bleibt).
Referenzierte Datenstrukturen können mit einer Vorwärtsdeklaration als Zeigertyp angegeben werden, ohne dass die tatsächliche Datenstruktur dem Nutzer bekannt sein muss. Es ist also auch diesbezügliche
eine Änderung in einem anderen Modul ohne Auswirkungen auf das nutzende Modul möglich. Dieser Vorteil entfällt bei embedded
Strukturen, aber auch nur wegen der Kenntnis der Gesamtgröße einer eingebetteten Struktur. Wird eine embedded Struktur ebenfalls
über Referenzen den Subroutinen des anderen Moduls übergeben, bewirkt eine Strukturänderung ohne Längenänderung keine Änderung
am Maschinencode des nutzenden Moduls.
Die Verwendung von vorwärtsdeklarierten Zeigern sein an folgendem Beispiel demonstriert:
Header der Schnittstelle zu Modul_B:
Der Bezeichner einer struct eines genutzten Moduls wird deklariert, damit der Compiler diesen kennt.
struct Modul_B_t;
Die Definition der Funktionsprototypen, also die Deklaration der Funktionen (Subroutinen) stehen im Header des Modul_B.h,
der beim Compilieren des Modul_A mit eingezogen wird. Hier ist nicht die Kennnis des Aufbau der struct des Modul_B notwendig.
Das Modul_B wird angelegt, die Instanziierung ist im Modul_B programmiert. Zurückgegeben wird nur der Zeiger. Der Aufbau der
struct Modul_B braucht hier nicht bekannt zu sein.
ownData.myModulB = initModulB(...);
Auf das Modul_B wird zugegriffen. Dazu wird einer Subroutine aus Modul_B die bekannte Referenz auf dessen Daten übergeben.
Auch hier braucht der Aufbau der Daten beim Aufrufer nicht bekannt zu sein:
executeSomethingOfModul_B(ownData.myModulB);
Interner header des Modul_B:
Im Modul_B wird dessen Datenstruktur nun definiert, diese Definition ist nur für die Compilierung des Modul_B notwendig.Sie
kann sich im C-Quelltext befinden, kann aber auch in einem privatem Header angeordnet werden. Der Header, der die Funktionsprototypen
enthält, wird vorher eingezogen.
typedef struct Modul_B_t
{ int x,y;
}Modul_B_s;
Die Definition der Subroutinen selbst ist nun mit dem Bezeichner des typedef ausgeführt. Damit ist gekennzeichnet, dass Internas des Typs nun verwendet werden. Der Compiler erkennt die Richtigkeit der
Zuordnung struct Modul_B_t (die Struct-Tagdefinition) zu der Modul_B_s, der Typdefinition, da er zuvor diese Typdefinition compiliert hat. Es erfolgt also ohne Fehlermeldung, aber mit Check der
Korrektheit, die Compilierung der Subroutinen:
Im Modul wird beispielsweise eine Singletoninstanz statisch angelegt und verwendet. Rückgegeben wird aber der Zeiger darauf.
Damit ist die Frage ob statisch oder nicht nach außen gekapselt. Eine Änderung ist rückwirkungsfrei auf den Nutzer möglich.
Bei der folgenden Routine übergibt der Nutzer die Referenz, da er nichts von der Singeton-Eigenschaft weiß. Nur die derzeitige
Implementierung verwendet Singleton, eine Erweiterung ist ohne Rückwirkung möglich, Wegen dem Singleton wird also in der derzeitigen
Implementierung die Referenz ignoriert.
Regel: Schnittstellen sollten so definiert sein, dass bei einer absehbaren Erweiterung nicht die bisherigen Schnittstellen geändert
werden müssen. Also ist die Verwendung einer Referenz auf ein Modul gerechtfertigt, auch wenn es derzeit nur als Singleton realisiert werden
muss.
Als Beispiel sei noch eine Implementierung gezeigt, die nicht mit Anlage der Daten im Heap arbeitet (weil das Beispiel klassisch
embedded bleiben soll), aber die Referenzen benötigt:
In C++ ist es einfach möglich, objektorientiert zu programmieren. In der Objektorientierung gibt es die Interfaces, wie sie in Java direkt als eigenes Sprachmittel vorliegen. In C++ sind solche Interfaces genauso realisierbar, als ausschließlich
abstrakte Klasse:
Das Interface enthält also ähnliche Informationen wie die Funktionsprototypen in C. Die Eigenschaft der Vorwärtsdeklarierung
wird hier nicht weiter genutzt, da die Interface-class-Definition vom Nutzer sichtbar ist.
Damit hat der Nutzer alle Informationen, wie er das Modul_B kennen soll: Referenz und zwei Methoden. Er kann diese anwenden:
Die Implementierung im Modul_B sieht dann wie folgt aus:
#include "Modul_B_ifc.h"
class Modul_B: public Modul_B_ifc
{
static Modul_B_ifc* initModulB(...);
void executeSomethingOfModul_B();
};
Modul_B_ifc* Modul_B::initModulB(...){
Modul_B* data = new Modul_B();
data->x = 25;
return data; //auto cast to interface type.
}
void Modul_B::executeSomethingOfModul_B(){
data->xy = ...
}
Das Beispiel ist adäquat zu dem C-Beispiel adäquat gehalten. Für die Gestaltung des Quellcodes gibt es einige Syntaxunterschiede.
Funktionell ist aber eine Ähnlichkeit vorhanden.
Die Abarbeitung geht aber gänzlich andere Wege:
Mit dem hier gezeigten Interfacekonzept ist eine Nutzung des Interfaces nicht nur als Interface zu Modul_B möglich, sondern auch zu anderen Modulen, die ein gleiches Interface haben. Im C-Beispiel bezieht sich die Definition der
Funktionsprototypen ausschließlich auf das Modul_B. C++ kann also hier mehr. Das Grundkonzept der Objektorientierung, Polymorphie, wird unterstützt.
Wegen der Polymorphie ist der Aufruf myModulB->executeSomethingOfModul_B(); nicht unbedingt auf die implementierte Methode Modul_B::executeSomethingOfModul_B() bezogen, sondern auf diejenige Methode, die zur implementierenden Klasse gehört. Ein Modul_B2 kann das selbe Interface benutzen und eine adäquate Methode bereitstellen. Da die Information, von welchem Typ die per Interface
referenzierte Instanz ist, nicht bei der Compilierung des Modul_A bekannt ist, kann er nur zur Laufzeit ermittelt werden. Das ist die Zeile
myModulB = Modul_B::initModulB(...);
Hier wird an einer Stelle das Modul_B explizit erwähnt. Das ist meist in der Hochlaufphase. Weitergegeben wird dann nur die Referenz auf das Interface. Die Information
um welchen Typ der Instanz es sich handelt, ist also beim Compilieren weg. Es gibt noch komplexere Mittel der Instanziierung,
Factory-Pattern, bei dem die tatsächliche Instanz nochmals gekapselt ist.
Die letzliche Instanz steht aber in den Daten, neben den weiteren Daten als Zeiger auf eine sogenannte virtuelle Tabelle (vtbl). Über diese Tabelle werden als Sprungleiste die richtigen Methoden gerufen.
Damit wird bei Aufruf einer Methode immer ein indirekter Aufruf ausgeführt (über Dateninhalte). Es kann nun passieren, dass
ein solcher Aufruf auf einer falschen Adresse landet. Das passiert wenn die Daten wegen einem Softwarefehler unzulässig gestört
sind. In C kann das nie passieren, wenn niemand den Maschinencode überschreibt (einfacher Speicher-Schreibschutz genügt).
Der Mechanismus über die virtuelle Tabelle ist also nicht genügend sicher für einige Anwendungen.
Man kann in C++ grundsätzlich auch so wie in C arbeiten, also die sichere aber weniger flexible Methode wählen.
Etwas mehr Klarheit bei der Klassendefinition (mehr als ein Doppelpunkt: implements. Der Implementierungscode steht in der class, kein extra Headerfile.
class Modul_B implements Modul_B_ifc
{
static Modul_B_ifc* initModulB(...){
Modul_B* data = new Modul_B();
data->x = 25;
return data; //auto cast to interface type.
}
void executeSomethingOfModul_B(){
data->xy = ...
}
};
Die Möglichkeit des direkten Aufrufes ohne Interface gibt es in Java nur, wenn das genutzte Modul_B vor der Compilierung des nutzenden Modul_A bereits compiliert vorliegt. Es muss also im Quelltext fertig sein. Damit entsteht eine direkte Abhängigkeit. Wird Modul_B geändert, dann sollte Modul_A auch re-compiliert werden. In C ist das nicht nötig, da die Headerfiles sich nicht geändert haben (nur neu Linken ist notwendig).
Bei Nutzung eines Interfaces in C++ oder Java ist das auch nicht nötig, da das Interface sich nicht geändert hat.
Die Probleme mit den virtuellen Tabellen und einem möglichen Absturz gibt es insofern nicht, als Java wegen der Prüfmöglichkeiten
der Virtuellen Maschine diesbezüglich immer sauber arbeitet (sofern die VM fehlerfrei ist). Man kann also in Java bedenkenlos
mit den Interfaces arbeiten.
3.3.8.1.4 Java2C: Interfaces aus Java, aber möglicher Direkt-Aufruf
Bei der Konvertierung von Java nach C ist folgender Weg gegangen:
Die Interfacetechnik mit ihren virtuellen Methoden ist auf Funktionszeigertabellen (Sprungleiste) und einen indirekten Funktionsaufruf abgebildet. Den notwendigen C-Code erzeugt der Java2C-Translator. Der Anwender muss
nichts tun und kann diesbezüglich auch keine Fehler tun.
Wegen dem Problem der Zerstörbarkeit des Zeigers zur Funktionszeigertabelle ist eine zweimalige Sicherheitsabfrage eingebaut:
Der Zeiger auf die Funktionszeigertabellen steht in den Reflection-Informationen im const-Bereich (schreibschützbar). Aber
der Zeiger auf die Reflection steht in den Daten und ist demnach sensibel. Aber bei der Ermittlung beider Zeiger wird getestet,
ob der erste Zeiger grundsätzlich auf Reflection-Informationen zeigt. Der Zeiger auf die Funktionszeiger wird dann auf Signifikanz
getestet. Die Ermittlung eines Zeigers auf den richtigen Interfacebereich dauert dabei etwas länger (kleine Suchschleife).
Damit ist dieser Zugriff wohl hinreichend sicher, aber etwas langsamer. Ein einmal ermittelter Zeiger nur im Stack gespeichert
wird als sicher bezeichnet und daher nicht vor jedem Zugriff nochmals geprüft. Die Folgezugriffe damit sind also schnell, auch bei sehr hohen
Echtzeitanforderungen.
