Häufig wird ein Eclipse-Projekt, für Java oder für Embedded C/++, so aufgezogen, dass ein Workspace angelegt wird. Im Workspace
befinden sich ein oder mehrere zusammengehörige Projekte. In den Projekten befinden sich die Quellfiles, projektspezifisch
oder kopiert aus ähnlich gelagerten Vor-Projekten. Libraries werden per Pfad eingezogen.
Das erscheint einfach, scheinbar so gewollt von der Eclipse-IDE und dem Arbeitsstil entsprechend. Das "Advanced"-Button bei
Anlage oder Einbeziehen von Files wird nicht genutzt.
Diese Kurzdoku beschreibt, wie ein Eclipse-Projekt aufgeteilt wird in
den Eclipse-Workspace an sich,
das Eclipse-Projekt mit projektbeschreibenden Files und generierten Files
die Quellen der Programme (Source-Files)
Alle diese drei befinden sich an verschiedenen Speicherorten auf der Festplatte, sind referenziert. Das Warum und Wie wird
im Artikel beschrieben. Zusätzlich oder damit zusammenhängend wird auf den Aufbau eines Produktes aus Komponenten eingegangen.
1 Nachteil eines Gesamt Workspace/Projekt/Quellen-Arbeitsbereich
- Was gehört zu einem Produkt und ist wie zu archivieren
Sind Workspace, Projekte und Sources in einem Arbeitsbereich, dann umfasst dieser sehr viele Files:
1) Source Files
2) Projektdefinierende Files
3) Compilate (obj, class, map etc.)
4) Settings als Kopie für alle genutzten und nicht genutzten Eclipse-plugins
5) Sehr viele und große temporäre files
Wenn man davon ausgeht, dass diese Detailhaftigkeit nicht interessiert: Es wird halt alles archiviert, dann wäre das ok. Speicherkapazitäten
sind groß genug - und wer interessiert sich wirklich schon für alle Details in archivierten Softwareständen. Es wird wenn
nötig wieder restauriert, möglicherweise sollte man die gleiche Eclipse-Version verwenden, die sich auch bei wesentlicher
PC-Plattformänderung über Jahre in VMs (VmWare häufig verwendet) packen lässt. Also was soll's? - Dies ist eine Herangehensweise.
Dieser alles umfassende Workspace umfasst nicht:
6) Eingezogene Libraries entweder im Toolbereich selbst oder per Verwaltung auf dem Internet geholt. Diese Libraries stehen
oft im HOME-Bereich des Users.
7) Das Tool selbst, IDE, Compiler, Linker.
Es kann sein dass eine Neugenerierung mit einem neuen Versionsstand der Toolsoftware andere, bessere Ergebnisse liefert. Häufig
sind diese genau so gut lauffähig, vielleicht optimiert. Es kann aber auch sein, dass ein Softwarefehler mit einem gegebenen
Tool- und Librarystand A nicht auffällt, also unbemerkt bleibt, in einer anderen Version aber dann doch zutage tritt und als
unbekannter Altfehler Ärger bereitet.
Man geht also fehl in der Annahme, das Archivieren des gesamten Workspace wäre sicher und ausreichend, man hat dabei die Libraries
vergessen (!).
Die andere Herangehensweise geht davon aus, dass genau bekannt sein sollte, wo was steht und wie etwas funktioniert ("Was die Software im Innersten zusammenhält").
Die wirklich wichtigen zu archivierenden Quellen der Software für eine Nachbearbeitung, Fehlersuche und Wiederverwendung sind
=> langfristig zu archivieren:
1) Source Files
2) Projektdefinierende Files
6) Die eingezogenen Libraries
Dagegen
=> kann jederzeit auch täglich wieder generiert werden:
3) Compilate (obj, class, map etc.)
Diese können am Tagesanfang, zu Beginn der Session neu generiert werden. In normalen Projekten dauert eine solche Generierung
wenige Sekunden.
Die Settings
=>sind arbeitsplatzspezifisch
4) Settings als Kopie für alle genutzten und nicht genutzten Eclipse-plugins
Sie enthalten auch beispielsweise geänderte Erscheinungsformen (Appearance) der Schriftgrößen, Farben, aber auch Key-Settings.
Wie diese letztlich eingestellt sind, hat keinen Einfluss auf das Software-Ergebnis, ist aber dem Bearbeiter wichtig. Man kann diese Einstellungen auch exportieren (File->Export) um sie in einem anderen Workspace wieder zu importieren (File->Import). Die Einstellungen sind dann in den exportierten Files häufig auch in nachvollziehbarer (lesbarer) Form außerhalb von Workspace
und Projekten speicherbar. Da diese Files wie oben schon erwähnt keinen Einfluss auf das Softwareergebis haben, gehören sie
also auch nicht zur Versionierung der Software, wohl aber zu Einstellungen zum Tool oder auch persönlichen Einstellungen.
=> braucht man nicht aufzuheben:
5) Sehr viele und große temporäre files
=> Ist mit der Toolversion gegeben:
7) Das Tool selbst, IDE, Compiler, Linker.
In der Regel sollte man Installationsfiles des Tools aufheben, damit jedenfalls die originalen Compiler- und weitere Tools
wieder hergestellt werden können. Man sollte auch an ergänzende Generiertools denken, die evtl. selbst erstellt wurden und
nicht im Internet im nachhinein auffindbar sind. (!) Die Tools selbst gehören nicht in das normale Software-Versionsmanagement,
wohl aber in die Archivierung zu einem Produkt.
2 Eclipse-Workspace neu anlegen und Projekte importieren
Topic:.EclipseWrk..
