1. Excecption handling
In C++ (and Java, C# etc) languages the concept of try-catch-throw is established (''Exception handling''). This is a some more better concept than testing return values of each calling routine or testing errno like it is usual in C. The advantage of try-catch-throw is: Focus on the intrinsically algorithmus. Only in that source where an error may be expected and should be tested for safety operation, the conditions should be tested and a throw should be invoked if the algorithmus does not mastered the situation. And, on the opposite side, in sources where any error in any deeper level may be expected and it is able to handle, a try and catch is proper to write. All levels between try and throw do not regard any exception handling, they are simple. This is the '''advantage in comparison to the ''error return'' concept''' whereby any level of operation need to test the error return value.
The necessity of handling error return values in C will be often staggered to a later time, because the core algorithm should be fistly programmed and tested. Then, in later time, the consideration of all possible error situations is too much effort to program, it won’t be done considering the time line for development …
Therefore the try-catch-throw concept is helpfull.
2. Never execute faulty instructions, test input arguments
@date=2019-04
In the following example a routine gets an arrayIndex. The software may be well tested, the arrayIndex has a valid value anytime, so the desire of developer. Nevertheless it should be tested! The test may only be omitted, it the calculation time is very expensive in this case and the routine is defined as static or private in C++. The static definition ensures that only a call in the same source is possible (or included sources, pay attention).
//called level:
int excutesub(..., uint arrayIndex, ...) {
if(arrayIndex >= sizeArray) {
THROW(IndexOutOfBoundsException, "illegal index", arrayIndex, -1);
arrayIndex = sizeArray -1;
faultyData = true;
}
myArray[arrayIndex] = ... //access only with correct index!
The THROW statement either invokes throw of C++, longjmp or write a log entry.
In a developer test phase C++ throw should be available while testing the system on a PC platform. Hence the error in runtime is detected, messaged and fixed. For a cheap target system, C++ may not be available or to expensive and longjmp does not work, there is no sensible possibility for error handling. Such an error may be really unexpected, but it is not possible to exclude.
For this case a 'avoidance strategy' is used: The THROW writes only a centralized information for example only one error store, or in a short buffer, and continue. The faulty value is set to a valid value for the safety of working of the system (not a valid value for the correct functionality, it is not possible). The system runs furthermore. The data may be designated as faulty. The system should run furthermore (it should not reset or such), because other functionality may be work proper and should be work, and a data access for debugging is possible. The error message from THROW can be detected in a maintenance phase.
3. Alternative: Assertion
@date=2021-12-02
If the calculation time is very expensive, it is so only in the target and only if it runs with full capability. In the developer phase or in tests there may be a little more time to spend for assertion:
//called level:
int excutesub(..., uint arrayIndex, ...) {
ASSERT_emC(arrayIndex < sizeArray, "faulty index", arrayIndex, sizeArray);
myArray[arrayIndex] = ... //access only with correct index in test situations!
In elaborately tests the ASSERT_emC() macro checks the input condition and throws an exception with the given information if it is faulty. Hence the algorithm have a correct arrayIndex anyway.
If the algorithm should run with full speed in a target, it should be elaborately tested before. Hence it is really able to expect that the arrayIndex is correct. Now it is used without test (because it would need time). The ASSERT_emC(…) macro is defined as empty in this compilation situation.
But the source is unchanged. With the given source the test can be repeated anytime, to check a fault etc.
But the assertion can also be active in a target software. Then it forces a THROW which can be catched.
The third possibility: The ASSERT_emC(…) macro can start with a global check of a boolean variable for run-time-activation. If that is switched off the assertion does only need the time to check this activation. It does not need time for the other arguments (because it is a macro, it does not use it in that time). It need only program memory. The advantage: All assertions of one module can be switched on in productive software on target for maintenance of a obscure situation. Hence it can be checked which is faulty.
An ASSERT_TEST_emC(…) is only provided for tests, and for documentation that it is not expected.
It should only be used for non able to expect situations. It is activated only if
#define ASSERT_Test_emC
is set for specific cases or in the applstdef_emC.h
4. Debugging on runtime
The old approach is: ''Debug any algorithm till it is error-free''. That approach cannot be satisfied if the algorithms are complex, the error causing situations are variegated and the time to test is limited.
A better approach may be: ''Run the system under all possible situations''. It is not possible to debug step by step in all such situations.
Therefore the ''debugging on runtime'' is the proper approach:
-
Log all error occurences, but don’t abort.
-
Log the situation additionally.
-
Have enoug information to elaborate the situation and reason afterwards.
-
Access to the internal states of the target where the software runs to explore the state of the target.
5. An embedded system should run if it can
If a PC application crashs, it can show an error message, or a blue screen, the operator does see it, restarts the application or reboot the PC. It is not expected, but it is though okay.
But an embedded system has not a permanent present operator. It should run.
If the embedded system is in test, and it can not startup because any reason, or it has an non self-managable problem, it should show its state with an obviously message. That can be a blinking red led, a binary signal or such. With the second one an emergency replacement action can be done.
It is important that an operator can read out the error reason. It means a minimal communication should be possible. The most minimal communication is a blinking sequence of the red led.
An embedded system should be execute a hard reset automatically (often a watchdog mechanism is present). But if this fails repeatedly, the hard reset should be suspended to explore the error situation manually by maintenance operation.
There are two routines which should stop execution for an embedded system in the emC strategy:
/**Stops the execution of the executable respectively the whole application * because no error handling is possible. * This routine should only called in unexpected situations, * where the engine may only be stopped. * * This routine is used in the OSAL- or OS-Layer itself only for errors, * which are fatal and not expectable. * This routine should be used from the users layer in adequate fatal situations. * The OSAL or OS doesn't call this routine in situations of errors * which are able to catch. * * The implementation of this routine should be done depending from the users * requirements or special test requirements * to the whole system. It should be hard coded and really stop the execution. */ extern_C void os_FatalSysError(int errorCode, const char* description , int value1, int value2);
/**Stops the execution of a thread because no error handling is possible. * This routine should only called in unexpected situations, * where the thread may only be stopped.. * The distiction to ,,os_FatalSysError(...),, is: Only the calling thread is stopped, * where the other threads maybe continued still. * It may be possible, that the system is instable, but other threads may able to use * to debug this situation. The application may be wrong.. * * This routine is used in the OSAL- or OS-Layer itself only for errors, * which are fatal and not expectable. * This routine should be used from the users layer in adequate fatal situations. * The OSAL or OS doesn't call this routine in situations of errors * which are able to catch. * * The implementation of this routine should be done depending from the users * requirements or special test requirements * to the whole system. It should be hard coded and really stop the execution. */ extern_C void os_FatalError(int errorCode, const char* description , int value1, int value2);
There is a routine
void uncatched_ExceptionJc ( ExceptionJc* ythis, ThreadContext_emC_s* _thCxt)
{
printf("uncatchedException: %4.4X - thread stopped", (uint)ythis->exceptionNr);
printStackTraceFile_ExceptionJc(ythis, null, null);
os_FatalError(-1, "uncatchedException: - thread stopped", (uint)ythis->exceptionNr, 0);
exit(255);
}
which invokes this os_FatalError(…). It is called if no CATCH level exists.
6. Three possibilities of THROW in emC, C++-throw, longjmp and message
@date=2019-04
The emC programming style knows three levels of using TRY-CATCH-THROW using macros. The user sources itself are not need to adapt for this levels. The macros are adapted. See Implementation.
-
Using try-catch-throw of the C++ language. On PC or some other platforms it can handle so named asynchron exceptions (faulty memory access) too. It is able to use especially on test of the application on PC, but for rich target systems too. From C++ only the simple
throwandcatch(…)is used. The sophisticated C++ exception possibilities are not used and not recommended. Keep it simple. But: The C++throwtakes a lot of computing time, for fast algorithm in embedded targets not able to use. Hence see next: -
The try-catch-throw concept is also possible to do using the longjmp concept. That is known in C since 1970, but it was not published often for that. Some comments and using notes to the
setjmp.hare confused. A description may be found in pubs.opengroup.org/…/longjmp.html. The longjmp is often referred to as 'non local goto' and therefore marked as 'goto' programming style. But that is false, better to say 'bullshit'. The longjmp is a well structured restauration of a stackframe from a previous call back to the call. The stack frame of the caller level is being restored exactly. Only for some special conditions the official publications write about 'the behavior is undefined'. Any compiler should support longjmp. It is defined in the C99-Standard: www.open-std.org/jtc1/sc22/wg14/www/docs/n1256.pdf C99-Standard, chapter 7.13.