In embedded-Routinen wird ein dynamischer Aufruf (Polymorphie) weniger häufig benötigt. Aber der Entwurf der Software sollte
wegen der Unabhängigkeit der Module über Interfaces erfolgen. Wenn die implementierende Instanz aber bekannt ist, dann kann
sie in Java in einem speziellen Comment-Tag angegeben werden. Der Java2C-Translator erzeugt dann keinen indirekten Aufruf
auf die virtuelle Methode, sondern statt dessen den direkten Aufruf. Damit greifen die in C üblichen Mittel der Prototypendeklaration
und Zeigertypdeklaration. Man kann also so wie in C implementieren und dennoch mit Interfaces entwerfen.
3.3.8.2 Möglichkeiten der Verknüpfung von Modulen mit Aggregationsbeziehungen
Module arbeiten mit anderen Modulen zusammen. Dies trifft nur nicht zu für Module, die die letzlichen Blätter an dem Gesamtbaum
der Funktionalität darstellen, also einfache unabhängige Funktionalitäten. Es trifft auch zu für Monstermodule, die alles
enthalten also keine anderen Module brauchen. Diese sollte man aber nicht bauen.
Der Unterschied zwischen einer Aggregation und einer Komposition:
Ein Aggregat ist etwas, was ein Modul benötigt, was in einer festen Beziehung von vornherein in einem Modul bekannt sein muss
(vorhanden) und nicht ausgetauscht wird, was aber unabhängig vom Modul gebaut wurde.
Ein Composite ist auch etwas, was ein Modul benötigt. Es wird aber mit diesem Modul angelegt.
Ein Composite könnte also eher aufgelöst werden und im nutzenden Modul verschwimmen. Der Grund,ein extra Submodul zu bauen,
ist zunächst eine gewisse und prinzipielle Strukturierung in Module. Es gibt aber noch einen anderen Grund:
Was dem einen sein Composite ist, ist dem andern sein Aggregate.
Oft ist es so, dass ein Modul mit einem anderen Modul zusammenarbeitet, aber eigentlich dort nur einen Teilaspekt benötigt.
Hat man diesen Teilaspekt als Composite ausgeführt, dann verringert sich die Abhängigkeit: Man muss also nicht ein recht großes
Modul kennen, sondern nur eine kleinere Teilfunktionaltität, dessen Submodul oder eben nur dieses Submodul, egal wo es angeordnet
ist.
Jetzt ist es recht beliebig, ob ein Submodul irgendwo als Composite angelegt wird, oder woanders als Composite, oder auf der
Hauptebene, dann wirklich als Composite weil, einer muss es ja anlegen. Wo das Modul Composite ist, ist also aus anderen Aspekten
heraus zu beantworten als nur dem der Modulstruktur. Möglicherweise gilt die Regel: Wer's zu erst bei sich angelegt hat, hat's
halt. Möglicherweise sind da auch Bearbeiter-Zuordnungen maßgeblicher als es einem Softwareingenieur lieb wäre. Man kann auch
ein Composite umordnen, wenn es notwendig ist.
Es ist günstig, sowohl Aggregationen als auch Kompositionen in Java als final - Referenz zu programmieren.
Dieses final trägt einen Symbolgehalt zur Doku, es zeigt dass es entweder eine Aggregation oder Komposition ist und eben keine
beliebig änderbare Assoziation.
final vermeidet es Programmierfehler, die versehentliche Neubelegung.
final sagt dem weiterführendem Programmierer, dass er nur im Konstruktor nachzuschauen braucht, wie die Referenz belegt wurde.
Sie kann sonst nirgends anders belegt werden.
Das sind also alles nur Vorteile die es zu nutzen gilt.
Andererseits zwingt final zur Belegung im Konstruktor.
Ein wichtiger und manchmal lästiger Aspekt ist die Reihenfolge der Instanziierung.Wenn ein Modul ein anderes als Aggregat
braucht, dann muss das andere Modul zuvor schon instanziiert worden sein, wenn es im final referenziert und also die Referenz
im Konstruktor belegt werden soll. Sonst geht das mit dem final nicht.
Andererseits ist aus anderen Gründen eine Reihenfolge der Instanziierung vollkommen egal. Die Reihenfolge ist also nur von
den Abhängigkeiten bestimmt. Man kann die Reihenfolge drehen, wenn bemerkt wird, dass sie nicht stimmt. Hier hilft der Java-Compiler,
um Fehler aufzudecken:
Wenn im Konstruktor eine final- Referenz benutzt wird, die aber noch nicht belegt wurde, dann meldet der Java-Compiler einen
Fehler. Das funktioniert aber nur bei final-Referenzen, weil nur bei diesen der Compiler dies feststellen kann. Man kann also Zeilen im Konstruktor solange tauschen,
bis keine Fehlermeldungen mehr vorhanden sind. Die Fehlermeldungen deuten jeweils auf die benötigten aber noch nicht instanziierten
Module hin.
Es ist außen am Modul nicht erkennbar, welche Interfaces dieses Modul bereitstellt. Statt dessen werden Interface-Referenzen
intern bereitgestellt, ohne dass an einer Stelle bekannt ist welche.
Im einem Modul innen wird die Instanz bestimmt, mit der eine Aggregation vorgenommen werden soll. Damit muss aber das Modul
Kenntnisse von der Außenwelt besitzen. Die Flexibilität wird vermindert, wenn beispielsweise in einem Testfall eine Zuordnung
geändert werden soll.
3.4 Abhängigkeiten von Softwaremodulen
Topic:Programming.ModulStructure.Dependencies
Die Beachtung von Abhängigkeiten in der Software sind ein wichtiges Thema der Softwarepfege, oft unterschätzt. Intuitiv erstellte
Software ohne Abhängigkeitsprüfung und Diskussion läuft zunächst nach einer gewissen Inbetriebnahmephase, doch bei Änderungen
an der einen Stelle gibt es oft unerwartete Nebeneffekte... Software, bei der Abhängigkeiten richtig designed sind, kann man
an einer Stelle korrigieren, und hat entweder keine Nebenwirkungen, oder Korrekturen an allen ähnlichen betreffenden Stellen
gratis mit, bevor dort Fehler überhaupt auffalllen.
Die formalen Abhängigkeiten sind sichtbar als Meldungen beim Compilieren, Linken oder Ablauf, wenn man bestimmte Variationen
der Bedinungen vornimmt. Formale Abhängigkeiten werden dann nicht entdeckt, wenn alle Quellen und Libraries einer komplexen
Applikation vorliegen. Die formalen Abhängigkeiten fallen erst dann auf, wenn beispielsweise ein Einzeltest eines bestimmten
Moduls ausgeführt wird und dazu nur die Dinge bereitgestellt werden, die für dieses Modul vermeintlich notwendig sind. Das
sollten jeweils möglichst wenige sein, da jedes Moduls nur jeweils deterministische Abhängigkeiten aufweisen sollte.
Wird bereits bei der Compilierung festgestellt, das Headerfiles fehlen, mit denen man an dieser Stelle nicht gerechnet hat,
dann liegen nicht erwartete Abhängigkeiten vor. Möglicherweise werden Header aber nur unnötigerweise includiert, es liegen
also nur formelle und keine tatsächlichen Abhängigkeiten vor.
Ähnlich ist es mit Libraries oder anderen Modulen, die zur Runtime vorliegen müssen. Wenn in einem toten Code Subroutinen
gerufen werden, dann muss ein Linker diese formell finden, tatsächlich werden sie aber nicht benötigt.
Die formalen Abhängigkeiten haben den Vorteil, dass sie - bei geeigneter Gestaltung - beim Compilier- und Linkprozess auffallen
ohne dass ein funktioneller Test ausgeführt werden braucht.
3.4.1.2 Problem der zusätzlichen Funktionale Abhängigkeiten
Wenn es formale Abhängigkeiten gibt, sind funktionale Abhängigkeiten zu erwarten. Wenn Modul A auf Funktionen von Modul B
aufbaut, dann ist es notwendigerweise formal von B abhängig als auch selbstverständlich funktionell.
Zusätzliche funktionelle Abhängigkeiten, mit denen man möglicherweise nicht gerechnet hat und die sich bei Softwareänderungen
als Problem erweisen, entstehen entweder durch versteckte Schnittstellen oder nicht exakter Definition einer Funktionalität
an den Schnittstellen. Die Möglichkeit, solche Dinge versehentlich oder fahrlässig zu bauen, sind relativ groß:
Wenn relativ allgemeingehaltene Schnittstellen benutzt werden, dann ist deren formale Erfüllung recht einfach möglich. Angenommen,
eine Funktion wird formell wie folgt definiert:
float y = commonFunction(float x, float p1, float p2, int command);
Was die Funktion genau auszuführen hat, ist hier nicht formell spezifiziert, sondern möglicherweise nur verbal festgelegt.
Es kann nicht formal kontrolliert werden. Dieser Prototyp ist als Schnittstelle überall ganz gut einsetzbar.
So offensichtlich ungünstig wird aber oft nicht programmiert. Die Dinge sind komplexer und treten unerwartet auf. Ein einfaches
Beispiel: Ein Modul bereitet einen Wert auf und liefert zyklisch einen stetigen Wert. Ein anderes Modul verlässt sich auf
den Zyklus und den stetigen Anstieg, ohne dass dies jedoch irgendwo an einer Schnittstelle festgeschrieben wurde. Werden nun
mit einer Softwareänderung alternierende Werte geliefert, ist dies bei dem nutzenden Modul möglicherweise nie ausgetestet
wurden. Eine Änderung im Modul X bewirkt damit ein Fehlverhalten im Modul Y.
Funktionale Abhängigkeiten bei nicht vorhandenen formalen Abhängigkeiten gilt es zu vermeiden, da möglicherweise niemand diese
Abhängkeiten ahnt. Funktionalitäten müssen an Schnittstellen genau definiert werden.
Es ist günstiger, wenn funktionale Bedingungen an Schnittstellen getestet werden und ein nicht vereinbartes Verhalten mit
einer deutlichen Fehlermeldung versehen wird. Die Tolerierung von Abweichungen mit einer möglichst zweckmäßigen Reaktion ist dagegen eine Aufweichung von Schnittstellendefinitionen, die sich im nachhinein als weniger günstig erweisen
könnte.
3.4.2 Horizontale und vertikale Abhängigkeiten (Layer)
Eine allgemein anerkannte Software-Architektur-Regel besagt, dass Abhängigkeiten von Modulen nur von oben nach unten oder
horizontal vorliegen dürfen. Damit wird Ordnung in die Verknüpfung von Modulen gebracht. Spezialisierte oder End-Funktionalität
baut immer auf vorher definierten und/oder vorhandenen Basis-Funktionalitäten auf.
Es entstehen damit Layer (Schichten) oder Schalen des schon in den 70-ger Jahren gängigen Schalenmodells der Software. Die meist kreisförmigen Schalen eignen sich nur für einfache Übersichtsdarstellungen, Layer können großflächiger gezeichnet
und gedacht werden.