Der Workspace mit importiereten Projekten enthält:
4) Settings als Kopie für alle genutzten und nicht genutzten Eclipse-plugins
5) Sehr viele und große temporäre files
Wenn man (beispielsweise auf einem anderen PC) einen neuen leeren Eclipse-Workspace angibt und mit diesem Pfad Eclipse öffnet,
dann enthält die Eclipse-IDE kein Projekt, die Default-Settings und bereits wieder viele temporäre Files.
Ein Workspace ist grundsätzlich jederzeit neu anlegbar, beispielsweise mit einer neuen Toolversion, beispielsweise auf einem
anderen PC, beispielsweise um ein Projekt zweimalig in der Bearbeitung zu haben. Der Workspace ist nicht aufhebewürdig. Er
kann jederzeit gelöscht werden - wenn dort drin nicht die Sources und Projektfiles selbst stehen. Letzteres ist dringen nicht
empfohlen.
Man tut nun gut daran, die Settings als Preferences exportiert zu haben oder dies jetzt am anderen PC noch zu tun, und diese im neuen Workspace zu importieren.
Diese Settings ersetzen also die im Workspace gespeicherten
<=> als *.pref personenbezogen gespeichert und restauriert
4) Settings als Kopie für alle genutzten und nicht genutzten Eclipse-plugins
Wenn man ein neues Projekt anlegt, dann gibt es die Möglichkeit, die Checkbox Use default location abzuwählen und statt dessen eine gewünschten Platz für das Projekt anzugeben.
Damit ist schonmal Workspace (mit den vielen temporären und nicht projektspezfischen Settings) getrennt vom Projekt selbst.
Das Projekt selbst wird archiviert aber getrennt von den Sources. Warum wird in todo erklärt. Hat man ein Projekt irgendwo gespeichert, auch und insbesondere innerhalb eines anderen Workspaces, oder von einem anderen
PC, oder aus einem Archiv, dann kann man es importieren, wie rechts gezeigt wird. Eigentlich wird damit ausgeführt add Project to Workspace, importieren ist etwas irreführend denn das Projekt wird nicht in den Workspace hineingezogen sondern mit dem Import lediglich referenziert.
Das Projekt wird im Workspace unter .metadata/.plugins/org.eclipse.core.resources/.projects referenziert, möglicherweise auch noch an anderen Stellen. Das braucht man aber nicht zu wissen und zu beachten, denn der
Import lässt sich beliebig oft an anderer Stelle wiederholen.
Im neuen Workspace sollte man dann auch die irgendwo am PC projektunabhängig gespeicherten Preferenzen (Einstellungen der
IDE) importieren.
3 Viele temporäre Files auf einer RAM-Disk speichern
Topic:.EclipseWrk.RamDisk.
Die Compilate (Generate), die zur Abarbeitung benötigt werden, braucht man eigentlich und wirklich nicht über eine Session
aufzuheben. Im Gegenteil. Eine "Clean-all" Mentalität ist hilfreich, wenn man nicht mehr weiß was noch geht und warum.
Folglich gehören die Generate auch nicht auf die Festplatte, man braucht sie nicht zu speichern. Zu Beginn einer Session wird
mit "Clean and Build all" alles neu erstellt. Das dauert heutzutage ein paar Sekunden gegenüber früher Minuten bei gleicher
Projektgröße. Das "Clean & Build all" sichert am Anfang der Session, das alles in Ordnung ist, alle Tools sind ok, Buildeinstellungen
stimmen. Nichts ist schlimmer als der Anfangsschein, es würde alles laufen, und dann stellen sich unklare Situationen ein.
Im Gegensatz zu alten Zeiten (noch vor 10 Jahren) sind RAM-Größen in einer ähnlichen Größenordnung wie Festplatten. 8 GByte
sind es sicherlich auf einem Entwicklerrechner. Mein Notebook hat 16 GByte, der PC daneben 32 GByte RAM. Damit passen die
Generate locker auf eine RAM-Disk. Der Nebenvorteil ist die höhere Schreibgeschwindigkeit gegenüber einer HD oder auch SSD.
Ein weitere Nebenvorteil, praktisch bedeutungslos, man sagt den SSDs begrenzte Schreibzyklen nach. Unabhängig von dieser Mär
- man muss nichts auf SSD speichern, was nicht speicherwürdig ist.
Die RAM-Disk als Speichermedium am PC benutze ich schon erfolgreich seit vielen Jahren. Erstmalig war dies an einem Industrie-PC,
der 'nur' eine 4 GByte-Flash-Festplatte hatte. Es gab schlechte Erfahrungen mit häufigem Schreiben auf Flash-Disks, so dass
temporäre Files im eigentlich groß bemessenen Arbeitsspeicher (damals auch ca. 2 GByte) Platz finden konnten. Die Idee der
RAM-Disk war aber gut, so dass ich sie seither auch auf dem normalen Arbeits-PC/Notebook verwende. Bewährt hat sich: http://www.radeonramdisk.com/.
Es ist nicht notwendig, den Inhalt der Ramdisk als Image auf der Festplatte zu speichern da die RAM-Disk eigentlich für temporäre Files und Compilate verwendet wird, die man am Anfang einer Session sowieso neu
erstellen sollte. Man kann auf die RAM-Disk auch das gesamte TEMP- und TMP-Directory umleiten (TEMP- und TMP-Umgebungsvariable
umbesetzten), denn alle temporären Dinge sind, wie der Name auch sagt, temporär, nicht aufhebenswürdig. Das funktioniert auch
bei den vielen vielen Files, die Windows scheinbar wichtigtuend auf der C-Festplatte aufhebt. Das ist nicht nötig.