There were found some compiler for special processors that do not support longjmp. For that the longjmp concept unfortunately is not able to use. For that:
-
Messaging and avoidance strategy: If a program is well tested there is a residual risk that the program executes a
THROW. The THROW only writes a error message, and the algorithm is continued. The algorithm should contain statements to set the safety for running the system. Data can be faulty. See example in the chaper above.
In C++ yet tested with MS Visual Studio and Texas Instruments CCP longjmp runs, it is faster than throw, but it does not invoke the destructors:
In C++ language the way from throw to catch invokes all destructors of data of all calling levels. That’s important if destructors are used to close resources. In C the destructor concept is not known. Therefore or in a C-style-oriented C++ programming (without new, often recommended for embedded) using longjmp is not a problem. In comparison, Java language doesn’t know the destructor concept too. Instead, a finally is defined there to close resources on throw. This finally concept is established in emC exception handling too, independent of the destructor problematic. Hence destructors which closes resources are not necessary in embedded programming using finally. It may be the better or a proper way. See next chapter, the pattern.
Generally the THROW can use FILE and LINE in the message to mark the occurrence in source.
The CATCH can contain a stacktrace report from TRY to the `THROW`ing routine. The stacktrace is known from Java, it is a proper instrument for searching the cause.
7. Pattern to write TRY-CATCH-THROW for portable programming
Sources should be tested well on a PC platform where try-catch-throw of C++ is available. Then, without changes, they should run on a target platform where a C-compiler does not have this feature or less footprint is available, and the sources are tested well on the other hand.
7.1. The pattern
to write sources for that approach is the following one:
void anyOperation() {
STACKTRC_ENTRY("anyOperation");
float result;
TRY {
//an algorithm which expects errors on calling level
result = anyOperation();
}_TRY
CATCH(Exception, exc) {
printStackTrace_ExceptionJc(exc, _thCxt);
log_ExceptionJc(exc, __FILE__, __LINE__);
//alternate handling on error to continue the operation
result = 0.0f;
}
FINALLY {
//handling anytime, also if the execption is not catched.
}
END_TRY //throws an uncatched execption to a higher level.
//continue outside try
STACKTRC_LEAVE;
}
float anyOperation() {
STACKTRC_ENTRY("testThrow");
//...
CALLINE; throwingOperation(_thCxt);
STACKTRC_LEAVE; return val;
}
void throwingOperation(ThCxt* _thCxt) {
STACKTRC_TENTRY("testThrow");
//any algorithm which
if(ix >= ARRAYLEN_emC(thiz->array)) { //checks conditions
THROW_s0(IndexOutOfBoundsException, "msg", ix, 0);
ix = 0; //replacement strategy
}
STACKTRC_LEAVE
}
-
All or the most operations should use
STACKTRCE_ENTRY("name")andSTACKTRC_LEAVE. With this the ''Stacktrace'' is stored and available for the error report outside of the step-by-step debugger. Operations should not implement this, it is ok, then the Stacktrace is not stored but the system runs nevertheless. TheSTACKTRC…macro is nearly empty if the compiler switchDEF_ThreadContext_SIMPLEis set, then no Stacktrance for error report is available, but it does not need additional calculation time. -
The difference to
STACKTRC_TENTRY(…): This macro expects the_thCxtreference as argument. It is the reference to theThreadContext_emC_sdata structure. InsteadSTACKTRC_LEAVEalsoSTACKTRC_RETURNis able to use which contains thereturnstatement. -
Macros
TRY{ … }_TRY CATCH(…){ } END_TRYare used for build the blocks. This macros are defined in different ways for the appropriate situations. See below. -
The macro
THROWeither throws the exception to continue execution in theCATCHblock of any calling level, or it logs only the situation (because try-catch-throw is not available). The replacement strategy after THROW is not used if the try-catch-throw mechanism is available. Then it throws really. But for a simple execution with a C compiler the replacement strategy is the fall-back. -
The
CATCHblock is only valid if ''try-catch-throw'' is available. It may be only on PC test, not on target, Then some test outputs can be programmed there, with the fall-back on this level. -
The
CALLINEmacro stores the number of that line in the stacktrace entry.
There are some situations:
-
Test on PC with using
CATCH. It helps for elaborately tests to exclude error situations caused from programming errors. -
Running on target with using
CATCH(C++ compiler available or usinglongjmp). TheCATCHblock may log errors, does not print a Stacktrace, but continue the execution. -
Test on PC without
CATCHwithout Exception handling, as end-test. -
Running on target without
CATCHwith the fallback strategy afterTHROW.
The following ideas are basically:
-
The software should be tested as soon as possible. It isn’t able to exclude all software errors.
-
For the residual probability of software errors the target should be run as soon as possible. It means on unexpected errors proper fall-back have to be existent. A ready-to-use software must not stop working and reporting and error if it is possible that it can run furthermore with less disadvantages.
-
Errors on ready-to-use software should be logged internally to detect and fixed it later, if possible.
-
The
TRY-CATCH-THROWapproach should not be used for expected errors (for example 'file not found'). Such situations should be catched by proper return values of functions.
7.2. The resource problematic, using FINALLY, nested TRY-CATCH
If a operation opens a resource, which should be closed anyway also in case of an exception, FINALLY can be used:
FILE* openfile = null;
TRY {
openfile = fopen(...);
//do somewhat may throw
}_TRY
FINALLY {
if(openfile) { fclose(openfile); }
}
END_TRY
This level does not handle an exception, it has not a CATCH block. An exception is forwarded to a TRY block before. But the FINALLY block is executed.
It may be seen as a better (obviously) concept to use FINALLY (as in Java) instead writing open and close in special constructors or destructors. Such resource things in embedded algorithm are not often present. It is not a high effort to do so.
In generally, TRY - END_TRY blocks are able to nesting. A non handled exception type is forwareded to the block before, the necessary further throw or longjmp is executed in the END_TRY macro. See link#impl[chapter How does it works]
7.3. Controlling the behavior which strategy of exception handling is used
It depends on the applstdef_emC.h header file which should used in any source of the application. This file defines:
//If set then the target should not use string operations //#define DEF_NO_StringJcCapabilities
//If set, without complex thread context, without Stacktrace #define DEF_ThreadContext_SIMPLE
//#define DEF_Exception_TRYCpp #define DEF_Exception_longjmp //#define DEF_Exception_NO
With the first compiler switch it is decided generally using Strings in the application. For a poor target platform with numerical approach String capabilities are not necessary, this compiler switch prevents the compilation of some String capabilities. It saves program memory and dependencies to further sources. "string literals" for simple messages are admissible.
The second compiler switch decides between using the Stacktrace ('not simple') or not.
One of the third compiler switches should be set, but DEF_Exception_longjmp is the default one.
The header files, especially emC/Base/Exception_emC.h regard this swichtches, see chapter How does it works.
7.4. Assembly an error message
The minimal requirement to a logged error is:
-
An error number
-
Two integer values from the error situation (for example the value of a faulty index and its maximum)
-
The source file and the line number of the THROW statement. The last one helps to detect the source context of the error event.
A textual value may be a nice to have and maybe an effort on small footprint (poor) processors. Therefore it is possible to write such source code fragments in conditionally compiling parts. On the other hand it is a important hint on debugging on runtime (not step by step).
All variants of exception behavior supports an error message which is located in the stack of the throwing level.
-
If the
log_ExceptionJc(…)is used, the text is copied from the stack location to static locations of the error log area, or maybe copied to a telegram which is sent via communication to another unit with a file system. -
If TRY-CATCH is used, the error message is copied to the ThreadContext area, if it is available for this approach. In the
END_TRYblock this location is freed. It means, the exception message is correct stored in the CATCH environment. If thelog_ExceptionJc(…)is used in the CATCH-Block, it is copied too, and the ThreadContext heap is able to free.
Example:
if(faulty) {
#ifdef DEF_NO_StringJcCapabilities
char const* msg = "faulty Index";
#else
char msg[40] = {0};
snprintf(msg, sizeof(msg), "faulty index:%d for value %f", ix, val);
#endif
THROW_s0(IndexOutOfBoundsException, msg, ix, 40);
The exception message is prepared using sprintf in the stack area. But a simple string literal is used instead if the target does not or should not support string processing. Hence the message is only available for the test platform. The THROW_s0 assures that the msg is copied in a safely memory if msg is a reference in the current stack frame but only for not set DEF_NO_StringJcCapabilities.
8. Array index faulties, IndexOutOfBoundsException
The simple usage of arrays in C (and in C++) is very simple and vulnerable:
int myArray[5]; // *(myArray + ix) = value; //<== bad pattern
That was the intension of C comming from assembler language thinking.
myArray is an address in a register or variable, and the access to elements
should be able to write very simple here with a pointer arithmetic. In the time of the
1970th, programming was done on paper with reliability. Of course the ix should in range
0 to 4. The pointer arithmetic in the writing style above was conceptional in that time,
the arithmetic was reproducible as machine level instructions.