Für jedes Layer gibt es Verantwortungsbereiche: Der Lieferant der Systemsoftware für das Betriebssystemlayer (was wiederum
auch aus Schichten besteht), die Abteilung, die sich um die Kommunikationsdienste kümmert usw. usf. bis zum Projektierer,
der im obersten Layer direkt Kundenwünsche manifestiert.
Abhängigkeiten sollten immer nur zu weiter unten liegenden Modulen bestehen: Modul A liefert seine Funktionalität ohne jegliche
Abhängigkeit zu anderen Modulen, beispielsweise ist es eine einfache Aufbereitung von Daten aus Inputs. Modul B setzt zwar
bestimmte Betriebssystemdienste voraus, beispielsweise Speichern von Daten in Files, sonst aber nichts. Modul C verknüpft
dann die Funktionalitäten von Modul A und Modul B, steht also über diesen beiden ersten Modulen.
So weit, so einfach und gut. Man kann also Modul A und Modul B unabhängig testen. Um Modul C zu testen, ist ein getestetes
und schnittstellenabgestimmtes Modul A und Modul B vorausgesetzt.
Nun kann es ein Modul D geben, dass ebenfalls Modul A und Modul B benutzt, aber für andere Funktionalitäten. Das ist eine
zweite vertikale Abhängigkeit von oben nach unten, die aber die selben Module trifft. Wenn das Verhalten eines unteren Mouduls
abhängig von der Aussteuerung von oben ein anderes Verhalten nach oben beeinflusst, dann gibt es versteckte funktionale Abhängigkeiten
ohne formale Abhängigkeiten, die zu vermeiden sind.
Bild: Schnittstelle zwischen 2 horizontalen Modulen Wie ist es mit einer horizontalen Verknüpfung von Modulen? Eine Teilfunktinalität wird von Modul P erledigt, Modul Q erledigt
parallel dazu eine andere Funktionalität, die abgestimmt ist. Dann müssen Modul P und Modul Q eine definierte Schnittstelle
haben. Die Schnittstelle ist unabhängig von den Modulen festlegbar und liegt damit formal weiter unten. Damit ist hier auch
nur eine vertikale Abhängigkeit vorhanden. Nach dem gezeigten Bild könnte man das Modul Q auch unterhalb von P angeordnet
sehen. Das Bild zeigt aber nur einen Ausschnitt. Angenommen es gibt weitere Module und mehrere Schnittstellen zwischen diesen,
dann kann die Parallelität von P und Q deutlicher werden. Außerdem wird die Layer-Anordnung nicht formal bestimmt, sondern
möglicherweise funktional: Die Aufgaben von Modul P und Q liegen auf dem gleichen Layer.
Bild: Test eines Moduls mit Schnittstelle zu einem horizontalen Modulen Die Richtigkeit der vertikalen Anordnung Modul-Schnittstelle zeigt sich auch an den Testmögllichkeiten: . Das Modul P ist
unabhängig von Q testbar, für den Test von P wird die Funktionalität, die die Schnittstelle zu erfüllen hat, mit einem Testmodul
ausgefüllt. Unabhängig davon wird man in der Praxis aber oft den Aufwand einer eigenen Testumgebung für jedes Modul einsparen
wollen. Die Module werden miteinander getestet, in dem jedes seine vor-durchdachte Funktionalität erfüllen sollte und das
Verhalten an der Schnittstelle kontrolliert wird.
Aus Sicht des einzelnen Moduls gibt es nur die vertikalen Schnittstellen. Aus Sicht der Gesamt-Funktionalität bestehen aber Funktionsbeziehungen zwischen Modulen aus dem selben oder gleichen Layer. Daher ist es aus dem Aspekt der Gesamtfunktionalität berechtigt, Modulbeziehungen horizontaler Art zuzulassen, formal sind
aber nur vertikale Beziehungen von oben nach unten zu gestalten.
Eine allgemein anerkannte Software-Architektur-Regel besagt, dass Abhängigkeiten von Modulen nur von oben nach unten oder
horizontal vorliegen dürfen. Die Variante, ein Modul weiter unten (Basisfunktionalität) nutzt Funktionalitäten, die weiter
oben, näher an der End-Anwendung definiert werden, wird ausdrücklich nicht empfohlen.
Diese Regel hat ihre Daseinsberechtigung unter anderem auch deshalb, weil ansonsten eine Basis-Funktionalität eine bestimmte
Anwenderfunktionalität voraussetzen würde. Außerdem könnte man beim Test der Basisfunktionalität keine Zusicherungen machen,
weil unbekannt ist, wie später dazukommende Teile im Zusammenhang mitspielen.
Andererseits, Funktionalitäten der Betriebssystemschicht wie fprintf(...) nutzen Funktionalitäten, die ganz oben im Anwendersystem und dann noch sehr verschieden realisiert sind: Die auszugebenede
Zeichenkette kann an einem Drucker erscheinen, dessen Installation ganz unterschiedlich ist, oder über eine Pipe wo ganz anders
weiterverarbeitet werden. Diese Technik ist verbreitet, etabliert und notwendig. Es ist also nicht so, dass aus Sicht der
Gesamtfunktionalität eine strikte Top-Down-Struktur eingehalten werden muss. Warum funktionieren solche Techniken? Weil die
Schnittstellen, die benutzt werden, unabhängig von einer konkreten Verarbeitung hier eine File-Ausgabe sehr wohl definiert
sind. Die Software enthält nur Top-Down-Strukturen: Immer in Richtung eines bereits definierten und getesteten Teils (Moduls,
Schnittstelle). Wenn an einer Schnittstelle dann ein neues unbekanntes Modul implementierenderweise verbunden ist, dann wird
diese Top-Down-Softwarestruktur nicht durchbrochen. Es sind ähnliche Verhältnisse wie in der Betrachtung der horizontalen
Verbindungen. Die Horizont-Linie darf also auch etwas nach oben gehen, oder steil nach oben.
Bereits bei der horizontalen Verbindung stellt sich die Frage der Verbindung der Module. Bei vertikalen Abhängigkeiten von
oben nach unten ist es immer möglich, bei der Instanziierung eines weiter oben stehenden Moduls die vorhandene Instanz eines
unteren Modul mitzuteilen. Bei horizontalen Verbindungen muss es möglicherweise ein Modul darüber geben, was für die Verbindung
der horizontalen Module zuständig ist. In dieser einfachen Art weitergedacht muss eine Verbindung von unten nach oben von
einem Modul ausgehen, was sich noch darüber befindet. Doch es gibt noch wesentlich mehr Möglichkeiten der softwaretechnischen
Ausgestaltung, wie Module miteinander verbunden werden können. Diese Frage ist im Kapitel $chapter dargestellt.
3.4.3 Formelle Abhängigkeiten bei Compilieren, Linken, Laden
Abhängigkeiten der Compilierung sind offensichtlich: Für einen Compilerlauf müssen andere Module vorhanden sein, sonst gibts Fehler. In C und C++ sind das Headerfiles, die includiert werden. Man kann auch c/cpp-Files includieren, für die Abhängigkeitsdiskussion ist das
derselbe Sachverhalt. Die Prüfung erfolgt hier formell, Schnittstellen auf Compilersyntaxlevel müssen stimmen.
In Java sucht der javac-Compiler aufgrund des angegebenen -sourcepath und -classpath - Aufrufargumentes die benötigten Files. Entweder sie liegen bereits compiliert als class-Files vor, oder die gefundene source.java wird zwischendrin compiliert. Im class-File sind dann die Schnittstellen bytecode-codiert enthalten und werden vom javac-Compiler herausgelesen.
Abhängigkeiten bei der Compilierung führen dazu, dass bei Änderung der Schnittstelle (Headerfile, clazz-File) eine erneute
Compilierung durchgeführt werden muss. Das wird von einem Maker oder einem Versionsmanagement-System erkannt. Auch wenn sich
ein Headerfile nur formal ändert, beispielsweise in einem Kommentar, ist aus File-Zeitstempel-Vergleichssicht die erneute
Compilierung notwendig.
Abhängigkeiten beim statischen Linken: In C und C++ muss eine Executable neu gelinkt werden, wenn ein Objektmodul neu compiliert wurde oder sich eine Library geändert
hat. Das wird ebenfalls von einem Maker oder Versionsmanagementsystemen organisiert. Erneutes Erzeugen eines Executables bedeutet
aber auch: Testen, Ausliefern, also ein gegebenenfalls hoher Folgeaufwand. Womöglich ist eine Library aber nur in einer nicht
hier zutreffenden Funktionalität geändert. Dann muss dies aber erkannt und geprüft werden. Je besser Software-Module voneinander
unabhängig sind, desto weniger formeller Aufwand entsteht.
In Java liegt bezüglich einer "Excecutable" vergleichbare Verhältnisse wie in C++ mit dynamischen Libraries (dll) vor: Es gibt keinen
Linker, die Verbindung der Module wird zur Abarbeitungszeit realisiert. Man kann Klassen in verschiedenen jar-Files speichern.
Beim Aufruf eines Java-Programmes wird der CLASSPATH oder Aufrufargument -cp angegeben, er kann verschiedene jar-Files oder Verzeichnisse mit class-Files enthalten, wobei die Reihenfolge einzelner Path-Bestandteile
eine Rolle spielt. Damit ist es möglich, für die eine oder andere Abarbeitung auf einen Anwendersystem, auf dem noch ganz
andere Java-Software mit anderen Versionen laufen muss, die Versionen passend zusammenzustellen. Das wird man nicht in der
Regel machen, in der Regel sind alle Bestandteile in einem jar-File zusammengefasst und es werden System-jar-Files benutzt,
aber es geht. Damit kann man Versionskonflikte beherrschen. Man kann auch einzelne clazz-Files auf vorhandenen (fremden) jar-Files
löschen oder ersetzen. Jar-Files sind einfache zip-Files und mit jedem zip-Programm, wie es beispielsweise der Total Commander eingebaut bereits kann. Hierbei ist natürlich die Kenntnis der Abhängigkeiten (Welches Modul braucht welches) wichtig.
Einerseits kann ein System meist nicht so gebaut werden, dass ein Modul auf vorhandenen anderen Modulen aufbaut, vielmehr
gibt es Module auf gleichem Level, die zusammengeschaltet werden müssen. Andererseits kann ein Modul, dass als Voraussetzung
für ein anderes Modul gilt, gegebenenfalls noch nicht fertig entwickelt sein oder es soll ausgetauscht werden können. Letzlich
gibt es auch notwendigerweise gegenseitige Verbindungen von Modulen, oder komplexere zirkulare Abhängigkeiten (A braucht B,
B braucht C, C braucht aber A).
Demzufolge müssen Abhängigkeiten gebrochen werden, sonst ist keine unabhängige Entwicklung von Modulen möglich. Klassischerweise
stellt ein Headerfile in C/C++ bereits einen solchen Break dar: Ein Headerfile enthält nur die Schnittstelle zu einem Ablaufcode,
der Ablaufcode selbst, im C-File, interessiert formell nicht. Die Verbindung schafft dann der Linker, aber auch nur formell
über Einsprunglabels. Es gibt mehrere solcher Mechanismen:
3.4.4.1 Interfacekonzept in Java und C++ als Dependency-Break
Das Interfacekonzept, wie es in Java Sprachbestandteil ist und von daher als Grundkonzept der Objektorientierung angesehen werden kann, ist ein
bekanntes und leistungsfähiges Mittel zum Aufbrechen von Abhängigkeiten: Ein Interface beschreibt formell eine Schnittstelle.