Die Möglichkeit mit einer RAM-Disk mit gespeichertem Image zu arbeiten ist dann gut, wenn man auch extrem schnelle Lesezugriffe
braucht, etwa im Server/Datenbanken-Bereich. Dafür gibt es die kostenpflichtigen Versionen mit bis zu 64 GByte RAM-Speicher
(oder mehr), das trifft aber nicht unsere Zwecke.
Die Files, die häufig hauptsächlich geschrieben sind, sind bei der Arbeit als Softwareentwicker:
a) die Compilate, obj, class
b) zugehörige Reportfiles, map und dergleichen
c) Log-Files beim Abarbeiten und Testen
d) Ergebnisfiles bei Test- und Konvertierungsroutinen
Bei der Filegruppe d) habe ich mir angewöhnt, Ergebnisfiles mit den gespeicherten Musterfiles zu vergleichen, zu bewerten,
und ggf. die Musterfiles, die auf der Festplatte stehen, damit upzudaten. Damit ist die Filegruppe d) auch gut auf der flüchtigen
RAM-Disk aufgehoben. Ähnlich ist es mit den c) Log-Files, die ggf. für den Test als Muster verglichen werden müssen, sonst
aber eher temporär sind.
Wie groß soll die RAM-Disk sein? Erfahrungsgemäß reichen auch 500 MByte. Nur wenn man große Logfiles erzeugt, wird dieser
Rahmen gesprengt. Da man auf einem Entwickler-PC oder Notebook heutzutage aber durchaus 16 GByte Ram hat, kann man locker
1 GByte abknapsen für die RAM-Disk, auch 4 GByte, die braucht man aber nicht. Schreibt man die RAM-Disk mit irgendwelchen
Logs voll, dann kann es schonmal eine unklare Situation geben, da die meisten Programme auf die 'Disk is full'-Situation nicht
sauber programmiert sind. Es hilft: Zwischendurch mal kontrollieren, wie voll die RAM-Disk ist.
Die RAM-Disk hat den Vorteil der sehr hohen Schreibgeschwindigkeit. Das ist insbesondere gegenüber der traditionellen magnetischen
Festplatte wichtig. Eine SSD ist zwar heutzutage nicht mehr so sensibel auf häufige Schreibvorgänge, aber auch hier spart
die RAM-Disk für die häufig neu erzeugten nur temporären Files erheblich.
4 Ausgabeverzeichnis im Eclipse-Projekt und anderen IDEs auf RAMdisk umleiten
Topic:.EclipseWrk.EclPrjRam.
Folgende Ausführungen gelten auch für andere IDE, beispielsweise Visual Studio.
Meistenteils wollen die IDEs ihre Ausgabefiles direkt unter dem Projekt speichern. Da das Projekt aber besser auf der Festplatte
stehen sollte, kommen die temporären Files automatisch auf die Festplatte? Nein, denn es gibt Symbolic links.
Die Symbolic Links gibt es in UNIX schon seit den Anfangszeiten. DOS und Windows hat dies zu Anfang nicht unterstützt. Mittlerweile
gibt es aber den Befehl
mklink /J NAME DSTPATH
Das mklink hat auch eine Option /D die als Symbolische Verknüpfung ausgewiesen ist. Diese funktioniert aber nur mit Administratorrechten. Das /J ist als Junction bezeichnet und funktioniert ganz genauso gut. Offensichtlich hat man sich im Hause Microsoft zunächst sehr schwer getan mit
den Symbolic Links, die ein Otto-Normaluser eventuell nicht versteht, hat sie also in die Admin-Ecke geschoben. Als Alternative
ist die Junction entstanden, die aber mittlerweile alles kann was notwendig ist.
Mit diesem Mittel ist es relativ leicht, die temporären Verzeichnisse auf die RAM-Disk bzw. auf das TMP-Verzeichnis umzuleiten.
Man ist nicht darauf angewiesen, die RAM-Disk mit einem bestimmten Verzeichnisbuchstaben zu haben (was der Kollege nebenan
vielleicht nicht einsieht oder einsehen will). Sondern: Man sagt, das ist im TMP-Bereich wo es ja auch hingehört. Der TMP-Bereich
ist dann wie oben beschrieben bei den Spezialisten auf die RAM-Disk gelegt.
Es ist günstig einen batch-File zur Erzeugung des symbolischen Junction-Link zu speichern, der sich gleichzeitig um ein Clean kümmert:
Die zugehörige ...\src\testTI\Test_All\+clean.bat ist davon getrennt weil sie auch aufgerufen wird, um nach der Session oder ggf. vor einer Zip-Sicherung oder vor einem finalen
Clean & Build all alles zu bereinigen:
echo removes %~d0%~p0\Debug etc.
if exist %~d0%~p0\Debug rmdir /S/Q %~d0%~p0\Debug
if exist %~d0%~p0\RelO3 rmdir /S/Q %~d0%~p0\RelO3
if exist %~d0%~p0\DbgC1 rmdir /S/Q %~d0%~p0\DbgC1
if exist %~d0%~p0\RelC1 rmdir /S/Q %~d0%~p0\RelC1
Die Schreibweise mit %~d0%~p0 kann man nachlesen, wenn man help call oder adäquates auf der Console eingibt oder das Internet befragt. Es ist der Aufrufpfad der +clean.bat die im aktuellen Verzeichnis steht.
Die Namen der einzelnen Ausgabeverzeichnisse ergibt sich aus Projekteinstellungen. Man muss mit diesen die beiden hier genannten
Files mit pflegen.
5 Source-Files im Projekt als Link
Topic:.EclipseWrk.srcLnk.