At the present time the same instructions should be write of course as
myArray[ix] = value;
That is more expressive in source code. The identifier myArray
is similar a pointer type int* and an array indentifier.
That is a syntactically disadvantage to C and C++.
In other languages as Java myArray is never a pointer, it is only an identifier to an array.
For simple C and C++ the index is not tested, it is used as given.
If ix is <0 or >4 in this example, faulty memory locations can be disturbed.
It can be other data, a stack frame to return from a subroutine, control data of
heap locations, or a virtual pointer in class instances. All of that may force
difficult findable mistakes. The array indexed write access and some pointer arithmetics
are the most sensitive parts of a program which may provoke faulties.
For example in Java pointer arithmetic is not possible and array index accesses are always secured. Whereby the effort to do that is optimized. The JIT (just in time compiler) to translate bytecode to machine code detects environment conditions and will not check all array indices if they are safe, for example comming from constant values. Hence Java is fast and safe.
In comparison to C++ there is an effort in user programming (which is done automatically by the JIT compiler in Java): Indices should be tested before doing array write access. This test can be done via static code analyzes, or in Runtime.
The C++11-standard offers a possibility:
#include <array> //... std::array<float,5> myArray; //... myArray[ix] = value;
It seems be similar as in C, only the array definition is a little bit modified, using a template mechanism in C++. The access to the array is safe. But a faulty index does not throw an catchable exception. Hence the error is not detected while testing. The other disadvantage is: Some embedded platforms does not support C++11 in the year 2020. A reason for that may be: Most of new features of C++ are for PC application programming, not for embedded. Ask the compiler developer for embedded platforms.
The proper mechanism does not presumed a C++11-Standard. It runs in a Standard C++ of the 1990th too:
template<typename T, int n>
class Array_emC {
T array[n+1];
public: T& operator[](uint ix) {
if(ix < n) return array[ix];
else {
THROW_s0n(ArrayIndexOutOfBoundsException, "", ix, n);
return array[n];
}
}
public: T& uncheckedAccess(uint ix) { return array[ix]; }
};
This is a class which implements a secured array access. it is used as:
Array_emC<float, 5> array; //... array[ix] = value;
It is similar as in C++11 but it is able to use on all platforms with C++ compilation. And it throws an Exception if it is activated, respectively it writes to an replacement location without disturbing data, if exception handling is not present.
array.uncheckedAccess(0) = 234;
This is the fast and unchecked variant which should only be used if the index range is known.
This Array_emC class is defined in <emC/Base/Array_emC.h> and can be used for
C compilation too, than without check, for well tested simple C deployments,
which are tested with C++ compilation on PC platform. It uses macros for compatible
usage in C and C++ and offers a class with variable array size, for dynamic data.
For C++ compilation the variant without Exception writes to a safety position. The C variant does not check the index, it is only for well tested software.
See source <emC/Base/Array_emC.h>.
9. STACKTRC and Thread context
The ''Stacktrace'' can be used for ''Exception Handling''. If an exception occurs, the information which routine causes it, and from which it was called is an important information to search the reason. This stacktrace mechanism is well known in Java language:
Error script file not found: test\TestCalculatorExpr.jzTc at org.vishia.jztxtcmd.JZtxtcmd.execute(JZtxtcmd.java:543) at org.vishia.jztxtcmd.JZtxtcmd.smain(JZtxtcmd.java:340) at org.vishia.jztxtcmd.JZtxtcmd.main(JZtxtcmd.java:282)
The Stacktrace information may be the most important hint if an error occurs on usage, not in test with debugger. For C language and the ''emC Exception handling'' this concept is available too:
IndexOutOfBoundsException: faulty index:10 for value 2.000000: 10=0x0000000A at testThrow (src\TestNumericSimple.c:121) at testTryLevel2 (src\TestNumericSimple.c:107) at testTry (src\TestNumericSimple.c:86) at main (src\TestNumericSimple.c:38)
In generally the necessary information about the stack trace can be stored in the stack itself. The entries are located in the current stack level, and the entries are linked backward with a reference to the parent stacklevel. But that concept has some disadvantages:
-
It requires an additional argument for each operation (C-function): The pointer to the previous stack entry. It means, all routines from the user’s sources should be subordinated to that concept. They should be changed. That is not the concept of emC style, which is: ''It shouldn’t be necessary to change sources.''
-
If the stack itself is corrupt because any failure in software, the stacktrace cannot be back traced, because the references between the stacktrace entries may be corrupt too. This is hardly in debugging too.
-
The linked queue of stacktrace entries should be correct. If a STACKTRC_LEAVE operation was forgotten to write in the software, an entrie in a no more existing stack area remain in the queue. That is corrupt. The system is too sensitive.
-
The linked queue can only be traced from knowledge off the current stack area. It cannot traced from another thread maybe by a debug access on the stopped execution of the thread. The last one may be necessary for some error situation for debugging.
Therefore the Stacktrace is organized in an extra independent memory area which is static or static after allocation on startup. Its address can be known system wide especially for debugging. This memory is referenced by the ThreadContext memory area which is thread specific and therewith tread safe. See chapter Content of the ThreadContext_emC
9.1. Organizing the ThreadContext memory
If an operation uses
void myOperation(...) {
STACKTRC_ENTRY("myOperation");
....
which is necessary for the usage of the ''Stacktrace'' concept respectively for a Stacktrace entry of this routine, a local variable
struct ThreadContext_emC_t* _thCxt = getCurrent_ThreadContext_emC();
is defined and initialized with the pointer to the current ThreadContext. Adequate, an operation can have an argument
void myOperation(..., ThCxt* _thCxt) {
STACKTRC_TENTRY("myOperation");
....
The ThCxt is a short form of struct ThreadContext_emC_t per #define. This second form STACKTRC_TENTRY(…) needs this special argument to the subroutine, but the ThreadContext reference is given immediately.
How the STACKTRC_ENTRY macro gets the ThreadContext reference. In emC/Exception_emC.h is defined:
#define STACKTRC_ENTRY(NAME) \ ThCxt* _thCxt = getCurrent_ThreadContext_emC(); STACKTRC_TENTRY(NAME)
The implementation of getCurrent_ThreadContext_emC() depends on the OSAL implementation (Operation System Adaption Layer)
for the application and the operation system:
-
For a multithread operation system on large hardware ressources, especially for Windows/Linux the
ThreadContext_emCis a part of the OSAL-ThreadContext which is necessary to organize the threads on OSAL level. Therefore thegetCurrent_ThreadContext_emC()is implemented in the appropriateos_thread.c. -
If especially a System with a simple CPU hasn’t a multithread operation system a very simple and fast implementation is possible, see
emC_srcApplSpec/SimpleNumCNoExc/ThreadContextInterrTpl.c.-
Any hardware interrupt (which do the work) has a static data area for its 'thread context'.
-
The main loop has its own 'thread context'.
-
There is one global static singleton pointer to the current used
ThreadContext_emC*, which can be accessed immediately, one machine operation. -
Because the interrupts are not preemptive one another, only a higher priority interrupt can interrupt a lower one and the main loop, the following mechanism set the global static singleton
ThreadContext_emC*pointer: -
on start of any interrupt the current pointer value is stored in the interrupt itself stack locally and the
ThreadContext_emCaddress of that interrupt is set instead. -
on end of the interrupt the stored value of the interrupted level is restored. That is one machine instruction (or two, if the pointer is not stored in a register).
-
It is a cheap and fast mechanism to support the ThreadContext_emC concept.
/**Structure for ThreadContexts for Main and 2 Interrupts. */
typedef struct ThCxt_Application_t {
/**The pointer to the current ThreadContext. */
ThreadContext_emC_s* currThCxt;
ThreadContext_emC_s thCxtMain;
ThreadContext_emC_s thCxtIntr1;
ThreadContext_emC_s thCxtIntr2;
}ThCxt_Application_s;
/** public static definition*/
ThCxt_Application_s thCxtAppl_g = { &thCxtAppl_g.thCxtMain, { 0 }, { 0 }, { 0 } };
/**A template how to use. */
void interrupt_handler(...) {
ThreadContext_emC_s* thCxtRestore = thCxtAppl_g.currThCxt;
thCxtAppl_g.currThCxt = &thCxtAppl_g.thCxtIntr1;
TRY {
//the statements of the Interrupt
}_TRY
CATCH(Exception, exc) {
//should log the exception or set safety values.