Der Aufrufer kann diese Schnittstelle verwenden, ohne dass bereits definiert ist, wie die Implementierung aussehen wird. Es
ist vorab eine Musterimplementierung möglich, die für einen Modultest benutzt werden kann. Es ist ein Austausch der Implementierung
bei unveränderter Schnittstelle möglich, ohne dass dies zur Notwendigkeit einer Neucompilierung führt.
Wenn man so will, ist die Aufteilung von Header- und C-Files in C ein Urvater des Interfacekonzeptes: Im Headerfile wurden
Schnittstellen deklariert, die dann zur Linktime mit den implementierenden Modulen besetzt wurden. Das ist allerdings statisch.
Das Interfacekonzept ist dynamisch:
Es ist möglich, in der selben Executable ein Interface mehrfach zu verwenden, aber jedesmal dahinter eine andere Implementierung
anzubinden.
Es ist möglich, die Implementierung eines Interfaces zur Laufzeit auszutauschen.
Basis dafür sind die so genannten virtuellen Methoden in C++ bzw das dynamische Binden von Methodenaufrufen. Ein solches Verhalten ist auch im reinen C implementierbar, mit Aufruf
von Subroutinen über Funktionszeiger, gegebenenfalls in Methoden-Adresstabellen (Sprungleisten) organisiert.
Der Mechanismus bei Verwendung von Basisklassen, die abstrakt sein können oder nicht, ist hinsichtlich des Aufbruchs von Abhängigkeiten
formell der selbe wie mit Interfaces. In C++ sind Interfaces und Basisklassen formell auch nicht unterschieden. Klassen in
C++ entsprechen dem Java-Interfacekonzept, wenn sie nur abstrakte Methoden enthalten, keine Klassen-Daten und keine implementierten
Methoden. Der Unterschied von Interfaces und Basisklassen liegt an anderer Stelle, im Bereich der Implementierung, Mehrfachvererbungsprobleme
und dergleichen. Allerdings ist aus Software-Design-Sicht für die Abhängigkeitsdiskussion schon ein Unterschied vorhanden.
Ein Interface definiert nur eine Schnittstelle, keinerlei Implementierung wird vorausgesetzt.
Wenn ein Modul über eine Basisklasse angesprochen wird, dann wird eine Grundeigenschaft vorausgesetzt, zwar noch nicht die
komplette Implementierung, aber eine gewisse Implementierung.
Auch wenn sich eine Klasse nur über Interfaces oder Basisklassen nach außen zeigt, so muss sie doch an einer Stelle in ihrer
ganzen Vollständigkeit bekannt sein: Bei ihrer Instanziierung. Es sei denn, man benutzt eine Factory.
Wenn eine Klasse bei ihrer Instanziierung bekannt sein muss, dann muss dasjenige Modul, das instanziiert, neu compiliert und
ausgeliefert werden, wenn sich die instanziierte Klasse, in einem anderen Modul ändert. Damit sind dynamische Konzepte nicht
gut nutzbar. Oder es werden Fehler gemacht: In C oder C++ kann sich ein Headerfile ändern. Es wird aber vergessen erneut zu
compilieren. Damit sind Daten und/oder virtuelle Methoden verschoben. Beim Linken wird der Fehler nicht bemerkt. Der Fehler
wird womöglich zunächst gar nicht bemerkt, weil die Verschiebung nicht für alle Funktionalitäten auffällt.
Bild: einfache Factory Eine einfache Factory funktioniert so, dass eine statische Methode oder auch nicht-statische Methode einer Factoryklasse
gerufen wird. Die Factoryklasse muss die zu instanziierende Klasse kennen, das instanziierende Modul muss die Factoryklasse
kennen. Die Factoryklasse kann aber wesentlich stabiler - nicht von Änderungen betroffen sein, da sie eigentlich nur die Factorymethode,
sonst nichts weiter enthält. Die Factoyklasse gehört zu dem Modul, dessen Klassen sie instanziiert. Factories können aber
in eigenen Packages geführt werden, Abhängigkeiten können dann auf gesamte Packages bezogen werden. Die Instanz wird dem Aufrufer
"nur" über ein Interface oder eine Basisklasse bekanntgegeben. Das reicht für den Zugriff. Damit ist eine weitestgehende Entkopplung
erreicht.
Ein komplexes Factory-Pattern beherrscht noch die Fabrikation zueinandergehöriger Instanzen, im Schulbeispiel oft mit "Fischgericht"
und den zugehörigen Bestecks dargestellt. Das ist aber ein anderer Gesichtspunkt.
Es gibt noch eine weitere Abstraktion, bei der nicht einmal die Factoryklasse compilertechnisch bekannt sein braucht: Die
Instanziierung mittels textueller Angabe des Namens/Packagepfades der Factoryklasse. Das Suchen und Instanziieren der Factoryklasse
wird dann vom Laufzeitsystem, in Java von der Virtuellen Maschine, vorgenommen. Die Factoryklasse muss die bekannte Factory-Methode
bereitstellen, die Instanz muss sich über ein Interface repräsentieren. Mehr ist seitens der formellen Abhängigkeit nicht
notwendig - eine weitestgehende Entkopplung geeignet für unabhängige Module.
3.4.4.4 Dependency Injection - Außeneinprägung der Abhängigkeit
Nach dem Factory-Pattern gibt es noch eine weitergehende Vermeidung von Abhängigkeit. Mit dem Factory-Pattern braucht zwar
ein Modul keine Detailkenntnis dessen, was instanziiert werden soll, es muss aber wissen was es instanziiert. Damit ist vorbestimmt,
dass Modul A ein Modul Y mit dem Interface y benutzt, und nicht etwa Y1oder Z. Besser wäre es aber, das Modul kennt nur die
Schnittstelle. Alles andere ist Sache einer darüberliegenden Schicht. Diese kann beispielsweise aufgrund verschiedener Konfigurationsangaben
das eine oder andere Modul instanziieren und zuordnen. Das Konzept erweist sich auch für den Modul-Test als essentiell: Normalerweise
wird Modul Y benutzt. Im Test aber statt dessen ein Modul Y_test, ohne dass an dem zu testenden Modul etwas geändert wird.
Auch für eine unabhängige Entwicklung ist die Dependency-Injection ein gutes Mittel: Modul A wird fertiggestellt, ohne dass
Modul Y dazu irgendwie benötigt wird, man kann bis zur Integration einen einfachen Ersatz mit selber Schnittstelle benutzen.
Entwicklerteams können unabhängig voneinander arbeiten. Dependency-Injection kann daher als ein Muss einer guten Entwicklung angesehen werden.
Eine Library ist ein File, der Software bestimmter Funktionalität enthält. In der klassischen C-Programmierung ist eine Library
eine Zusammenstellung von an sich unabhängigen Objectfiles, die als Ergebnis der Compilierung von Quellen entstanden sind.
In Java ist eine Library eine Zusammenstellung von class-Files, ebenfalls als Ergebnis der Compilierung. Eine Library wird
oft auch als Archiv bezeichnet, was sich an der File-Extension bemerkbar ist (.a für Libraries der GNU-Compilierung, .jar ist ein Java ARchiv.
Eine Library verbirgt den Quelltext. Der Quelltext ist in der Library selbst nicht mehr präsent. Allerdings enthält eine Library
alle global notwendigen Bezeichner (Identifier) aus dem ursprünglichen Quelltext. Damit ist eine Rekonstruktion des Inhaltes mindestens etwas erleichtertert. Java-class-Files
lassen sich formal in einen Java-Quellcode zurückübersetzen, adäquat wie Maschinencode zu Assembler. Allerdings fehlen Kommentare,
einige Konstrukte können in der Rückübersetzung mehrdeutig dargestellt werden.
Eine Library kann dynamisch verwendet werden. Der statische Fall liegt vor, wenn der Linker Objectfiles aus der Library fest in eine Executable einbindet.
Dabei werden immer nur die notwendigen Object-Bestandteile, nie prinzipiell die gesamte Library eingebunden. Eine Library
kann also sehr groß sein und bestimmt damit nicht, dass auch die Executable groß sein muss.
Dynamisch wird eine Library verwendet, wenn Bestandteile erst beim Ablauf, und dann erst wenn notwendig geladen werden. Das
bedingt das Vorhandensein eines Loaders. In Windows sind die DLLs üblich. In Java werden alle class-Files dynamisch geladen.
Man kann das Laden in der Startphase oder in einer Ruhephase ausführen, in dem man den ClassLoader anspricht oder inital eine
Methode der jeweiligen Klasse aufruft. Dann geht es beim ersten Aufruf schneller.
Das dynamische Laden ermögllicht den Austausch der Library vor dem Start ohne einen neuen Generierprozess zu erfordern. Ein
zweiter Aspekt des dynamischen Ladens ist die Verwendung des selben Codes von verschiedenen Applikationen (Code sharing).
Statisch gebunden ist ein Code in der Applikation fest verankert, und in einer anderen gegebenenfalls gleichzeitig ablaufenden
Applikation ebenfalls, damit doppelt im Speicher vorhanden. Ein dynamisch geladener Code kann von mehreren Applikationen verwendet
werden, wenn der Lader dies unterstüzt. Allerdings gibt es gegebenfalls das Problem von Versionskonflikten.
3.5.1 Der Zuschnitt von Libraries
Topic:Programming.ModulStructure.Libs.lib_spec
Libraries sind zunächst nur eine Ansammlung verschiedener unabhängiger Ergebnisse von Compilierungseinheiten (Objectfiles, class-Files). Diese Teile müssen nicht in irgendeinen Zusammenhang stehen. Die Rolle von Libraries, sich als
etwas Ganzheitliches zu repräsentieren, ist nicht formeller Natur sondern vom inhaltlichen Zusammenhang der zusammengebundenen
Files bestimmt. Man kann also auch Libraries bilden ohne wirklichen inhaltlichen Zusammenhang. Meist werden Libraries jedoch
als ein Modul oder eine Softwareschicht verstanden., die in dieser Form der Anwendung repräsentiert wird.
3.5.2 Zusammenhang zwischen Libraries, Quellen und Makefiles
Häufig werden die Quellfiles und die zugehörigen Make-Files zusammengefasst und als Quellen einer bestimmten Library aufgefasst.
In einer unifizierten Umgebung wie beispielsweise als Bestandteil eines Betriebssystems wie UNIX oder LINUX ist das oft praktisch.