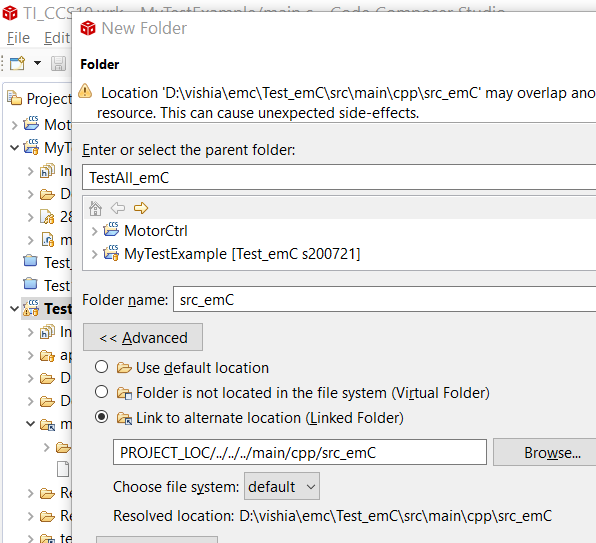
Was bei anderen IDEs selbstverständlich ist, ist bei Eclipse mit dem Zusatz-Button Advanced erreichbar: Die Source-Files für das Projekt werden als Link gespeichert und können sich also irgendwo anders im Filesystem
befinden.
Bei Visual Studio werden in den Projektfiles (*.vcxprj und *.vcxproj.filters) automatisch relative Pfade gespeichert, wenn kein anderer Laufwerksbuchstabe angegeben wird. Bei Eclipse kann man die Pfade
bezogen auf die Project-Location angeben, damit sind sie ebenfalls relativ.
Es empfielt sich, das IDE-Project und die Sources in der selben Sandbox oder Working area zu haben (bitte nicht mit dem Eclipse-Workspace verwechseln). Aber, die Source-Files und die IDE-Projectfiles sind getrennt.
Warum:
Sourcefiles können in verschiedenen Projekten und für verschiedene Targets compiliert werden.
Mindestens zu empfehlen ist ein Projekt für PC-Simulation für eine Software die auf einem embedded Target läuft.
Bei Eclipse kann man einzelne Files in Subdirectories im Projekt addieren, indem das Advanced-Button betätigt wird und der absolute Pfad angegeben wird. Man kann damit einzelne Files auswählen, die compiliert werden
sollen. Auf die gleiche Weise lässt sich aber auch ein Directory einbinden, dessen alle Files also zum Projekt gehören und
compiliert werden. Das ist häufig gewünscht. Einzelne Files kann man dann ausblenden, indem sie über ihre Properties vom Build
ausgeschlossen werden.
Achtung: Das im Beispiel-Bild gezeigte Source-Verzeichnis gehört zum Projekt und bleibt dort leer. Es muss in den Projekt-Baum auf der Festplatte mit gespeichert werden
obwohl es eigentlich leer ist. Ansonsten zeigt das Projekt den verlinkten File nicht an.
In den Projektfiles .project entsteht für das Beispielbild der Eintrag:
Die Verwendung des absolute Path ist aber nicht empfohlen, siehe oben, man hat zuwenig Flexibilität. Der relative Pfad kann
nicht mit ..\ beginnend angeben werden, damit kommt Eclipse nicht zurecht.
Aber man kann die interne Eclipse-Umgebungsvariable PROJECT_LOC verwenden und bezieht damit den Pfad auf das Projektverzeichnis. Das ist genau richtig wenn man eine feste Struktur in der
Sandbox oder Working area hat.
In den Projektfiles .project entsteht dann der Eintrag:
6 Die Sandbox insgesamt auf einer feste Position auf der Festplatte
Topic:.EclipseWrk.RBX.
Ein anderes Thema ist das Beziehen einer Sandbox oder Working space auf eine feste Festplattenposition. Es wäre nun fatal, wenn diese feste Festplattenposition vorgeschrieben wäre. Man müsste
dann sich über viele möglicherweise mitarbeitende Kollegen, Abteilungen und Partner auf bestimmte Verzeichnisnamen einigen,
über alle Projekte. Das geht nicht.
Hier helfen wiederum die Symbolischen Links oder Junctions unter Windows.
Warum ist das notwendig? Tools tendieren dazu, die Pfade der Sources in Generate einzuschreiben. Auch wenn diese letzlich
nicht im Binärcode des Produktes notwendig sind, sie sind 'nur' notwendig für ein Debugging, beeinflussen die Pfade Optimierungsergebnisse.
Folglich ist ein Binärcode nicht identisch erzeugbar, wenn die Compilierung von einer anderen Festplattenposition ausgeht.
Das ist leider eine unschöne Eigenschaft der Tools, denn die Idee eines "reproducible build" ist nicht überall präsent, obwohl
sie exterm hilfreich ist.
Warum ist "Reproducible build" hilfreich - weil mit einem gespeicherten Satz von Sources jederzeit ein identisches Binary erstellt werden kann. Es kann
dann auf der Basis des identischen Binaries kleine Änderungen eingebracht werden, deren Auswirkungen wiederum lokalisierbar
sind. Man spart sich gegebenenfalls einen sonst notwendigen umfangreichen Test, wenn ein neu gebildetes anders aussehendes
Binary eingesetzt werden soll. Das sind häufig fünfstellige Beträge vor dem Komma in € oder $.
Man kann nun einen Link erzeugen:
C:
cd \
if not exist RBX mkdir RBX
cd RBX
mklink /J MySpecialProject c:\D\Path\to\Project\Location
RBX steht für "Reproducible SandboX", ein Verzeichnis C:\RBX ist sicherlich machbar. Das MySpecialProject ist die Bezeichnung des Projektes für das reproducible build, dessen location. Der Pfad ist nun ein beliebiger Pfad dort
wo das Projekt eigentlich steht.