} END_TRY
thCxtAppl_g.currThCxt = thCxtRestore;
//end of interrupt
}
Because the interrupt saves the current pointer and restores it, the mechanism is safe also if the other interrupt routine interrupts exact between the 2 statements, get current and set new one. In such a system the exception handling can be established in the interrupt too, it is useful if the algorithm in the interrupt may have throwing necessities.
For such a system the routine
ThreadContext_emC_s* getCurrent_ThreadContext_emC ()
{
return thCxtAppl_g.currThCxt;
}
is very simple. The ThreadContext is always the current one stored in the global cell.
9.2. Content of the ThreadContext_emC
For the content of the OS_ThreadContext to manage threads see the OSAL-specific implementation of os_thread.c. This chapter only describes the ThreadContext for the user’s level.
The following definition is from emc/source/emC/ThreadContext_emC.h. The Headerfile contains comments of course, they are shorten here for a short overview:
typedef struct ThreadContext_emC_t {
#ifdef DEF_ThreadContextHeap_emC
UserBufferInThCxt_s threadheap;
#endif
#ifdef USE_BlockHeap_emC /**It is the heap, where block heap allocations are provided in this thread. */ struct BlockHeap_emC_T* blockHeap; #endif
/**The known highest address in the stack. * It is the address of the _struct ThreadContext_emC_t* pointer * of the first routine, which creates the Thread context. */ MemUnit* topmemAddrOfStack;
/**This is the maximal found value of the stack size which is * evaluated on [[getCurrentStackDepth_ThreadContext_emC(...)]] . */ int stacksizeMax;
/**Number of and index to the current exception instance*/ int zException, ixException; // /**Up to NROF_ExceptionObjects (default 4) for nested Exception. */ ExceptionJc exception[4];
/**Reference to the current TryObject in Stack. * It is possible to access in deeper stack frames. * This reference is removed for the outer stack frames. */ TryObjectJc* tryObject;
#ifdef DEF_ThreadContextStracktrc_emC /**Data of the Stacktrace if this concept is used. */ StacktraceThreadContext_emC_s stacktrc; /*IMPORTANT NOTE: The element stacktrc have to be the last * because some additional StackEntryJc may be added on end.*/ #endif
} ThreadContext_emC_s;
The first element is for the threadlocal heap. See next chapter Threadlocal heap. It is a simple concept only for shortly stored informations.
The BlockHeap is another Mechanism for safe non-fragmented dynamic memory, especially for events. See [TODO]. It is possible to associate such an BlockHead thread-specific.
The data for the StacktraceThreadContext are the last one. Because it is an embedded struct and the definition is static, the number of elements for the Stacktrace can be changed for larger applications by offering a larger memory area. To assert and check that, the pointer to the ThreadContext_emC_s is combined with the size in a MemC struct, see [TODO]. It will be faulty to calculate the sizeof(ThreadContext_emC_s) if there are more elements. The Stacktrace is defined as:
/**This structure is the last part of the ThreadContext
* and contains the necessary values for handling with Stacktrace.
*/
typedef struct StacktraceThreadContext_emC_t
{
/**actual nrofEntries in stacktraceBuffer. */
uint zEntries;
//
/**The available number of Stacktrace entries. */
uint maxNrofEntriesStacktraceBuffer;
//
/**This mask is used for safety operation
* if the indices in IxStacktrace_emC are corrupt.
* This can occure especially in errorneous situations on software development.
* It simply helps to prevent faulty array accesses.
* But this mask information should be safe by itself or cyclically checkec
*/
uint mBitEntriesStacktrc;
//
/**Space for Stacktrace Buffer. Should be the last element because of enhancements*/
StacktraceElement_emC_s entries[128];
} StacktraceThreadContext_emC_s;
A Stacktrace element is defined as:
typedef struct StacktraceElement_emC_T
{
const char* name;
const char* source;
int line;
} StacktraceElement_emC_s;
9.3. What is happen on the first STACKTRACE_ENTRY("main")
@ident=mainOsInit
The first entry should be written as
STACKTRC_ROOT_ENTRY("main");
but that is not the important one. The ROOT_ forces only:
#define STACKTRC_ROOT_ENTRY(NAME) \ STACKTRC_ENTRY(NAME); _thCxt->topmemAddrOfStack = (MemUnit*)&_thCxt
to evaluate the stack deepness. The more important difference is the invocation of getCurrent_ThreadContext_emC():
#define STACKTRC_ENTRY(NAME) \ ThCxt* _thCxt = getCurrent_ThreadContext_emC(); STACKTRC_TENTRY(NAME)
For a System with a OSAL layer for adaption of a multithread operation system, there is nothing done for the ThreadContext before start of main(). The first invocation of getCurrent_ThreadContext_emC() (see chapter Thread context) determines that all is uninitialized (code snippet from emc/sourceSpecials/osal_Windows32/os_thread.c:
ThreadContext_emC_s* getCurrent_ThreadContext_emC ()
{
OS_ThreadContext* os_thCxt = getCurrent_OS_ThreadContext();
if(os_thCxt == null){ //only on startup in main without multithreading
init_OSAL(); //only 1 cause if the ThreadContext haven't set.
os_thCxt = getCurrent_OS_ThreadContext(); //repeat it
if (os_thCxt == null) {
os_FatalSysError(-1, "init_OSAL failed, no ThreadConect", 0,0);
return null;
}
}
return &os_thCxt->userThreadContext; //it is a embedded struct inside the whole ThreadContext.
}
Of course the getCurrent_OS_ThreadContext() returns null (it invokes here TlsGetValue(1) from the Windows-API). bOSALInitialized == false too, therefore firstly the OSAL will be initalized. That may be a more complex routine, with some API- and/or Operation System invocations for some Mutex etc.
The advantage to do that on start of main is: A debugging starts at main usually. Another possibility may be: initializing of the OSAL level with a initializer on a static variable.
10. A threadlocal heap for short used dynamic memory especially for String preparation
@ident=thrHeap
This is only a indirect topic of Exception handling, but often Strings should be assembled with several informations for logging or for exception messages.
Dynamic memory is a basicly problem for embedded long running systems:
-
If dynamic memory is managed from an ordinary heap concept (like in standard-C/C++, using malloc or new), then for long-running applications there is a fragmentation problem. Therefore often for such applications usage of dynamic memory is prohibited.
-
But dynamic memory is nice to have often for a short time to prepare string messages for example for communication telegrams, for logging, or for events.
Without dynamic memory and without the ThreadContext_emC there are two ways to solve such problems:
-
a) Provide a static memory. It can be a part of the instance data of a module (defined in a
structor C++-class), or pure static. The last one may cause faulties if the module is instanciated more as one time, used in a multithreading system, but has only one static memory for such things://strongly not recommended: const char* myLogPreparer(...) { //prepares and returns a log message static char buffer[100]; //it is static snprintf(buffer, 100, ... //prepare return buffer; //that is ok, because it is static.
*+ It is not recommended because this module may be used more as one time and confuses with the only singleton memory.
//more practice, possible:
typedef struct MyData_t {
char buffer[100]; //one per instance! That's the advantage.
... }
void myLogPreparer(Mydata* thiz,...) {
snprintf(thiz->buffer, sizeof(thiz->buffer),...
-
b) Provide the memory for preparation in the Stack area:
void logger(...) { char buffer[100]; //in stack! myLogPreparer(buffer, sizeof(buffer), ...); //deliver the stack local pointer. ....void myLogPreparer(char* buffer, int zBuffer, ...) { snprintf(buffer, zBuffer, ...);
*+ The danger of that programming is: The called routine could store the pointer persistently, that is a stupid failure.
Another disadvantage for both approaches are: The length of the buffer is dedicated out of the routine, which determines the content. That causes unflexibility.
Using dynamic memory it is more simple:
char const* myLogPreparer(...) { //prepares and returns a log message
char* buffer = (char*)malloc(mySize); //it is static
snprintf(buffer, mySize, ... //prepare
return buffer; //that is ok, because it is allocated.
The calling level should know that the returned pointer should be freed!
But - The usage of dynamic memory may be prohibited.
The ThreadContext provides a mechanism for dynamic memory only for shortly usage and small sizes which solves that problem:
char const* myLogPreparer(...) { //prepares and returns a log message
STACKTRC_ENTRY("myLogPreparer"); //_thCxt is available
MemC memb = getUserBuffer_ThreadContext_emC(mySize, "identString", _thCxt);
char* buffer = PTR_MemC(memb, char);
snprintf(buffer, mySize, ... //prepare
STACKTRC_RETURN buffer; //that is ok, because it is non in stack.