Man kann Software entweder per Quelltext verteilen und einziehen, in dem man die Libraries selbst compiliert und dann verwendet,
oder man kann Binärcode, nur die Library einziehen, wobei Headerfiles dazu passen müssen. Der Weg über den Quelltext hat den Vorteil der Anpassbarkeit
von Details, beispielsweise abgeänderten Strukturdefinitionen für Schnittstellen.
In einer Embedded-Controll-Umgebung muss der Zusammenhang von Quellen und Libraries aber etwas modifiziert gesehen werden:
Quellen sollen möglicherweise wiederverwendet werden. Das kann bedeuten, verschiedene Embedded-Controll-Plattformen oder verschiedene
Applikationen sollen die selben Quellen verwenden.
Oftmals soll die Funktionalität, die in Libraries embedded eingesetzt werden soll, auf einem PC getestet werden. Dabei wird
die korrekte Funktionalität der Quellen getestet.
Damit ist der Zusammenhang Quelle - Makefiles- Library nicht mehr ein direkter. Quellen sind eigenständig, können und sollen
in verschiedenen Zusammenstellungen verwendet werden. Die Makefiles gehören jedoch zur Library oder zu einer Applikation.
3.5.3 Zuschnitt von ähnlichen Libraries für verschiedene Anwendungen
Topic:Programming.ModulStructure.Libs.SpecialSrc
Libraries für verschiedene Zielsysteme und Anwendungen sollten dennoch den gleichen Zuschnitt der Funktionalitäten aufweisen,
wenn sie für einem adäquaten Kontext angeboten werden. Dies ist zwar nicht grundsätzlich technisch erforderlich, erleichtert
aber die Anwendung. Günstig ist es, genau die selben Schnittstellen, sprich Subroutinen auf Maschinenebene oder interfaceimplementierende
Klassen etwa für Java-Archive zu haben. Das bedeutet aber nicht, dass alle Implementierungen identisch sein müssen, sprich
aus den selben Quellen gebildet werden.
Die meisten Funktionalitäten sollten aus den selben Quellen gebildet werden. Dann ist der Test der Software auf Quellbasis
für ein Zielsystem oft schon ausreichend für den Test der Quellen an sich und deren Anwendung in einer Library. Jedoch können
Unterschiede notwendig sein. Beispielsweise kann in einem Zielsystem eine Fehlermeldung für Debugzwecke einfach mit printf(...) ausgegeben werden. Ein anderes Zielsystem verfügt aber über keinerlei Monitor, daher kann diese Debug-Fehlermeldung dort
statt dessen in einen bestimmten Puffer im RAM abgelegt werden, der anderweitig kontrolliert wird.
Das Bild soll solche Verhältnisse andeuten: Die meisten Sources werden aus einem einheitlichem Quell-Pool entnommen. Bestimmte,
meist wenige Sources gehören jedoch zu der Implementierungsplattform und daher zum Source-Pool der Library-Bildung zusammen
mit den Makefiles. Diese Pools sind wichtig für eine Source-Konfigurations- und Versionsverwaltung.
3.6 Schichtenstruktur von Software
Topic:Programming.ModulStructure.Layer
Topic:Programming.ModulStructure.Layer.xxx
3.6.1 Betriebssystemanbindung
Topic:Programming.ModulStructure.Layer.os_header
4 Programmiersprachen
Topic:Programming.Languages
Topic:Programming.Languages.Assembler
Die Assemblerprogrammierung stellt die fast direkte und einfachste Form der Verbindung eines Programmes mit dem, was der Prozessor
ausführen soll, dar. Noch direkter ist die Angabe des Maschinencodes als Bytefolge. Das ist diejenige Art, wie Konrad Zuse
1943 seinen Z3 programmiert hat. Assembler ist zunächst nahe am Maschinencode und beschreibt die Maschinencodebefehle in einer
besser lesbaren Mnemonic. Dazu kommen aber noch Eigenschaften wie Arbeit mit Labels (Sprungmarken, Adressen für Daten), Makros,
Pseudobefehle zur Definition bestimmter Daten, Angaben zur Auswahl von Speicherbereichen und weiteres. Man kann heute noch
zweckgebunden in Assembler programmieren und tut dies auch, wenn es um maschinen / hardwarenahe Dinge geht. Die Assemblerprogrammierung
tritt auch in modernen Programmierumgebungen dem Bediener entgegen, wenn man beispielsweise beim Debuggen auf Einzelbefehle
und Register schaltet. Man kann sich als Zwischenergebnis der Compilierung eines C- oder C++-Programmes ein Listing-file ausgeben lassen. Dieses Listing enthält die vom Compiler erzeugten Assemblerbefehle zusammen mit dem Quell-C-Code, Speichersegmentangeben,
Maschinenbefehle. Dort ist genau erkennbar, wie die Umsetzung von C-Konstrukten in Maschinencode erfolgt. Der Blick auf Listings
und Maschinencode kann zwar durchaus interessant sein für Maschinencode-Neugierige, aber vollkommen unnötig, da das Programmverhalten
anhand eines Quellcodes von C, C++ auch beurteilt werden kann. Aber wenn es um hardwarenahe Dinge oder genaue Analysen geht,
ist der Blick auf den Maschinencode wichtig.
Bezüglich Abbildung C auf Maschinencode sind Schritte der Optimierung zu beachten. Verschiedene Optimierungen werden bereits
vom C- oder C++-Compiler ausgeführt. Doch nach Bildung des Assembler- oder Maschinencodes kann eine nochmalige Optimierung
stattfinden, die nach formalen Aspekten Befehle umgruppiert, um letzlich unnötige Maschinenbefehle zu sparen. Mit dieser Optimierung
ist aber keine 1:1-Abbildung einzelner Maschinenbefehle zu C(++)-Zeilen mehr möglich.
Topic:Programming.Languages.StructuralProgramming
Die Assemblerprogrammierung kennt für Programmverzweigungen nur die Möglichkeit eines bedinten oder unbedingten Sprunges.
Auch Programmiersprachen wie FORTRAN, BASIC folgen dieser Möglichkeit, selbst in C und aus Kompatibilität in C++ gibt es die
goto Label-Anweisung. Bei komplexeren Programmen kann aber der Überblick über einzelne goto's verlorengehen. Daher hat man bereits
in den 60-ger Jahren die Strukturierte Programmierung erfunden, präsentiert als erstes mit Algol. In C wurden dann alle Konstrukte der Strukturierten Programmierung als Sprachbestandteil übernommen. Die Strukturierte Programmierung
ist heute Allgemeinwissen. Dennoch trifft man selbst heute einerseits immer wieder auch jüngere Programmierer, die meinen,
dass ein goto für bestimmte Fälle das beste Sprachmittel sei. Andererseits ist vielen oft nicht bewusst, dass die Anweisungen break, continue und ein return mitten aus einer Subroutine heraus eine Art goto darstellt und die Struktur zerstört. Man muss hier die Pflegbarkeit der Software, die spätere oder fremdbezogene Durchschaubarkeit
von Algorithmen im Sinn haben. Ein geschickt gesetztes return mittendrin wird schnell mal übersehen. Ein übersehenes continue führt bei Änderungen im Algorithmus gegebenenfalls zunächst zu Fehlern, die erst im Test entdeckt werden.
4.1 Das ursprüngliche C
Topic:Programming.Languages.C_1970
Die Programmiersprache C ist in den Anfängen der1970-ger Jahre zusammen mit Unix entstanden. Die strukturierte Programmierung,
vorher schon in Algol etabliert, war von Anfang an wichtiger Sprachbestandteil. Auch die Strukturierung von Daten (struct) war berücksichtigt, der erste Schritt hin zur Objektorientierung. Die Objektorientierung selbst war aber noch nicht im allgemeinen
Programmiererdenken verankert.
C hat die Nähe zum Maschinencode nicht nur deshalb erhalten, weil es eben erst 1970 war, sondern weil dies als klare Möglichkeit
der Ablösung der Assemblerprogrammierung designed war. So sind in C auch direkt Assemblerbefehle mischbar, wenn man diese
braucht (inline-Assembler). Das man bis auf die Assemblerebene heruntermuss, ist so, wenn man Treiber und andere hardwarenahe
Funktionalitäten implementiert.
C hat einige Konzepte auch bezüglich Gestaltung von Betriebssystemschnittstellen mitgebracht, auch aus der UNIX-Nähe. Dazu
gehört die Arbeit mit dem Filesystem. Einige Ideen wie die 0-terminierten Strings waren für die damalige Zeit angemessen.
C hat auch heute seine Bedeutung nicht verloren. Immer noch sind maschinennahe Dinge zu programmieren, insbesondere im embedded
Bereich auch bis auf Anwendungsebene. Einfach zu ersetzen ist C keinesfalls. Allerdings, für umfangreiche Algorithmen sollte
man heutzutage nicht bei C verharren.
4.2 C++
Topic:Programming.Languages.Cpp
Nachdem Ende der 1980-ger Jahre die Objektorientierung stark im Gespräch war, die Anforderungen an Software entsprechend gewachsen
und C sehr verbreitet und beliebt war, lag es nahe, die Objektorientierung in das C-System hineinzubringen, C damit aufzuwerten.
Damit war C++ eine der ersten vollständig objektorientierten Sprachen und gleichzeitig sofort bekannt. Allerdings hat es eine
Weile gedauert, bis C++-Compiler auch für kleinere Prozessoren ausgereift vorhanden waren. Der Zustand heute ist, dass C++
ähnlich weit verbreitet ist wie C. C wird immernoch eine Daseinsberechtigung zugesprochen, aber manche Zweifler fragen warum.
Viele Eigenschaften von C wurden nach C++ übernommen. Das Ziel war eine Aufwertung von C mit Objektorientierung bei gleichzeitiger
Wahrung der Kompatibilität. Dieses Ziel ist erreicht. C hat wegen Notwendigkeiten der Effektivität der Maschinencodenähe beispielsweise
die Möglichkeit der relativ freien Zeigerarithmetik. C++ auch. In C lassen sich Daten wahlweise im Stack anlegen, global in
bestimmten Speicherbereichen, die Hadwarespeicheradressen zugeordnet werden können, oder auf einem Heap allokieren. In C++
auch. Damit ist aber C++ wegen der Wahrscheinlichkeit der Programmierfehler in solchen Ecken für große und komplexe Projekte
genauso wie C eher weniger geeignet. Typische Fehler sind beispielsweise: Definieren einer Struktur im Stack, weitergegen
des Zeigers zunächst erstmal an tiefer geschachtelte Routinen. Das ist noch richtig. Irgendwann gibt es dann eine Korrektur,
bei der der Zeiger in einem anderen Thread verwendet wird. Vorläufig fällt der schwere Fehler nicht auf... Oder vergessene
delete für allokierte Objekte, wenn diese an verschiedenen Stellen benutzt werden, also nicht einfach vom Anleger gelöscht
werden dürfen. Bei kleineren Programmen kann man solche Dinge noch eher überblicken.