Alle Files erscheinen als unter C:\RBX\MySpecialProject stehend. Da im Projekt selbst überall relative Pfade angeben wurden, funktioniert alles.
Man kann dieses C:\RBX\MySpecialProject jederzeit wieder entfernen, auch temporär schnell mal für einen anderen Buildvorgang per batch oder shell, weil die eigentlichen
Files ja woanders stehen. Folglich gibt es keinen Path-clash, keine Notwendigkeit der Abstimmung von absoluten Paths mit anderen
Kollegen oder Abteilungen und gar nichts.
Eine Alternative dafür ist eine Laufwerkssubstituierung, die sich aber aufgrund der möglichen Symbolic Junctions erübrigt
hat. Dennoch sind Anmerkungen aus einer älteren Ausgabe dieses Texts folgend stehengeblieben, da man teils noch auf diese
Verfahren trifft:
Die Laufwerks-Substituierung mit dem subst-Cmd gibt es immer schon seit DOS. Die Laufwerkssubstituierung wirkt für das gesamte Filesystem und wird von Compilern berücksichtigt.
Lediglich für bestimmte Tools (MSI-Installer) kann man es nicht verwenden. Das ist der Stand unter Windows-10.
Es gibt eine begrenzte Anzahl freier Laufwerksbuchstaben, die unterschiedlich sind auf verschiedenen Systemen je nach Nutzer-Vorliebe.
Anbieten würden sich A: und B: da kaum jemand eine Diskette benutzt und die erste Festplatte immer noch auf C: liegt. Ungünstig
ist Z:, dies wird bei VMware standardgemäß belegt.
Da auch andere Tools (auch Compiler) intern aus gleichen Gründen auch substuieren, benutzen diese auch gern B: als Laufwerksbuchstaben.
Man muss also damit rechnen, dass das ausgewählte laufwerk, B: belegt ist, je nach verwendetem Tool. Das macht das Ganze zwar
etwas unsicher, aber immerhin testbar in bestimmten Umgebungen möglich.
Um der Belegung des Laufwerkes B: von Tools aus dem Weg zu gehen, kann man einen dazwischenliegenden Buchstaben verwenden,
der häufig noch frei ist. Das Problem dabei ist, dass das bei allen Bearbeitern zutreffen muss, sonst muss man wieder anpassen
und ändern. Diese Bedingungen hat uns allerdings Microsoft-Windows aufdiktiert, es hat niemals die bewährte Methodik der Symbolic Links dem Anwender bereitgestellt. Es gibt beispielsweise eine Beschreibung https://docs.microsoft.com/en-us/windows/win32/api/winbase/nf-winbase-createsymboliclinka, die aber anscheinend nur innerhalb von Programmen gilt, es ist eine Beschreibung einer Windows-API-Schnittstelle.
-------------------------------------------------
Im Zusammenhang mit dem Folgekapitel, Komponenten auf verschiedenen absoluten Pfaden im Projekt, die dann nicht mehr per Laufwerks-Ersetzung
adressierbar sind, ist also die Variante B) mit Toolunterstützung zweckmäßiger.
7 Hard links und symbolic links im Windows-Betriebssystem
Topic:.EclipseWrk.hlink.
In Unix gibt es die Hardlinks und symbolic links von je her. Im Windows sind Hardlinks mit dem NTFS-Verzeichnissystem ebenfalls
möglich, kaum dokumentiert und kaum jemand weiß es:
Dieser cmdline-Befehl (mit admin-Rechten) erzeugt das File src/test.c ab dem currdir als Hardlink zum vorhanden File ../src/TestString_emC.c. Man darf sogar den slash statt dem Backslash verwenden! mit Backslash im cmd geht es freilich genauso. Das Beispiel geht
mit allen Files, sie müssen aber auf dem selben Datenträger stehen.
Was ist ein Hardlink? Ändert man im Beispiel src/test.c dann ist gleichzeitig ../src/TestString.c mit geändert. Nicht etwa weil die Änderungen irgendwie (per Zauberei) auf das andere File übertragen werden, sondern weil
sich die Daten des Files auf dem selben Platz befinden, es also nur einmal Daten des Files gibt. Die Namen (Einträge im Directory)
gibt es zwei mal, aber der eigentliche Speicherplatz des Fileinhaltes ist der selbe. Damit ist klar, dass die eine Datei (=
der selbe Speicherplatz über den einen Verzeichniseintrag) sich sofort auch auf die andere Datei (selber Speicherplatz über
einen anderen Verzeichniseintrag) auswirkt. Da die Verzeichniseinträge und der eigentliche Speicherplatz für den Fileinhalt
eine Sache des selben Datenträgers sind, sind Hardlinks selbstverständlich nur auf dem selben Datenträger wirksam (Hinweis:
nicht der "gleiche" sondern "ein und derselbe").
Diese Möglichkeit kann man nun nutzen, um Files einzurichten die im lokalen Workind-Directory stehen, ohne wie im Vorkapitel
beschrieben über die Advances-Möglichkeit zu gehen und die Links im Eclipse zu organisieren.
Dennoch ist es ggf. günstiger über "Advanced" und den Link in Eclipse zu gehen weil dies besser kontrollierbar ist. Einem
File (-Eintrag im Directory) sieht man nicht an dass er einen Zweitzugriff über einen anderen File(-Eintrag im Directory)
hat, das ist also weniger durchschaubar als ein Link im Eclipse.