}
The calling routine should invoke:
char const* msg = myLogPreparer(...args for logging...) free_MemC(msg);
The free_MemC(…) routine checks where the memory is allocated. It frees it correctly for the ThreadContext heap. The freeing should be done immediately in the thread.
If more as one buffer are used from ThreadContext, but all of them are freed in the reverse (or another) order, after freeing the whole ThreadContext heaap is free and therefore not fragmented. The ThreadContext heap is only intended for short-term use.
11. How does it works - Different implementation of the TRY-CATCH-THROW macros
The macros are defined for all variants as follow (see 'emC/Base/Exception_emC.h':
#define TRY \
{if(_thCxt == null) { _thCxt = getCurrent_ThreadContext_emC(); } \
TryObjectJc tryObject = {0}; \
TryObjectJc* tryObjectPrev = _thCxt->tryObject; _thCxt->tryObject = &tryObject; \
int32 excNrCatchTest = 0; \
CALLINE; \
Exception_TRY
/**Written on end of a TRY-Block the followed macro: */
#define _TRY \
Exception_CATCH { \
_thCxt->tryObject = tryObjectPrev; \
if(_thCxt->exception[0].exceptionNr == 0) {/*system Exception:*/ \
_thCxt->exception[0].exceptionNr = ident_SystemExceptionJc; \
_thCxt->exception[0].exceptionMsg = z_StringJc("System exception"); \
} \
excNrCatchTest = _thCxt->exception[0].exceptionNr; \
if(false) { /*opens an empty block, closed on first CATCH starts with }*/
//end of CATCH before: remove _ixStacktrace_ entries of the deeper levels.
//Note: Till end of catch the stacktrace of the throw level is visible.
#define CATCH(EXCEPTION, EXC_OBJ) \
RESTORE_STACKTRACE_DEEPNESS \
} else if((excNrCatchTest & mask_##EXCEPTION##Jc)!= 0) \
{ ExceptionJc* EXC_OBJ = &_thCxt->exception[0]; \
excNrCatchTest = 0; //do not check it a second time
#define FINALLY \
RESTORE_STACKTRACE_DEEPNESS \
} } /*close CATCH brace */\
_thCxt->tryObject = tryObjectPrev; \
{ { /*open two braces because END_TRY has 2 closing braces.*/
//Write on end of the whole TRY-CATCH-Block the followed macro:*/
#define END_TRY \
} } /*close FINALLY, CATCH or TRY brace */\
_thCxt->tryObject = tryObjectPrev; \
if( excNrCatchTest != 0 ) /*Exception not handled*/ \
{ /* delegate exception to previous level. */ \
throwCore_emC(_thCxt); \
} else { /*remain exception for prev level on throwCore_emC if DEF_Exception_NO */\
clearException(&_thCxt->exception[0]); \
} /*remove the validy of _ixStacktrace_ entries of the deeper levels. */ \
RESTORE_STACKTRACE_DEEPNESS \
} /*close brace from beginning TRY*/
The distinguishing macros are:
#if defined(DEF_Exception_NO)
#define EXCEPTION_TRY
#define EXCEPTION_CATCH if(_thCxt->exception[0].exceptionNr !=0)
#elif defined(DEF_Exception_longjmp)
#define EXCEPTION_TRY \
if( setjmp(tryObject.longjmpBuffer) ==0) {
#define EXCEPTION_CATCH \
} else /*longjmp cames to here on THROW */
#else
#define EXCEPTION_TRY try
#define EXCEPTION_CATCH catch(...)
#endif
The EXCEPTION_TRY is empty, if no exception is used. If longjmp is used, this is a invocation of the setmp with the tryObject of this level which is also currently referenced in the thread context (_thCxt→tryObject). The forward branch delivers ==0, that is the following block. For C++ it is a simple try.
The EXCEPTION_CATCH for non-exception handling is a test of an exception which may be occured in the 'TRY' block. Then the CATCH blocks are entered, and the exception can be posthumously evaluated.
For the longjmp mechanism the following block is the else-block of the 'setjmp' which does not return 0. A longjmp continues inside the setjmp and returns !=0.
For the C++ catch the common unspecified catch(…) is used from C++. That is because the sophisticated C++ catch mechanism cannot made compatible with the other approaches of TRY-CATCH. The distinction between the exception type is made inside the tryObject. There the THROW writes the ''exception type info''.
11.1. Exception types, distinguish the exception reason
In the CATCH the exception number is checked by masking:
if((excNrCatchTest & mask_##EXCEPTION##Jc)!= 0)
The exceptions are defined as bis mask definition. For summarized (base) exception types some more bits can be checked.
The distinction of the exception reason follows the schema of Java. Java has a more simple exception concept than C++. The exception object is always derived from java.lang.Throwable respectively from the base java.lang.Exception. Some typical exception classes are defined in the core libraries, for example java.lang.IllegalArgumentException or the common java.lang.RuntimeException. The derived exception objects can hold data, but usual only a message as String, the java.lang.ArrayIndexOutOfBoundsException holds a int value, to store the faulty index.
For C usage the concept is simplified again. The ExceptionJc object stores a StringJc, the exception message, a int value and a 1-from-32-bit-value for the exception number. That’s all. It is enough to distinguish the exception type (1 of 32 bit) and hold the information to the exception. The mask characteristic of the exception ident value allows association to types of Exception. For example all Exception identificators with one of the bis masked with 0x0fff (12 exception types) is a RuntimeException. That is a simple replacement of the java approach: test instanceof RuntimeException It is a simple but sufficient system.
11.2. Info to C longjmp mechanism
The longjmp is a mechanism in C which should only be used to return from a deeper level of subroutine nesting to the higher (calling) level. The setjmp stores the current execution contex in the jmp_buf variable, which is the necessary internal information for the returning longjmp. The longjmp restores the ''current exeution context'', it is the stack frame of the calling routine which the known information in the jmp_buf. See [[!https://en.cppreference.com/w/cpp/utility/program/setjmp]]. That explaination is correct but it isn’t sufficient helpfull. The setjmp function (or macro) has two tasks:
-
If
setjmp(…)is invoked as statement, it returns 0 and stores the execution environment. -
On
longjmp(…)the execution lands in the setjmp-routine again, and it returns the value which is given onlongjmp(…), never0but1iflongjmpwas invoked with0(see C99 and C89 standard).
It means, testing the value after setjmp differs whether the setjmp is ''called by the original code and the execution context was saved to env'' (citiation from cppreference) or the setjmp routine was invoked from the longjmp (citiation: ''Non-zero value if a non-local jump was just performed. The return value in the same as passed to longjmp.''). It is necessary to invoke longjmp(jmp_buf, value) with a value !=0. That hint is missing on the cppreference page.
The example in the cppreference shows a back jmp to the calling level. Whether or not it is the only one proper action is not documented there. But it is explained in the C99 standard document
citiciation from C99 standard in [[!http://www.open-std.org/jtc1/sc22/wg14/www/docs/n1256.pdf]]: ''…if the function containing the invocation of the setjmp macro has terminated execution … in the interim, …, the behavior is undefined.'' For standard documents see also [[!https://stackoverflow.com/questions/81656/where-do-i-find-the-current-c-or-c-standard-documents]].
11.3. THROW
The THROW macro is defined with
#ifndef THROW
#ifdef DEF_Exception_NO
/**All THROW() macros writes the exception into the ThreadContext_emC,
* but the calling routine is continued.
* It should check itself for sufficient conditions to work.
*/
#define THROW(EXCEPTION, MSG, VAL1, VAL2) { if(_thCxt == null) \
{ _thCxt = getCurrent_ThreadContext_emC(); } \
_thCxt->exception[0].exceptionNr = nr_##EXCEPTION##Jc; \
_thCxt->exception[0].exceptionValue = VAL1; \
_thCxt->exception[0].file = __FILE__; \
_thCxt->exception[0].line = __LINE__; \
log_ExceptionJc(&_thCxt->exception[0], __FILE__, __LINE__); \
}
#else //both DEF_Exception_TRYCpp or longjmp:
#define THROW(EXCEPTION, MSG, VAL1, VAL2) \
throw_sJc(ident_##EXCEPTION##Jc, MSG, VAL1, __FILE__, __LINE__, _thCxt)
#endif
#endif
For the non-exception handling case it invokes immediately log_ExceptionJc(…) which should be a fast routine only store the exception values. For debugging a break point can be set there. The MSG is not stored in the Exception because of it may be refer to the stack frame area. Because of logSimple_ExceptionJc(…) copies the MSG, it can process it though.
Elsewhere the routine throw_sJc(…) gets all arguments, stores the exception values and invokes the C++-throw or the longjmp.