Eine weitere Schwäche von C++ ist dessen Implementierung des dynamischen Bindens. Das dynamische Binden ist eine Grundeigenschaft
der Objektorientierung und insbesondere für Interfaces oft genutzt. In C++ sind das die virtual-Methoden. Der Zeiger auf die dafür notwendige sogenannte virtuelle Tabelle (vTbl) befindet sich in den Daten. Gibt es jetzt irgendwie geartete Softwarefehler, die Daten unkontrolliert verschieben, dann
kann der Zeiger auf die vTbl entweder vollkommen falsch sein, was meist zu einem Absturz führt, oder es wird ein formell richtiger Zeiger auf eine andere
virtuelle Tabelle dorthin kopiert, oder der Zeiger um wenige Bytes verschoben. Dann wird einfach die falsche Methode gerufen,
nichts stürzt ab und erstmal merkt es niemand. Das Problem ist, dass der Softwarefehler möglicherweise in einem ganz anderen
Modul steckt und fremde Daten verändert. Einerseits findet man solche Fehler schwer, andererseits: Für sicherheitsrelevante
Software ungeeignet.
Als Fazit kann man durchaus zu der Meinung kommen, das C++ vollkommen ungeeignet ist.
4.3 Java
Topic:Programming.Languages.Java
Java ist ...TODO Quellen von Java, kurze Geschichte
4.3.1 Eigenschaften von C++, die nicht in Java übernommen wurden.
Topic:Programming.Languages.Java.CppNotInJava
Man kann sich auf den Standpunkt stellen: Was im Jahre 1994 im neu entwickelten Java an ObjektOrientierten Dingen aus dem durchaus damals schon etabliertem C++ konzeptionell
nicht übernommen wurde, sind die weniger guten Lösungen der ObjektOrientierung. Selbstverständlich kann diese Aussage auch angezweifelt werden. Folgende Übersicht möchte diese Dinge benennen, folgende
C++-Konzepte gehen in Java nicht:
private oder protected Basisklassen:
class Example: private Base{...}: //C++
Die private-Vererbung ermöglicht die interne Nutzung der Eigenschaften der vererbten Klasse, ohne dass die erbende Klasse dies nach außen
zeigt. Man kann also nicht von einer is-a-Beziehung reden (ist eine). Damit wird an der eigentliche Intension der Vererbung in der ObjektOrientierung vorbeidesignt. Die Nutzung der Eingenschaften
ohne die is-a-Beziehung fördert eher noch eine gegebenenfalls falsche Nachnutzung. Beispiel: Eine Klasse Quadrat enthält das Attribut für die Seitenlänge. Leiten wir von Quadrat ab, setzen wir noch die fehlende Seite
hinzu, dann haben wir mit wenig Aufwand die Klasse für Rechteck. Das Fehlen der private-Vererbung in Java schützt also vor falsch designter Software.
Die Funktionale Programmierunghttp:xxx stellt einen anderen Schwerpunkt der Softwaregestaltung in den Vordergrund als die Objektorientierte Programmierung, beide
Paradigma der Softwareentwicklung stehen nebeneinander. In der Funktionalen Programmieurng werden Algorithmen ähnlich einer
mathematischen Funktion aufgefasst: Eine Funktion bildet Eingangswerte auf entsprechende Ergebnisse ab. Es werden keine anderen
Daten beeinflusst, nur die Ergebnisse werden geliefert. Damit orientiert die Funktionale Programmierung auf Nebenwirkungsfreiheit:
y = function(x, param);
Der Begriff Funktion ist dabei nicht zu verwechseln mit dem Wortgebrauch Funktion in C. Zwar werden in der Realisierung der Funktinalen Programmierung in C die C-Funktionen aufgerufen. Eine C-Funktion oder
Methode in Java oder C++ entspricht aber nur dann dem Ansatz der Funktionalen Programmieurng, wenn sie nur Ausgangswerte liefert
und keine anderen Werte beeinflusst.
In C++ kann man die Aussage, dass dies zurifft, formell einer Compilerüberprüfung überlassen. Man muss alle Input-Zeiger als
const bezeichnen und die gesamte Methode als const definieren. class Example { ReturnType function(Type const* arguments)
const; ... } In C gilt dies adäquat. Zu beachten ist zudem, dass in der Funktion/Methode keine globalen Variable gesetzt
werden. In Java kann man die formelle Überprüfung leider nicht dem javac-Compiler überlassen. Das kann als Schwäche von Java
gegenüber C++ angesehen werden. Die Möglichkeit der const-Definition der referenzierten Daten geht dort nicht. Wenn man in
Java schreibt: method(final Type data), dann bezieht sich das final nicht auf den Inhalt von data, sondern auf die Referenz selbst. In C oder C++ wäre das mit method(Type * const data) auszudrücken. Wichtig ist die Stellung des const hinter dem Stern. In Java hat man also nur die Möglichkeit der Handkontrolle
oder die Nutzung weiterer Tools neben dem javac-Compiler, um sicherzustellen, dass eine Methode keine Daten ändert.
Wenn eine Funktion einfache Ergebnisse produziert, int, float oder dergleiche, dann ist das kein Problem. Oft sollen aber
komplexere Daten ermittelt werden. In der allgemeinen Schreibweise ReturnType function(args); ist das ersichtlich. In
Java wird in solchen Fällen entweder in der Funktion (Java-Methode) ein neues Objekt angelegt, oder die Referenz auf ein bestehendes
Objekt zurückgegeben. In C und C++ ist das ähnlich realsiierbar, wenn der Rückgabetyp ein Zeiger oder eine C++-Referenz ist.
Bei der funktionalen Programmierung dürfen Funktionen grundsätzlich keine Werte verändern. Das widerspricht teils dem Paradigma
der Objektorientierten Programmierung: Methoden beeinflussen Objekte. Im folgenden Beispiel soll eine Aktion genau dann ausgeführt
werden, wenn ein bestimmter Zustand eines anderen Objektes vorliegt. Die Aktion soll aber nur einmal ausgeführt werden, das
heißt, wenn der Zustand als vorliegend erkannt wurde, muss er rückgesetzt werden. Streng funktional müsste man wie folgt programmieren:
Die Abfrage object.testSpecState() ist streng funktional nach dem Muster: Eine Abfrage darf nicht noch nebenher Daten verändern, keine Seiteneffekte. Man kann sich die Idee zu eigen machen, Abfragen nur abfragend, nicht ändernd zu gestalten. Der Haken ist aber folgender:
Hat man mehrere Threads,
4.5 Namensgebung von Bezeichnern
Topic:Programming.Languages.IdentNotation
Das Allerhäufigste in einem Programm sind Bezeichner (identifier). Alles ist bezeichnet: Variablen, Attribute, Referenzen, Methoden, Typen, Makros, Filenamen, Package- und Verzeichnisnamen.
Bezeichner innerhalb von Programmen in C, C++, Java und auch den meisten anderen Programmiersprachen beginnen grundsätzlich
mit einem Buchstaben, klein oder groß, und enthalten eine Folge von Buchstaben und Ziffern und den Unterstrich _. Teilweise gibt es eine Begrenzung, ältere C-Compiler verarbeiten max. 32 Zeichen. Dabei kann es sein, dass der Bezeichner
länger sein darf, aber nur die ersten 32 Zeichen sind signifikant. Moderene Compiler haben diese Begrenzung nicht, aber ein
zu langer Bezeichner ist schlecht lesbar. Ein Bezeichner darf auch mit einem _ beginnen. Das ist allegemein zulässig. Jedoch sollte deren Verwendung meist auf System-Bezeichner beschränkt werden, der
Anwender sollte sich dabei zurückhalten. Das ist eine Stilfrage, dem Compiler ist das egal.
4.5.1 Mehrdeutigkeit und Sichtbarkeit von Bezeichnern
Bei der Vielzahl von Bezeichnern und deren freie Wahl sind Konflikte nicht unwahrscheinlich. Zu Zeiten, in denen es nur globale
Variable gab, war deren Anzahl meist noch überschaubar. Man hat sich oft auch auf Prä- und Postfixregeln eingestellt, die
aber die Lesbarkeit eines Programmes nicht gerade erhöhen.
Mit der Möglichkeit der Strukturierung von Daten ist die Sichtbarkeit eines Bezeichners begrenzt, damit sind Mehrdeutigkeiten
zumindestens formell compilerseitig ausgeschlossen. Allerdings gibt es Verwechslungsmöglichkeiten beim Lesen und Schreiben
eines Programmes. In C sind Daten auf zweierlei Weise strukturierbar:
Elemente einer struct-Definition sind nur zusammen mit dem Strukturtyp benutzbar und damit darin gekapselt.
Es gibt die Möglichkeit, globale Variable und Routinen (C-Funktionen) innerhalb eines Files als static zu kennzeichen. In diesem Fall bedeutet static, dass die Elemente nur im C-File vom Compiler sichtbar sind, sie werden nicht dem Linker als globales Label angeboten. Man
kann damit selbe Bezeichner in verschiedenen C-Files verwenden.
Die Änderung der Bezeichnung eines Bezeichners ist eine häufig zu empfehlende Tätigkeit, wenn Details eines Programmes eher
mit der Bearbeitung des Programmquelltextes entstehen als in einer strengen Planungsphase. Letzteres ist in der Ausprogrammierung
von Details meist der Fall.
Man wird bei der Anlage einer neuen Variable, Methode oder Referenz nicht zuviel Zeit mit der Festlegung des Namens verbringen
wollen, weil es zunächst erstmal um die zu relalisierende Funktionalität geht. Also wird man etwas auf die allgemeine Namensgebung
im Umfeld schauen und dann einen passend erscheinenden Namen festlegen. Erst mit einer Nachbearbeitung, verbunden mit dem
Blick auf die Gesamt-Struktur wird ein Name gegebenenfalls doch weniger geeignet, besser anders erscheinen. Eine Umbenennung
erscheint angebracht, um die Softwarequalität (Verständnis, Lesbarkeit, spätere Wartbarkeit) zu verbessern.
Eine Umbenennung ist mit moderenen Entwicklungsumgebungen, Compilerunterstützung und guter Struktur eigentlich überhaupt kein
Problem. Man sollte dann umbenennen, wenn keine Compiler- und Linkerfehler vorhanden sind, also in einem guten Programmzustand.
Arbeitet man mit Eclipse und Java, gibt es die Funktion Refactor - Rename. Diese arbeitet einfach und dann sicher, wenn der Bezeichner eine entsprechend nicht zu große Sichtbarkeit hat. Das Umbenennen
macht Eclipse an allen Verwendungsstellen automatisch, also schnell, sicher, problemlos. Man kann dann auch verschiedene Bezeichnungen
ausprobieren, schauen wie sie beim Lesen an verschiedenen Stellen wirken. Grundlage für die sichere Arbeit ist die Kapselung.
Ein private-Element kommt nur auf Klassenebene vor, ist also von Eclipse garantiert überall zu finden. Package-private ist
ebenfalls sicher, da meist das gesamte Package im Eclipse vorliegt. Eclipse sucht und korrigiert in allen Files des Packages.