Auch die Softlinks funktionieren in Windows. Diese sind bekannt als *.lnk-File, beispielsweise zur Umleitung des Verzeichnisses C:/Programme auf C:/Program Files für die deutsche Windows-Version. Die Frage ist, ob der Symbolic-Link dieser Art verwendet werden kann direkt im Filesystem.
Mindestens unter Visual Studio Code funktioniert dies:
d:\vishia\emcTest\TestString_emC\VScode>mklink /J src\emC\Base d:\vishia\emC\Base
Verbindung erstellt für src\emC\Base <<===>> d:\vishia\emC\Base
Mit diesem Befehlt wurde ab dem Arbeitsverzeichnis im vorhanden Subdirectory src/emC ein File Base.lnk erstellt, in dem die genannte Referenzierung auf den Absolutpfad steht. Die Dateien erscheinen im Visual Studio Code wie
ganz normale Files. Auch hier gilt: Änderung dieser Files betreffen das Original. Der Vorteil von Symbolic Links ist: Sie
sind im Filesystem erkennbar.
Ein zip vom gesamten Ordner mit lnk-Subordnern erfasst die verlinkten Subordner so als ob sie kein Link sondern direkt wären
(getestet mit Zip im Total Commander). Das hat den Nachteil, dass ein Auslagern von viel temporären Files nun doch wieder
nicht gelingt, aber man kann ein Zipfile mit entsprechenden Cmd-Aufrufen auch gezielt so erstellen, dass nur bestimmte Files
aus einem Subordner in das Zip gelangen.
Hard- und Softlinks existieren im Betriebssystem UNIX seit Anfang an. Hardlinks sind eine natürliche Erscheinungsform, zwei
Verzeichniseinträge zeigen einfach mal auf die selbe Section auf der Festplatte. Das hat mit der Organisation der Festplatten-Verzeichnisstruktur
zu tun, die in UNIX von vornherein so angelegt ist. Soft-Links sind dagegen in UNIX eine Sonderkonstruktion, die seinerzeit
wünschenswert war weil es die Hardlinks gibt und weil UNIX immer schon eine feste Struktur der Verzeichnisse hatte, nur ein
Verzeichnisbaum ab der Root und keine Laufwerke, und somit das Mounten weiterer Datenträger bzw. die freie Umleitbarkeit der
Zugriffe über Softlinks erfolgte. Systemprogrammierer unter UNIX (und später Linux) können damit umgehen.
DOS und Windows in der Anfangszeit war dagegen basierend auf dem CPM-Filesystem (FAT16, FAT32) aus den 80-ger Jahren nicht
mit diesen Features ausgestattet. Wann genau das NTFS-Filesystem auch Hard-links beherrschte ist dem Verfasser im Moment nicht
bekannt. Die Softlinks (*.lnk-Files) sind dagegen wahrscheinlich jedem Windows-Nutzer bekannt. Ob und seit wann der Filezugriff über die Windows-API-Filefunktionen,
also von jedem Programm nutzbar, die Softlinks nutzen kann, ist dem Verfasser im Moment ebenfalls nicht bekannt. Jedenfalls
scheint es unter Windows-10 zu funktionieren.
Die breite Nutzung von Hardlinks und Softlinks für diverse Directories ist im Windows aber nicht so sehr geläufig. Offensichtlich
ist nirgends beschrieben, dass sich das bin-Verzeichnis recht einfach auf eine RAM-Disk umleiten lässt. Man muss solche Nutzungen
daher gut dokumentieren und erklären, da sie für andere Nutzer irretierend sein könnten.
8 Die Crux mit den vergessenen Libraries, Denken in Komponenten
Topic:.EclipseWrk.extCmpn.
Wenn man sich in Sicherheit wiegt, dass man alle Files doch in einem Workspace relativ innerhalb Eclipse gespeichert hat,
später oder auf einem anderen Rechner das Projekt aus dem Archiv holt und dann compiliert, dann kann es sein dass es Detailprobleme
gibt.
Libraries werden oft aus dem Tool-Pool dazugelinkt, indem sie im Projektfile eingezogen werden. Wenn eine andere Toolversion
installiert ist, andere Prozessoren im Embedded-C-Bereich unterstützt oder eben nicht unterstützt werden, Details mit der
Zeit etwas anders geworden sind, dann wird dies ggf. erst bei Testen festgestellt, oder beim Compilieren fehlen die Libraries.
Häufig gibt es automatische Updating-Möglichkeiten, die die fehlenden Informationen aus dem Internet ergänzen. Ist das gut
so? Sind Informationen mal schnell aus dem Internet geholt immer richtig. Solange man nicht extrem sicherheitskritische Dinge
tut, ist es zumal der schnelle Schritt. Die Wahrscheinlichkeit, in eine Sicherheitsfalle zu tappen, ist zwar >0, aber meist
passiert das nicht.
Was läuft falsch? Libraries die extern zugelinkt werden gehören genau so zu den Sources eines Produkts wie Quellen. Sie gehören
folglich in die projektspezifische Versionierung. Es muss jederzeit möglich sein, aus den versionierten Quellen das Produkt
zu erzeugen, gegenzuchecken auf Unveränderbarkeit, um es danach wie notwendig zu korrigieren!
Was sind eigentlich Libraries? Sie erscheinen als etwas gegebenes, fremdes, wofür der Lieferant gerade stehen muss. Diese
Denkweise wird aber falsch, wenn man bedenkt, dass letztlich nur das Entwicklerteam für das jeweilige Produkt garantieren
kann. Einen Fremdlieferant zur Verantwortung zu ziehen ist zwar juristisch möglich, aber dann gibt es meist bereits einen
Schadensfall.
Libraries sind auch nur Sources, die vorcompiliert sind und in dieser Form als Libraries gebündelt.