The MSG argument should be given as StringJc instance, or, if DEF_NO_StringJcCapabilities is set, this argument is typed as void const*. As StringJc it assembles the reference to the char const* itself and the length maybe with some more marker bits. It is not a zero-terminated string like usual in the old C.
Building a StringJc instance for the message as string literal is very simple using
THROW(Exception, z_StringJc("The message"), ix, max);
The z_StringJc(…) operation is a simple inline routine which invokes strlen(…) and stores it. strlen(…) is necessary anyway, it is not a loss of run time. But the same does
THROW_s0(Exception, "The message", ix, max);
The idenfifier for the exception is really a constant with the shown prefix and suffix. It is similar as in Java. The reason to do so is: In the CATCH check the user programm should use the same identifier, but there the mask_EXCEPTIONJc is necessary
The FILE and LINE arguments deliver important information for logging and analyze of the position of the THROW in the source also if no stack trace is used.
12. Which moduls are necessary for exception handling and for the simple variant
The basic effort for Exception handling depends on the kind and details.
12.1. Simple embedded numerical oriented system:
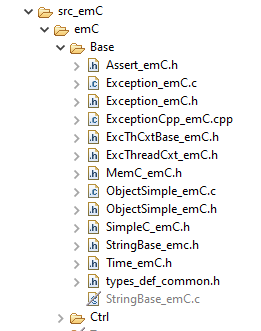
For a simple exception handling without String processind and longjmp, proper for a numeric oriented simple target, only the following source are need, the both images are a snapshot from a Texas Instruments Code Composer Studio project:
-
emc/source/emC/Assert_emC.h: Assertions may be activated or not. If activated it causes Exception handling. -
emc/source/emC/Exc*_emC.h: The headers, see above. -
emc/source/emC/Exception_emC.c: The routines for the exception handling with longjmp -
emc/source/emC/Exception_Cpp_emC.cpp: This sources is the alternative to use C++ exception handling. It includesException_emC.cbut forces C++ compilation anyway. -
emc/source/emC/MemC_emC.c: Some routines for MemC handling. -
emc/source/emC/ObjectSimple_emC.*: Not need for exception handling but need elsewhere. -
As seen in the image
emc/source/emC/StringBase_emC.cis not necessary. It is contained in this project but deactivated for target compilation, only used for PC test.
-
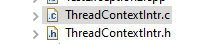
appl/ThreadContextIntr.h: A simple thread context definition for any interrupt and the backloop:#ifndef HGUARD_ThreadContextIntr_Test_T1Ctrl #define HGUARD_ThreadContextIntr_Test_T1Ctrl #include <applstdef_emC.h> /**Structure for ThreadContexts for Main and 2 Interrupts. */ typedef struct ThCxt_Application_t { /**The pointer to the current ThreadContext. */ ThreadContext_emC_s* currThCxt; ThreadContext_emC_s thCxtMain; ThreadContext_emC_s thCxtIntrStep1; ThreadContext_emC_s thCxtIntr2; }ThCxt_Application_s; // extern_C ThCxt_Application_s thCxtAppl_g; #endif //HGUARD_ThreadContextIntr_Test_T1Ctrl -
appl/ThreadContextIntr.c: With the proper simple implementation:#include "ThreadContextIntr.h" /**public static definition*/ ThCxt_Application_s thCxtAppl_g = { &thCxtAppl_g.thCxtMain, { 0 }, { 0 }, { 0 } }; ThreadContext_emC_s* getCurrent_ThreadContext_emC () { return thCxtAppl_g.currThCxt; }
12.2. Test on PC, in a single thread, for simple S-Functions in Simulink:
The following image shows a snapshot from a Simulink S-Function control file for PIDf_Ctrl_emC, a numeric FBlock, with C++ Exception Handling:
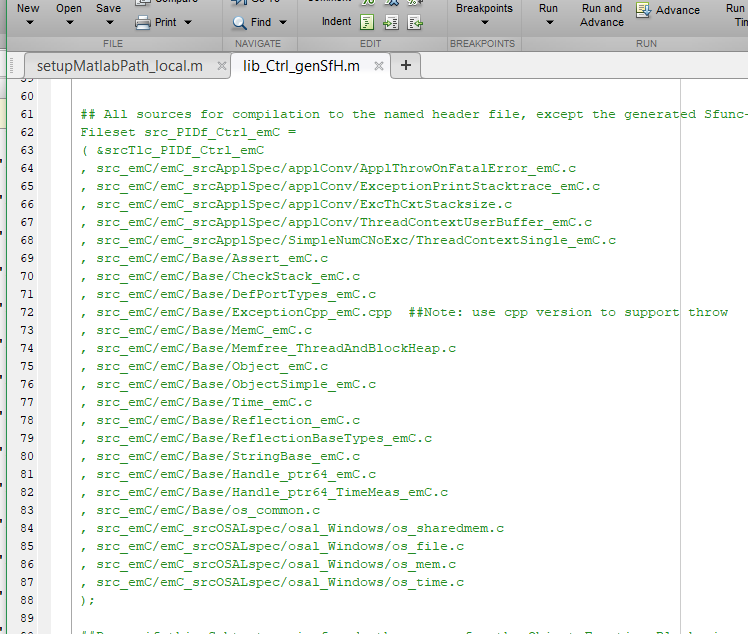
It contains all files necessary from emC/Base. Because full Reflection is used, some more files are need. The ThreadContext is provided by
-
src_emC/emC_srcApplSpec/SimpleNumCNoExc/ThreadContextSingle_emC.c: It provides a simple ThreadContext sufficient because the S-Function need only its own context:#include <applstdef_emC.h> //Note: This source should used if an application or dll //with own static memory runs only in 1 thread. //No switch of context, instead a static one. // ThreadContext_emC_s thCxtMain = {0}; //ThreadContext_emC_s* getCurrent_ThreadContext_emC () { return &thCxtMain; } -
src_emC/emC_srcApplSpec/SimpleNumCNoExc/ThreadContextUserBuffer_emC.c: It is necessary to copy a String from the stack local area to the ThreadContext area for exception handling with String processing. -
The other shown files are necessary independent of the question of Exception Handling.
12.3. Test on PC, with multithreading:
The source
-
emC_srcOSALspec/osal_Windows/os_thread.ccontains a os-thread specific area:typedef struct OS_ThreadContext_t { /**This is a constant text, to test whether a reference to OS_ThreadContext is correct. * It will be initialized with pointer to "OS_ThreadContext". */ const char* sSignificanceText; // OS_HandleThread THandle; /* handle des Threads */ // uint32 uTID; /* ID des threads */ // /**The thread run routine used for start the thread. */ OS_ThreadRoutine* ThreadRoutine; /** to be passed to the child wrapper routine */ void* pUserData; /**Name of the thread.*/ const char* name; /**The user ThreadContext is part of the thread specific data. * It is defined application-specific via the included applstdef_emC.h */ ThreadContext_emC_s userThreadContext; }OS_ThreadContext;
This area is gotten via the Windows API call:
OS_ThreadContext* getCurrent_OS_ThreadContext() {
return (OS_ThreadContext*)TlsGetValue(dwTlsIndex); }
The OS-independent ThreadContext is gotten via
ThreadContext_emC_s* getCurrent_ThreadContext_emC ()
{
OS_ThreadContext* os_thCxt = getCurrent_OS_ThreadContext();
if(os_thCxt == null){ //only on startup in main without multithreading
init_OSAL(); //only 1 cause if the ThreadContext haven't set.
os_thCxt = getCurrent_OS_ThreadContext(); //repeat it
if (os_thCxt == null) {
os_FatalSysError(-1, "init_OSAL failed, no ThreadConect", 0,0);
return null;
}
}
return &os_thCxt->userThreadContext; //it is a embedded struct inside the whole ThreadContext.
}
This routine does the initialization of the OS-level if it is not done, on the first call.
13. Calculation time measurement
@date=2020-10-07
The measurements was done with a Texas Instruments TMS320F28379D CPU on 100 MHz System clock (the CPU is able to run with 200 MHz, but only 100 MHz are used here). and also with a Infineon TLE9879 Processor with 40 MHz clock.
The measurement itself is done for the TI Processor with the Timer0 of the CPU which runs with this 100 MHz, it is 10 ns per Tick. Getting the value is execute via:
#define getClockCnt_Time_emC() ( -(Timer0_TICPU.cti) )
whereby Timer0_TICPU.cti is immediately the memory mapped timer register on the CPU. Because it counts backward, the - forces forward counting. The measurement is done with subtract two values:
thiz->currTimeStart = getClockCnt_Time_emC(); //.... The algorith in test thiz->calcTime = getClockCnt_Time_emC() - thiz->currTimeStart;
Hence the calcTime element contains the current calculation time in 10 ns steps.