Ist ein Bezeicher public oder protected, dann kann er irgendwo außerhalb verwendet werden, und das kann aus Sicht eines Projektzuschnittes nicht erkannt werden.
Die Korrektur kann dann also nicht überall automatisch erfolgen. Darf auch nicht, denn es muss dem externen Benutzer eine
Versionswahl und Selbstentscheidung zugebilligt werden. An dieser Stelle wird aber klar, dass man aus Softwarepfege-Gründen
immer so dicht wie möglich kapseln sollte, die Kapselung erst dann aufbrechen wenn es dazu eine Notwendigkeit gibt.
Für die Auswirkungen auf Bezeichneränderungen für externe Nutzer gibt es folgende Richtlinien:
Die Information aller bekannten Nutzer über die geplante Änderung kann organisatorisch gegebenenfalls zu komplex werden und
das Vorhaben damit erschwierigen.
Änderungen sind innerhalb einer laufenden Bearbeitung eher nicht angebracht, besser zu einem Hauptrelease. Dann sind sie auch
ankündigbar.
Den Nutzern muss die Änderung erklärt werden. Andererseits muss ein Nutzer innerhalb eines Entwicklungsteams auch bereit sein,
eine Mehrarbeit zu tragen, die sich mit der Verbesserung der Gesamt-Wartbarkeit begründen lässt.
Die Änderung, die der Nutzer ausführen muss, ist an sich nur die Umbenennung, manuell oder mittels intelligentem Suche/Ersetzen.
Dabei sollte eine Compilierung alle Fehlerstellen richtig anzeigen. Die alte und neue Benennung muss bekannt sein. Damit ist
diese Arbeit nicht aufwändig, mechanisch ausführbar und sollte damit akzeptabel sein.
Wichtig ist, dass die neuen und alten Namen kein Konfliktpotenzial haben und eindeutig vom Compiler erkannt werden. Absolut
ungünstig ist es, vormals A nach B umzubenennen, und dafür statt B dann A, und beide Elemente sind vom gleichem Typ. Das wird vom Compiler nicht erkannt und vom Nutzer übersehen. Möglicherweise muss
man in solchen Fällen mehrstufig umgehen.
Damit dauert eine Umbenennungsaktion globaler Bezeichner eine längere Zeit. Nutzer greifen gegebenenfalls teilweise noch auf
ältere Revisionen zurück und stellen dann um, wenn es für sie notwendig ist.
Hat man einen Bezeichner einfach A1, System oder dergleichen genannt und ist dieser auch noch global, dann sind erstens Namenskonflikte recht wahrscheinlich, und zweitens
ist bei einer Suche die Wahrscheinlichkeit von Fehlertreffern recht hoch. Die Suche findet meist auf Textebene statt und kann
dann nicht die Sichtbarkeit (Strukturzuordnung des Bezeichners) nutzen. Man sollte also nicht extrem kurze oder allgemeine
Bezeichner wählen sondern besser etwas längere mit einem eigenem Touch. Das ist auch für die Lesbarkeit besser. Beispiel: Eine Entfernung in einer Wegregelung könnte ja als private Attribut einfach way heißen. Es gibt aber im Modul daneben auch einen way mit einer anderen Bedeutung. Nenne man den einen Weg doch besser wayMotor, obwohl eigentlich unnötig aus lokaler und Sichtbarkeits-Sicht. Aber es ist eindeutig.
Bezeichner sollten aber auch nicht zu lang sein, sondern gut erfassbar und gut zuordenbar. Hilfreich sind wiederkehrende Abkürzungs-Silben.
Zuviel Ballast in Bezeichnern hilft meist nicht.
Als Querschläger (englisch ricochet aus der Waffentechnik) sollen nicht beabsichtigte, fehlerhafte Nebenwirkungen des Ablaufes von Software bezeichnet werden.
Die Bezeichnung Seiteneffekt ist dafür zu schwach und daher unzutreffend. Ein Seiteneffekt ist eine Wirkung des Ablaufes von Software, die im gegebenen Fall vom Programmierer nicht beachtet wurde, aber regulär auftritt
und auch in Beschreibungen und dergleichen zu finden ist.
Querschläger entstehen aufgrund von Softwarefehlern und zerstören Daten in fremden Bereichen. Die Wirkung von Querschlägern
ist oft nicht unmittelbar zu spüren, sondern erst dann, wenn die zerstörten Daten eine Rolle spielen. Damit sind Querschläger
oft schwer zu finden. Im nachgestelltem Debugging treten sie gegebenenfalls nicht auf, weil andere Bedingungen (meist zeitlich)
gelten.
Als Beispiel eines Querschlägers soll folgendes Szenario angegeben werden. Das Szenario könnte in der Praxis der C/C++-Programmierung
entstanden sein.
Der eigentliche Softwarefehler besteht darin, dass ein Array zu klein angelegt wurde beziehungsweise der Index unkontroliert
überläuft. Angenommen, nach dem Array folgt im Speicher ein Zeiger:
struct { int array[10]; Type* ref; } example;
Der Fehler ist deshalb nicht bemerkt worden, weil in bisherigen Tests nie eine volle Ausbaustufe verwendet wurde. Der Fehler
tritt erst in der Praxis mit einer bestimmten Konfiguration auf, erst in dieser Konfiguration ist der
Damit wird der nach dem array folgende Zeigerwert getroffen und auf einen vollkommen falschen Wert gesetzt. Das ist noch kein Querschläger, denn diese
Operation trifft die eigenen Daten. Diesen Fehler würde man beim debuggen bemerken, wenn man in dieser Situation debuggen
würde.
ref->data = otherValue;
Wenn dieser Befehl abgearbeitet wird, dann wird irgendwo im Speicher aufgrund der falsch gesetzten Referenz ein falscher Wert
geschrieben. Das ist der Querschläger.
Die Szenarios, wie Querschläger entstehen, können vielfältig und komplex sein. Die Ursache sind immer nicht entdeckte Softwarefehler.
Die Auswirkung sind irgendwo nicht nachvollziehbar geänderte Werte, es kann beliebige Folgefehler geben. Oft werden erst die
Folgefehler äußerlich bemerkt, und man weis nicht, wie es dazu kam.
Bemerkte Querschläger Meist entstehen Querschläger dadurch, dass Zeigerwerte falsch beeinflusst werden. Hat man eine Ablaufumgebung mit protected memory, dann kann ein beliebig geänderter Zeiger eine Adresse enthalten eines nicht vorhandenen bzw. geschützten Speicherbereiches.
Die Ausführung eine Speicherzugriffes, lesend und/oder schreibend, löst dann auf Hardware- bzw. Betriebssystemebene eine Exception
wegen Speicherschutzes aus. Damit wird der Querschläger verhindert und bemerkt. Allerdings kann es immernoch unklar sein,
warum ein Zeigerwert derart falsch steht. Der Fehler kann im betreffenden Modul aufgefunden werden, oder er kann selbst aufgrund
eines Querschlägers entstanden sein.
Die Leistungsfähigkeit von Prozessoren steigt von Jahr zu Jahr, damit auch die Menge an Software, die dort unterbringbar ist.
Das hält Schritt mit den wachsenden Anforderungen, was denn ein System so alles tun soll. Damit muss man aber immer mehr Software
sichten und auf Sicherheit prüfen. Einiges wird von formellen Prüfungen mit Tools erledigt, aber eine Handsichtung ist oft
notwendig. Der Aufwand steigt.
Andererseits gibt es den Wunsch nach Softwarekorrekturen aufgrund Kundenwünsche oder geänderten Anforderungen, die aber eine
erneute Prüfung der Software notwendig weden lassen. Geprüfte Software und der Wunsch nach Änderung sind ein Widerspruch.
Oft wird, weil ein Kern von geprüfter Software nicht geändert werden soll/darf, Aufwände drumherum gebaut. Diese machen ein
Softwaresystem insgesamt nicht gerade sicherer, weil schwerer durchschaubar.
Solange Software auf verschiedenen Hardwareteilen laufen, ist eine gegenseitige Beeinflussung kontollierbar. Es kann also
sein, dass ein Prozessor sicherheitsrelevante und ungeänderte Software enthält, eine Änderung auf einem anderen Prozessor
die notwendige Gesamtfunktionalität eines Gerätes erweitert, ohne die Sicherheit zu beeinträchtigen. Aber: Wenn ein Prozessor
leistungsfähig genug ist, warum dann die Kosten für 2 Prozessoren mit der entsprechenden Hardware-Umgebung aufwenden?
Damit stellt sich die Frage: Ist es möglich, Software auf dem selben Prozessor teilweise sicherheitsprüfen, andere Softwareteile
aber nicht? Die Frage beantwortet sich mit der Möglichkeit und Auswirkung von Querschlägern aus der nicht sicherheitsgeprüften
Software in die sicherheitsgeprüften Teile. Sollten solche Querschläger die Sicherheit beeinflussen, dann ist die Antwort:
NEIN. Ist es dagegen sicher auszuschließen, dass beliebige Softwarefehler von nicht sicherheitsgeprüften Teilen sicherheitsmindernte
Auswirkungen auf die sicherheitsrelevanten Softwareteile haben, dann: MÖGLICH. Aufgrund des Interesses für Kosten- und Zeitersparnis
und des Interesses zu mehr sicherheitsrelevanten Softwareteilen lohnt es sich, dieser Frage nachzugehen.
6 Praxis-Tips zur Programmierung
Topic:Programming.praxis
Topic:Programming.praxis.debug
Topic:Programming.praxis.test
6.1 Nutzung von Klassen-Variablen oder Stack-lokale Variable und Aufruf-Parameter
Klassenvariable sind notwendig und geeignet, wenn Werte über eine längere Zeit zwischen Aufrufen gespeichert werden müssen.
Man kann Variable, die nur lokal in einer Methode benötigt werden, auch als Klassenvariable anlegen. Bei der Verwendung ist
in C++ und Java kein Unterschied feststellbar, da der Compiler automatisch Klassenvariable erkennt.
Vorteil:
Ein echter Vorteil ist eigentlich nur beim Debuggen eines Gesamtsystems zur Laufzeit gegeben: Hat man geeignete Mittel, gespeicherte
Werte anzuschauen (im einfachten Fall den betreffenden Speicherbereich der Instanz hexa anschauen), dann kann man von außen
beobachten, welcher Wert jeweils als letztes in der Variable stehenbleibt. Ein Wert, der stacklokal angelegt wird, wird einerseits
überschrieben, andererseits ist seine Speicheradresse außen nicht bekannt. Anschauen kann man solche Werte nur, wenn das System
in einem Haltepunkt steht.
Nachteil:
Aus Sicht der nutzenden Methode kann nicht ausgesagt werden, ob die Variable in einer anderen Methode, gegebenenfalls in einem
anderen Thread, beeinflusst wird. Ist die Variable private, dann ist der Einfluss immerhin auf die Klasse reduzierbar. Stacklokal kapselt besser als private-Members. Das ist gut für die Softwarepflege.