Es gibt folgende Fragestellungen:
Sind die Sources der Libraries offen und/oder zugänglich?
Muss man die Sources der Libraries selbst verstehen oder mindestens verantworten? Um sie zu verantworten (als 'richtig' gegenüber
dem Produkt oder Endkunden) muss man sie nicht unbedingt selbst verstehen sondern kann sich auf Urteile anderer verlassen.
Wo ist die Grenze? Libraries sind oft Adaptionen eines Application-Interface-Kernes zum Betriebssystem oder Standard-Libraries
zum Compiler passend zum Prozessor. Die API-Libraries des Betriebssystems xy Version 123 kann man als gegegene Betriebssystemschnittstelle
akzeptieren, gleichermaßen die Standard-Libraries. Man kann aber auch bis zu den Prozessorbefehlen selbst vordringen wollen,
oder ggf. noch weiter zum Microcode, den man etwa mit Prozessoren im FPGA beeinflussen kann, oder mit einer passenden Auswahl
eines Prozessors. Für zeit- oder sicherheitskritische Embedded-Applikationen kann das interessant sein.
Eine Software besteht aus Komponenten:
e) Eigene projektspezifische Sources
f) Wiederverwendete Sources aus ähnlichen Projekten, die eine Basis darstellen
g) Sources die die Plattform ergänzen bzw. darstellen
h) Sources für bestimmte Funktionalitäten, die als solche nicht projekt- oder plattformspezifisch sind, aber zum Produkt benötigt
werden.
Nur die Sources nach e) sind projektspezifisch und können nach entsprechender Qualifizierung (müssen allgemeingültig sein)
teils zu den Sources f) kommutieren.
Bei den Sources nach f) ist es eben nicht angeraten, diese in das Projekt zu kopieren und danach projektspezifisch anzupassen.
Damit sind sie nicht mehr allgemeingültig, die Wiederverwendung ist gebrochen. Von einer Wiederverwendung sollte nur gesprochen
werden, wenn eine unveränderte Wiederverwendung möglich ist bzw. Änderungen für eine weitere (verbesserte) Wiederverwendung
gebrauchsfähig sind und die geänderten Sources nach f) auch in den ursprünglichen Projekten wieder direkt eingesetzt werden
können.
Folglich sind die Sources nach f) teils als eingezogene Libraries betrachtbar. Gleiches gilt für Sources nach h).
Es ergibt sich nunmehr die Fragestellung:
Einbindung dieser als 'Komponenten' zu bezeichnenden Sources nach f), h) und vielleicht auch g) als Library, oder als Source-File?
Eine Library ist die Zusammenstellung vorübersetzter Sources
Wenn man in den Sources, sei es auch nur zu Testzwecken, geändert hat, dann muss man die Sources neu übersetzen. Es könnte
daher angebracht sein, dieses Sources direkt einzuziehen. Sie sollen aber dann nicht kopiert zu dem Projekt dazugehören, sondern
weiterhin als Fremd-Komponente gelten. Temporäre Änderungen etwa für Testzwecke sind ok, wenn sie zurückgestellt werden. Oder
Änderungen als Weiterentwicklung dieser wiederverwendeten Komponente ist in Ordnung, muss aber geprüft werden und gewissenhaft,
nicht nur auf das konkrete Projekt bezogen, ausgeführt werden. Das ist Mehraufwand.
Libraries haben im C/++-Bereich den Vorteil, dass beim Linken aus der Library nur die benötigten Object-Files einbezogen werden.
Wenn die gesamte Library als Source in das Projekt einbezogen wird, dann sollte deren Compilierung nicht mit den Project-Objects
gemischt werden, sondern bei der Compilierung sollte aus diesem Grund die Library neu gebildet werden. Dann funktioniert weiterhin
das Prinzip der Selektierung der Objects. Andererseits kann man einzelne Files aus einer Fremdkomponente auch direkt als Object
einbeziehen, um einen Compilierschritt zu sparen, und diese Source bei der Produktbildung dann wieder über die Library führen.
Die Sources können für eine bestimmte Zielplattform gegebenenfalls unter spezifischen Bedingungen übersetzt werden. Dabei
spielt vielleicht nicht nur die Eigenschaft der Zielplattform eine Rolle (dann wären die Libraries zielplattformspezifisch),
sondern die Bedingungen können auch vom Projekt selbst bestimmt werden. Dann sind die Sources selbst unverändert und wiederverwendet
nach f) aber das Compilat ist projektspezifisch. In C/++ lässt sich das sehr einfache bewerkstelligen, indem in den Sources
Headerfiles includiert werden, die projektspezifisch ausgeprägt sind, oder bestimmte Compilerschalter (#define) projektspezifisch beim compilieren gesetzt sind. Diese herangehensweise ist auf jeden Fall gerechtfertigt, wiederspricht
dem Library-Nutzungs-Gedanken, nicht aber dem Komponenten-Wiederverwendungs-Gedanken.
Nun kann es inbesondere typisch sein, dass die wiederverwendeten Sources gleichzeitig in verschiedenen Projekten am selben
PC eingesetzt werden, eben weil bei deren Verbesserung zeitnah oder 'gleich mit' getestet werden soll, ob die Änderungen gut
sind:
Verwendung der Komponenten-Sources nach f) in verschiedenen Tests
Verwendung dieser Komponenten-Sources in den anderen Projekten mit Test, ob die Änderungen dort verträglich sind.
Eben aus diesem Grund (der sofort einbezogenen Tests) ist es nicht günstig, die Sources jedes mal über checkin/commit in das
Revisionsmanagement zu führen oder zwischen Working spaces zu kopieren, sondern sofort unverzüglich mit jeder Änderung in
dem anderen Projekt zu testen.