For the Infineon TLE9879 the adequate was done with:
//Reference to the systick counter, prevent including hardware specific ...*/
extern_C int32 volatile* sysClock_HALemC;
INLINE_emC int32 getClockCnt_Time_emC ( void ) { return (-(*sysClock_HALCPU))<<8; }
The sysclock register counts with 40 MHz, but with 24 bit only. The sysClock_HALemC is the reference to this memory mapped register. Both routines getClockCnt_Time_emC() are equal for the call usage, it is the Hardware Adaption Layer strategy of emC. But the measurements are yet done for the TLE9879 with a binary output signal:
The following image illustrates the measurements with a binary output, used for the Infineon TLE 9879 EVALKIT. The small left 0-gap on D1 is about 150 ns. It is the time to output a 0 value and immediately after a 1 value on pin P0.1. It is 6 clock cycles of 25 ns, 40 MHz internal clock, need for 3 machine instruction (read, modify, set). The left cursor is the position of the end of the impuls if execTry ==0. It is a short interrupt routine with 50 µs cycle. The image demonstrates the relation of try and 10 calls, then throw in relation to the 50 µs-cycle. The other channels outputs pulse-width-modulation signals.
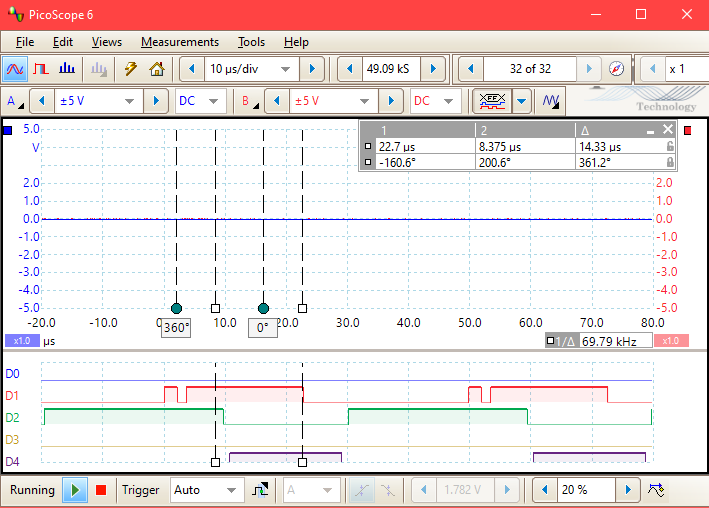
The test program uses the following
typedef struct TestException_T {
int32 currTimeStart;
int32 calcTime;
int32 ct;
int32 ctCall9;
int32 ctCall9NoThrown;
int32 ctExc;
uint execTry: 1;
uint execCallOneLevel : 1;
uint execCall10Level: 1;
uint execThrow : 1;
uint spare; //for 32-bit-alignment
} TestException;
A first level test routine is:
void testException ( TestException* thiz ){
thiz->currTimeStart = getClockCnt_Time_emC();
STACKTRC_ENTRY("testException");
if(thiz->execTry) {
TRY {
thiz->ct0 +=1;
if(thiz->execCall10Level) {
testExc1(thiz);
}
else if(thiz->execCallOneLevel) {
testExc9(thiz);
}
}_TRY
CATCH(Exception, exc){
thiz->ctExc +=1;
///
}
END_TRY;
}
STACKTRC_LEAVE;
thiz->calcTime = getClockCnt_Time_emC() - thiz->currTimeStart;
}
The several ct can be used to check which branch is executed. The elements of the data structure are monitored via the debugger access to the hardware. The hardware is a Launchpad F28379D:

and a TLE9879 EVALKIT from Infineon
With all exec bits set to 0 the calcTime is the effort to get the STACKTRC context, the measurement itself and the check of execTry. It is:
-
execTry == 0: 0.48 us Only organization for TMS320
13.1. Measurement with longjmp
Because the calculation time for the TLE9879 is measurement with the scope, the time for execTry ==0 is not measured, it is 0. The times for the TMS320 are adjusted, the 0.48 µs is subtract, so the times are comparable.
The following table contains all results. The TLE9879 is about 4 times slower (40 MHz Clock vs. 100 MHz, other instruction set. It is a more poor processor with lesser capabilty.
| condition | description | TMS320 | TLE98-O1 | TLE98-Ofast | |
|---|---|---|---|---|---|
execTry == 0 |
without any excpetion handling |
0 |
0 |
0 |
|
execTry == 1 |
only the frame, no exception |
1.44 |
6.8 |
6.9 |
|
execCallOneLevel == 1 |
one subroutine call |
2.04 |
8.75 |
8.93 |
|
execCall10Level == 1 |
ten subroutine calls |
3.05 |
13.25 |
10.83 |
|
execThrow=1, 10Level ==1 longjmp |
throw in the 10. subroutine |
4.49 |
14.35 |
13.78 |
|
execThrow=1, OneLevel ==1 longjmp |
throw in the first subroutine |
3.34 |
11.95 |
11.71 |
|
execThrow=1, 10Level ==1 C++ throw |
throw in the 10. subroutine |
268.9 |
— |
— |
|
execThrow=1, OneLevel ==1 C++ throw |
throw in the first subroutine |
117.8 |
— |
— |
-
execTry == 1: 1.92 us (1,44 µs after correction) for TMS320, TRY… END_TRY without call.
The pure organization of the TRY … END_TRY needs about 1.5 microseconds for all the stuff shown in macro implementation for longjmp. For a system with fast stepping of a controller algorithm for example for electrical nets (for example 20 µs cycle time) it is a effort but it is possible. Note that the TMS320 processor runs only on the half speed.
The Infineon TLE9879 needs 7 µs, not much less in optomized mode (Option -Ofast). That is much, but possible for a … 50 µs cycle. A single step debugging for the TLE9879 has come to light that there is optimizing potencial. The line
#define TRY \
...
TryObjectJc tryObject = {0}; \
calls a memcpy also in the -Ofast compilation. It can be improved by C lines, do only intialize what is necessary.
-
execCallOneLevel == 1: 2.52 / 2.04 µs for TMS320, TRY… END_TRY, one call without exception
The call of the testExc9(thiz) needs additionally 0.6 µs. The routine contains:
void testExc9 ( TestException* thiz ) {
STACKTRC_ENTRY("testExc9");
thiz->ct9 +=1;
if(thiz->execThrow) {
THROW_s0(Exception, "test", 0,0);
}
thiz->ctCall9NoThrown +=1;
STACKTRC_LEAVE;
}
For the TLE9870 it needs additonal 2 µs. It seems to be more optimized than the TRY organization.
-
execCallOneLevel == 0, execCall10Level=1: 3.53 / 3.05 µs for TMS320, TRY… END_TRY, ten times call without exception
It means, the addtional 9 calls till reaching the testExc9 needs about 0.11 µs, it is 11 instructions for the call and the increment of the counter:
void testExc1 ( TestException* thiz ) {
thiz->ct1 +=1;
testExc2(thiz);
}
Note: Without the volatile counter increment, only the empty
void testExc1 ( TestException* thiz ) {
testExc2(thiz);
}
the compiler has optimized all call levels (there are empty) though optimize level = 0 was selected but --opt_for_speed=5 was set.
The TLE9879 needs 4.5 µs for the 9 calls with -O1 and about 2 µs in -Ofast compilation. The optimizing is better because the sub routines do not contain own data and they all called one time only. The optimizing process economizes the stack frames (single step machine level debugging had show it). Hence only 9 Clock cycles are need for the simple call which is only a branch.
-
execCall10Level=1, execThrow=1: 4.49 µs TRY… END_TRY for TMS320, ten times call and THROW with longjmp
If the algorithm throws with longjmp, additional about 1.0 µs are necessary. But consider that the return instructions are not executed. That is the important number. This time includes the check of the exception type, here only one type of exception is intended. But that is a simple comparison with a constant.
The adequate time for the TLE9879 is 1.15 µs -O1, but 2.95 µs in -Ofast. It shows that the longjmp does need only 1.15 µs because it replaces the 9 return instructions. Because the returns was optimized for -Ofast, the 2.95 µs are the real value longjmp in comparison to the normal return.
-
execCall10Level=0, execCallFirstLevel=1, execThrow=1: 3.34 µs for TMS320, TRY… END_TRY one times call and THROW with longjmp
The TMS320 needs about additonal 1.3 µs in comparison to the execCallOneLevel. That is the real time for a longjmp. The TLE9879 needs additonal 3.2 µs for the longjmp instead to the normal return, 2.79 µs for -Ofast.