Etwas komplexer ist zu bewerten, ob Werte über Aufrufparameter übergeben werden oder in Klassenvariablen gespeichert werden,
um sie in aufgerufenen Methoden benutzen zu können. Hier ist es vom Aufwand des Quelltext-schreibens wesentlich einfacher,
die Werte in Klassenvariable zu speichern. Schnell, einfach, fertig.
Nachteil:
In Betrachtung einer Methode ist es außen nicht sichtbar, welche Variable verwendet werden. Nach dem Paradigma der Objektorientierung
kann eine Methode alle Variable einer Klasse verwenden. Es ist also nichts ausgeschlossen. Sind das sehr viele Variable, dann
geht die Übersicht verloren. Kommen noch gegebenfalls nicht notwendige Klassenvariable dieser Art hinzu, dann sind es noch
mehr.
6.2 Nutzung von Interfaces
Topic:Programming.praxis.using_interfaces
Bezüglich der Interfaces ist es ähnlich wie mit der private-Sichtbarkeit und Zwang zu Zugriffsmethoden: Das stört doch nur
beim schnellen Programmieren. Warum über ein Interface gehen, wenn es direkt auch geht.
Wird ein Algorithmus im Zusammenhang mehrerer Klassen überhaupt erstmal gesucht/gefunden, dann sollte man die Interfaces erstmal
weglassen. In einem zweiten Durchlauf kann man dann sehen, wie die Zugriffe zwischen den Klassen gestaltet werden. Das ist
spätestens dann der Fall, wenn andere Klassenausprägungen als ursprünglich vorgesehen ins Spiel kommen.
Man kann also erstmal drauflosprogrammieren. Danach sind folgende Schritte zur Bildung von Interfaces möglich:
Zunächst eine Grob-Überlegung, welche Assoziationen zwischen Klassen über welche Interfaces überhaupt geführt werden sollen.
Erstellen von leeren Interfaces und Zuordnung zu den implementierenden Klassen:
interface XY
{ //yet empty
}
/*...*/
class AB implements XY
{ public TypeX getSomething()
{ return myTypeX;
....
Schritt für Schritt Umstellung des Typs einer Assoziation (Referenzvariable) vomTyp der klasse auf den Typ des Interfaces.
Es werden damit einige viele Compilerfehler entstehen, da das Interface noch nichts definiert. die Compilerfehler könnten
erstmal angeschaut werden, ob das überhaupt so geht. Zugriffe auf Variable direkt müssen jedenfalls noch umgestellt werden.
XY myRefToAB;
myRefToAB.getSomething(); //compilerfehler
myRefToAB.value; //muss noch umgestellt werden auf Methodenzugriff.
Die Methodenzugriffe, die "nur" einen Compilerfehler bringen, sind schnell in den Griff zu bekommen. Die Methode muss im Interface
definiert werden, dann ist der Compilerfehler und alle adäquaten weg. Dazu die Methode aufsuchen, deren Kopf einfach in das
Interface kopieren, Semikolon dahinter, fertig. Die Methode muss an der Implementationsstelle public sein, was sich ebenfalls schnell noch nachholen lässt.
interface XY
{ TypeX getSomething();
}
Damit werden nach und nach alle Methoden im Interface gesammelt, die benötigt werden. Dieser Schritt dauert nicht lange. Hat
man erstmal 99 bis 999 Compilerfehler, so sind es doch nur 5 bis 20 Methoden, die dies verursachen.
Die bisherige Arbeit war formal erledigbar, also auch deligierbar an jemanden, der nicht Architekt der Software ist. Nun
kommt aber der Schritt der Sichtung des entstandenen Interfaces. Passen die Methoden? Sind es Zugriffe, die eigentlich nicht
so sein sollten? Dann ist ein kleines oder mittleren Refactoring angebracht, Algorithmen verschoben, doch erst Daten in einer
Klasse bereitgestellt, damit die andere Klasse nicht zuviel Details wissen muss. Diese Bereinigung würde Unterbleiben, wenn
keine Interfaces genutzt werden, weil man es gar nicht merkt. In bereinigter Form sind aber die Aufwände für die Weiterentwicklung
der Software gegebenenfalls sehr bedeutsam geringer.
6.3 Praxis: Nutzung der private-Kapselung und Zugriffsmethoden
Topic:Programming.praxis.using_private
Am einfachsten lässt es sich programmieren, wenn alles public ist. Man kann dann direkt zugreifen, hat die wenigste Schreibarbeit.
Deshalb sind Konzepte der Sichtbarkeit auch nicht erleichternd für das schnelle Software-Schreiben, sondern machen sich erst
bei der Softwarepflege bezahlt. Es ist eine durchaus gute Herangehensweise, bei der ersten Programmierung Daten zunächst public zu definieren. Bei der Überarbeitung wird dann einfach private daraus gemacht. Alle danach entstehenden Compilerfehler sind Zugriffe von außen. Das werden nicht allzu viele sein. Man kann
sich dann Gedanken darüber machen, in welcher Beziehung man diese Daten braucht. Gegebenenfalls ist das doch etwas anders und besser als ursprünglich geplant, eine Überarbeitung also sowieso angebracht.
Dann kann man sich überlegen, welche Zugriffsmethoden man braucht. Einfache Zugriffe werden üblicherweise mit set...() und get...() bezeichnet. Die automatische Generierung aller setter und getter für alle Daten, wie es Tools gern anbieten, führt aber dazu, dass ein Nachdenken darüber was eigentlich notwendig ist eingespart
wird. Die Folge kann dann eine nicht so gut strukturierte Software sein.
6.4 Parsix: Suche der Definition eines Elementes bei Interfacenutzung
Normalerweise kommt man in Eclipse relativ schnell zur Definitionsstelle von Elementen. Man braucht nur an der nutzenden Stelle den Kursor zu setzen und <F3>
zu drücken (Menü Naviage - Open declaration). Nutzt man Interfaces, dann kommt man auch an die Stelle der Definition, im Interface.
Das nützt aber meist nicht viel.
Wenn man in der Source navigiert, gilt die gleiche Sicht wie die des Compilers. Die Compilierung soll mit dem Interface von
der Implementierung abstrahieren. Also kann das Navigate auch nur zum Interface führen. Vielleicht ist eine spätere Version
von Eclipse oder eines adäquaten Tools so schlau und sucht doch automatisch die eigentliche Implementierung. Das funktioniert
aber nur, wenn es nur genau eine eindeutige Implementierung gibt. Also im Prinzip nicht, in der Praxis manchmal schon, daher
wünschenswert aber unsicher.
Anders ist es beim Debuggen. Der Schritt-Test geht unweigerlich an die richtige dynamisch gelinkte Implementierung. Jetzt
sind Daten da, damit ist die Sache bestimmbar.
Es ist ärgerlich, wenn das auf Quelltextebene nicht geht. Aber die Aufgabe von Interfaces ist es, Abhängigkeiten zu brechen.
Um die möglichen, und bei wenigen Stellen auch die zutreffende Implementierungsstelle zu finden, kann man aber die Nutzungs-Stellen
des Interfaces suchen (Eclipse: Menü Search - References). Man wird dann die zutreffende Stelle erkennen und dort die Implementierung
finden.
6.5 Praxis:Sicht auf die Daten
Topic:Programming.praxis.debug.viewOfData
So stark das Ansinnen der Kapselung, sprich Verbergung der Daten für die ObjektOrientierte Softwareerstellungsphase auch ist,
beim Test und für das Verstehen der Software sind die Daten das wichtigste. So zeigen Debugwerkzeuge auch grundsätzliche alle
Daten und möglichst viele Zusatzinformationen an, egal ob sie private oder public sind. Das gilt für C/C++-Debugger genauso wie für Java.
Zeige mir deine Daten, und ich erkenne ob du richtig bist - der Slogan des Debuggisten.
In der Eclipse-Umgebung mit Java kann man sich einer Eigenschaft von Java für die Datenanzeige bedienen: Die allgemeingültige
in java.lang.Object definierte Methode String toString(). Eclipse ruft diese Methode für die anzuzeigende Klasse auf und stellt deren Ergebnis dann dar.
6.6 Innere Klassen herauslösen und zu eigenen Klassen machen
Topic:Programming.praxis.InnerClasses
Statische innere Klassen stellen diesbezüglich überhaupt kein Problem dar. Man lege einen neuen Java-Quellfile mit dem gegebenenfalls
etwas modifizierten Namen der vormals inneren Klasse an, und fülle ihn mit dem Inhalt der vormals inneren Klasse. In Eclipse
ist das Anlegen eines Klassenfiles.java mit der Menübedienung File - New - Other - Class erledigt. Die bisherige innere Klasse wird einfach gelöscht. Nachfolgende Compilierungen zeigen dann an, wo der als Präfix
geschriebene Name der vormals umgebenden Klasse zuviel ist. Einfach Fehler beseitigen durch weglöschen. Nebeneffekte wird
es nicht geben.
Eine nicht statische innere Klasse
6.7 Mehrfacher Test
Topic:Programming.praxis.test.multiTest
Komplexe Algorithmen, die nicht nur für einen begrenzten Zweck geschrieben wurden, sollten unter verschiedenen Blickwinkeln
und in verschiedenen Anwendungsumgebungen getestet werden:
Algorithmischer Test in einer vom Entwickler geschriebenen Testumgebung mit Beispieldaten: Dieser Test dient insbesondere
dem Entwickler zum debuggen und detaillierten Untersuchen von Grenzbedingungen.
Einsatz des Moduls in einer Umgebung, Praxistest, gegebenenfalls Entwicklertest mit Debugging: Hier könnte es sich herausstellen,
dass die erwarteten Einsatzbedingungen anders sind als der Entwickler sich gedacht hatte. Auch Spezifikationen können mehrdeutig
interpretiert werden.
Einsatz des Moduls in einer anderen Umgebung: Hier gibt es wieder andere Stimulis. Wenn ein Modul in verschiedenen Umgebungen
laufen soll, muss es im Test auch ohne Rücksicht auf die Entwickler-Spezifikation eingesetzt werden. Nur damit erweist sich
eine Praxistauglichkeit. Eine Anwender-Spezifikation kann damit verifiziert werden.
Aufbau einer Testumgebung, die alle bisherigen Erfahrungen und die Anwendungsspezifikation berücksichtigt.
Die Testumgebung ist der vorletzte Schritt der Entwicklung. Dieser Schritt kann nicht vom Entwicklungsteam allein realisiert
werden. Diese Testumgebung zusammen mit der Anwendungsspezifikation ist nun auch juristisch wichtig; hier wird festgestellt
unter welchen Bedingungen das Modul offiziell getestet wurde, welche Funktionalitäten garantiert werden und welche Einschränkungen
es gibt.
 Bild: Test eines Moduls mit Schnittstelle zu einem horizontalen Modulen
Bild: Test eines Moduls mit Schnittstelle zu einem horizontalen Modulen