Das spricht für entweder absolute Pfade zu den Speicherorten dieser Komponenten-Sources, oder mindestens für relative Pfade
mit ../.., wenn die anderen Projekte ebenfalls relativ danebenstehend angeordnet sind.
Folglich muss in den Projektfiles (in Eclipse, in Visual Studio etc.) es eine Anpassmöglichkeit der Speicherorte komponentenweise
geben. Das ist die Variante B) im Vorabschnitt.
9 Eindeutige Pfadangaben zu Komponenten-Files
Topic:.EclipseWrk.pkg.
In Java ist es gängige Praxis, Sources in Packages anzuordnen. Packages sind auf Fileebene eine Subdirectory-Struktur. Die
Packages fangen üblicherweise mit der umgekehrten URL (www-Adresse) an, damit werden Name-clashes weltweit verhindert. Das
ist ein Quasistandard, an den sich an sich jeder hält. Packages der Standard-Java-Sources beginnen beispielsweise mit com.sun.awt obwohl diese Files schon längst von Oracle geändert worden sind (Oracle hatte Sun im Jahre 2010 übernommen). Die Package-Bezeichnung
bleibt. Eigene Packages sollten diesem Schema ebenfalls entsprechen.
In C/C++ ist dieses Schema ebenfalls anwendbar, aber leider nicht verbreitet. Dies ist ein Plädoyer für dessen Verwendung:
In den Komponenten können im Kompenenten-Arbeitsverzeichnis die Sources in einem Subdir-Path wie bei den Java-Packages gespeichert
werden. Hilfreich ist auch hier die Verwendung der umgekehrten URL, um firmenübergreifend Name-clashes sicher zu vermeiden.
Es ist kein Vorteil wenn Files in
MyComponent/workdir/source/xy.cpp
gespeichert sind, sie können genauso in
MyComponent/workdir/vishia/emC_Ctrl/Ctrl/xy.cpp
gespeichert werden, also mit einem etwas tieferen und wohl definiertem Subdir-Baum. Die Zeiten, in denen die Länge eines Path
im System etwa auf 128 Character begrenzt war, sind vorbei.
In allen #include <..>-Anweisungen kann der gesamte Subdir-Baum innerhalb der Komponente stehen, nicht zu dessen Working-Dir, also innerhalb des
Working-dirs. Beispiel:
#include <vishia/emC_Ctrl/Ctrl/CalcExpr.h>
Diese Schreibweise des Include mit package-path ist in C seit Anfangszeiten möglich aber wenig genutzt. Er wird von allen
Compilern unterstützt. Man muss es nur tun.
Vorteil: Verhinderung von name-Clashs
Nachteil: Ein gewisser Zwang sich nach etwas zu richten was man zunächst gar nicht einsehen möge.
Diese Schreibweise ermöglicht aber nun die eindeutige Anpassung von Projektfiles an die Speicherorte von Komponenten mit absoluten
Pfaden.
Persönliche Anmerkung: Der konsequenten Anwendung des Package-Path-Prinzips aus Java für C/++ habe ich mich auch erst schrittweise
genähert. Ich hätte sie seit 15 Jahren schon umsetzen können. Da dies im C/++-Bereich aber überhaupt nicht üblich ist, obwohl
es problemlos geht, war auch ich inkonsequent. Auch jetzt ist es noch inkosequent, da die Packages meiner Sources mit org/vishia anfangen müssten, nicht nur mit vishia. Dazu wäre aber im Filesystem einiges umzuschieben. Daher lasse ich das org weg, in der Hoffnung das es keine andere Seite im fernen Indien, China oder sonstwo gibt die ebenfalls mit vishia beginnt. org/vishia ist insofern eindeutig, da dies meine Internetadresse weltweit registriert ist.
 Man tut nun gut daran, die Settings als Preferences exportiert zu haben oder dies jetzt am anderen PC noch zu tun, und diese im neuen Workspace zu importieren.
Man tut nun gut daran, die Settings als Preferences exportiert zu haben oder dies jetzt am anderen PC noch zu tun, und diese im neuen Workspace zu importieren.
 Wenn man ein neues Projekt anlegt, dann gibt es die Möglichkeit, die Checkbox Use default location abzuwählen und statt dessen eine gewünschten Platz für das Projekt anzugeben.
Wenn man ein neues Projekt anlegt, dann gibt es die Möglichkeit, die Checkbox Use default location abzuwählen und statt dessen eine gewünschten Platz für das Projekt anzugeben.
 Hat man ein Projekt irgendwo gespeichert, auch und insbesondere innerhalb eines anderen Workspaces, oder von einem anderen
PC, oder aus einem Archiv, dann kann man es importieren, wie rechts gezeigt wird. Eigentlich wird damit ausgeführt add Project to Workspace, importieren ist etwas irreführend denn das Projekt wird nicht in den Workspace hineingezogen sondern mit dem Import lediglich referenziert.
Hat man ein Projekt irgendwo gespeichert, auch und insbesondere innerhalb eines anderen Workspaces, oder von einem anderen
PC, oder aus einem Archiv, dann kann man es importieren, wie rechts gezeigt wird. Eigentlich wird damit ausgeführt add Project to Workspace, importieren ist etwas irreführend denn das Projekt wird nicht in den Workspace hineingezogen sondern mit dem Import lediglich referenziert.
 Im neuen Workspace sollte man dann auch die irgendwo am PC projektunabhängig gespeicherten Preferenzen (Einstellungen der
IDE) importieren.
Im neuen Workspace sollte man dann auch die irgendwo am PC projektunabhängig gespeicherten Preferenzen (Einstellungen der
IDE) importieren.