All in all, the results are usable. If the processor runs with full speed (200 MHz), the frame for Exception with a thrown exception needs about 2.5 µs. If the cycle runs with 20 µs on the TMS processor (to recognize frequencies till 25 kHz with Shannon’s sampling theorem and to control frequencies till about 2..5 kHz, it is possible. The rest of controlling may need 10..max 15 µs, it is well.
The more poor TLE9879 processor can use exception handling in slower step times. Especially in startup phase it may be important, but also in a slower interrupt (…1 ms). In a fast interrupt this processor will do only less things, which may not require exception handling.
13.2. Measurement with C++ exception handling (try - throw - catch)
The C++ exception is only tested for the TMS320 and on PC.
To use the C++ exception handling the sources for the TMS320 are compiled with the --exceptions option and with -cpp_default and --extern_c_can_throw. It is necessary that all files are compiled with activated C++ exception handling. Also some libraries especially for exception handling are need. All files are compiled with --abi=eabi, it is the more modern Object code format (against COFF, ELF is used). The compiler option --define=DEF_Exception_TRYCpp is set.
The TLE9879 has had a run time problem in the initalize phase with exactly the same compiler options, only the catch(…) and the throw instructions were present. Because of that other libraries are used in the initalizing phase, which forces the problem, not fixed till now.
On PC the exception handling with throw is not a problem. The interrupt routine is executed in a loop. Because for time measurement only the QueryPerformanceCounter() call from the Windows-OS can be used, it returns clocks in 100 ns steps, the execution time lesser 100 ns can’t be measurement. Hence no execution times are kept for the normal execution. The whole operation which needs about 15 µs on TMS320 needs 4 Clocks (400 ns). It is expectable well. Hence the test algorithm was run in a loop with 10'000 executions, and the time is measurement via manual view.
With this settings the following measurement results are gotten.
-
execTry == 1: 1.25 us TRY… END_TRY without call
The organization of TRY..END_TRY is faster, no longjmp object is necessary, 0.77 µs against 1.5 µs for longjmp.
-
execCallOneLevel == 1: 1.87 µs TRY… END_TRY, one call without exception
It is the same, additional 0.6 µs for the call and check without throw.
-
execCallOneLevel == 0, execCall10Level=1: 2.88 µs TRY… END_TRY, ten times call without exception
The call of the nine intermediate level need the same, in sume about 1 µs, 0.11 µs or 11 machine instructions per level. It is surprising in this respect because it is discussed that the organization of the stackframe levels for C++ exception handling need some time. It doesn’t seem that way.
-
execCall10Level=1, execThrow=1: 268.95 µs TRY… END_TRY, ten times call and THROW with C++ throw
This is the catastropic. The throw needs a very long time. It is the question what is done in that time. The result is not able to use for a cycle time in ranges of 20..50..100 µs in comparison with other algorithm which are fast, including floating point things etc.
-
execCall10Level=0, execCallOneLevel=1, execThrow=1: 117.81 µs TRY… END_TRY, one call and THROW with C++ throw
It seems to be, one stack frame needs (268.95 - 117.81) / 9 = 16.8 µs to rewind, and the base effort is about 100 µs.
On PC the call of 10'000 loops needs about 7 seconds if throw was activated. That is 700 µs per throw. If a PC software throws unnecessary (instead using a if-condition to capture this situation), a single throw is not able to recognize in wait time. If a software throws unnecessary ten times in any algorithm, it is not recognizeabler too. If a software throws unnecessary 100 times, it may be the reason that the software is slowly. The user have to wait 1… seconds for a response.
13.3. What is executed on C++ throw
void throwCore_emC(ThCxt* _thCxt) {
if(_thCxt->tryObject !=null) {
...
#elif defined(DEF_Exception_TRYCpp) || defined(DEF_Exception_TRYCpp)
throw _thCxt->exception[0].exceptionNr;
A throw is invoked only with a simple integer value, not with any dynamic allocated stuff. The assembler code is:
009e8a: 0202 MOVB ACC, #2 009e8b: 76408CFF LCR __cxa_allocate_exception 009e8d: C4F1 MOVL XAR6, *+XAR1[6] 009e8e: 0200 MOVB ACC, #0 009e8f: 8F40AD0C MOVL XAR5, #0x00ad0c 009e91: C2C4 MOVL *+XAR4[0], XAR6 009e92: 1E42 MOVL *-SP[2], ACC 009e93: 76408C6B LCR __cxa_throw
and further in a library, it is inside rts2800_fpu32_eabi_eh.lib
__cxa_throw(): 008c6b: B2BD MOVL *SP++, XAR1 008c6c: AABD MOVL *SP++, XAR2 008c6d: 8BA4 MOVL XAR1, @XAR4 008c6e: 86A5 MOVL XAR2, @XAR5 008c6f: A2BD MOVL *SP++, XAR3 008c70: 824A MOVL XAR3, *-SP[10] 354 __cxa_eh_globals *ehg = __cxa_get_globals(); 008c71: 76408BEA LCR __cxa_get_globals 363 ce->exception_type = tinfo; 008c73: 83A1 MOVL XAR5, @XAR1 369 ehg->uncaught_exceptions++; 008c74: 0201 MOVB ACC, #1 374 _Unwind_RaiseException(ue); 008c75: D99E SUBB XAR1, #30 363 ce->exception_type = tinfo; 008c76: DDAC SUBB XAR5, #44 008c77: AAC5 MOVL *+XAR5[0], XAR2 364 ce->exception_dtor = dtor; 008c78: A2D5 MOVL *+XAR5[2], XAR3 369 ehg->uncaught_exceptions++; 008c79: 560100E4 ADDL *+XAR4[4], ACC 374 _Unwind_RaiseException(ue); 008c7b: 8AA1 MOVL XAR4, @XAR1 008c7c: 764087A5 LCR _Unwind_RaiseException 384 __cxa_call_terminate(ue); 008c7e: 8AA1 MOVL XAR4, @XAR1 008c7f: 76408C60 LCR __cxa_call_terminate 008c81: 82BE MOVL XAR3, *--SP 008c82: 86BE MOVL XAR2, *--SP 008c83: 8BBE MOVL XAR1, *--SP 008c84: 0006 LRETR
The last statements are not executed because inside _Unwind_RaiseException it is continued.
This routine was found as source code inside the CCS suite:
_Unwind_RaiseException: .asmfunc stack_usage(CONTEXT_SZ + RETADDRSZ)
;
; This function must:
; 1. Save all of the SOE registers in stack-allocated "context,"
; including RETA as "PC".
; 2. Call __TI_Unwind_RaiseException(uexcep, context)
; If things go well, this call never returns.
; 3. If __TI_Unwind_RaiseException returns an error, return
; its return value to the original caller (stored in "PC")
;
MOVL XAR7, #__TI_Unwind_RaiseException
_ Unwind_Resume_ENTRY:
; The goal here is to capture the state in the caller ; (__cxa_throw, __cxa_rethrow) as it would be if URE returned ; like a normal function. For instance, [PC] is the return ; address of the call.
; ; 1. Save all of the SOE registers, plus RETA, SP, and PC ;
MOVZ AR5, SP ; fetch SP as it is now, which is ; the address of the context. This ; also populates ARG2 (XAR5) MOVL XAR6, XAR5 SUBB XAR6, #RETADDRSZ; compute what it was in the caller
MOVL XAR0, *-SP[2] ; grab previous RPC from the stack
; this is the value of the RPC register
; in the caller
PUSH XAR0 ; [RETA] = caller's RPC PUSH XAR6 ; [SP] = caller's SP PUSH RPC ; [PC] = URE's RPC PUSH XAR1 PUSH XAR2
-
etc.
In succession there was calles a
_CODE_ACCESS void *bsearch(
register const void *key, /* ITEM TO SEARCH FOR */
register const void *base, /* POINTER TO ARRAY OF ELEMENTS */
size_t nmemb, /* NUMBER OF ELEMENTS TO SORT */
size_t size, /* SIZE IN BYTES OF EACH ITEM */
int (*compar)(const void *,const void *)) /* COMPARE FUNCTION */
with 75 for nmemb etc. What ever is done - it is not exactly analyzed yet.
There are three obscurities yet:
-
1. It may be presumed that a throw algorihtm is not reentrant.
-
2. It is possible that the exception handling for some target platforms are not used often, because developers do not use C++ elaborately, or lesser developer do use something in C++ but do not use exception handling. Inferential it may be that the algorithm are not enough optimized because there is no request by compiler users.
-
3. It may be expected that there may be small bugs, because it is not frequently used.
In opposite, the longjmp mechanism is not frequently used too, but it is simple and present since a very long time for the compiler builders.