1 Modulare Programmierung als Mittel der Fehlerfreiheit
Topic:.SwEng.Modular.
Es ist erstaunlich, wie fehlerfrei doch Software ist. Man bedenke, ein Programm besteht beispielsweise aus 1000000 Bytes Code
(heute ein kurzes Programm, 1 MByte). Dabei gibt es 2 hoch 1000000 Kombinationen, von der nur eine richtig ist. Ein 6-er im
Lotto ist wahrscheinlicher.
Das bedeutet immerhin, ein kleiner Fehler lässt die gesamte Software crashen.
Wie schafft man es, fehlerfreie Software hinzubekommen?
Würde man die gesamte Software einer Applikation überblicken wollen (dazu gehört dann eigentlich auch noch Betriebssystem,
Treiberroutinen usw.), dann überschreitet das schnell mal das menschliche Aufnahmevermögen. In den 50-ger und 60-ger Jahren,
als Software noch relativ einfach war, gelang das noch. Eine damalige Ansicht - Software sein eine Kunst. Nur wenige - Experten
- vermögen sie zu beherrschen. Seit dieser Zeit sind aber an Softwaresysteme immer höhere Anforderungen gestellt, die auch
beherrscht werden. Die Softwaretechnologie hat schritt gehalten. Doch es gibt gute und weniger gute Software. Dieser Artikel
möchte einige Aspekte der Softwaretechnologie beleuchten, die zu guter Software führen.
1.1 Divide et impera - Software modular beherrschen
Topic:.SwEng.Modular..
Wichtig für die Fehlerfreiheit (ich spreche mal nicht von Fehlerarmut, weil die Freiheit, nicht die Armut das Ziel ist) ist also der Überblick über die softwaremäßigen Funktionalitäten und Implementierungen.
Jeder Zweig sollte durchdacht und getestet werden. Aber wie gelingt dies? divide et impera - Teile und herrsche. Schon die alten Römer wussten dies.
Bezüglich der Modularität sind zwei Feststellungen wichtig:
Ein Modul für sich muss vollständig überschaut werden können. Dann ist fehlerfreie Software möglich.
Ein Modul muss sich nach außen wohl definiert verhalten, dieses Außenverhalten muss bekannt und berücksichtigt werden.
Baut man nun als kleinen - fehlerfreien, beherrschten - Modulen größere Einheiten zusammen, dann gilt für den Zusammenbau
von Modulen wiederum das gleiche. Der Zusammenbau (wieder ein Modul, ein umfassenderes, oder eine Komponente) muss vollständig
überschaut werden können. Dazu gehört, dass das Verhalten der genutzten Module nach außen richtig berücksichtigt wird. Man
braucht sich dann um die Richtigkeit des Innenlebens der genutzten Module nicht mehr zu kümmern.
Dann ist dieses umfassendere Modul ebenfalls fehlerfrei hinzubekommen. Nun gilt der induktive Schluss: Baut man aus fehlerfreien Modulen immer größere Einheiten überschaubar und damit fehlerfrei zusammen, dann ist das gesamte
System fehlerfrei. Das ist es.
Dazu, dass das Modul der jeweiligen Ebene überschaut wird, gehört auch, dass die Anforderungen, was das Modul/die Komponente
zu leisten hat, richtig berücksichtigt worden sind. Erwartet jemand etwas anderes als realisiert worden ist, dann ist klar,
dass da ein Problem ist. Wenn das Verhalten nach außen nicht eindeutig beschrieben ist, dann ist auch klar, dass der Eine
etwas erwartet was der Andere überhaupt nicht realisiert hat. Diese Problematik unterstreicht die Zweckmäßigkeit der Modularisierung.
Sie hebt aber die Notwendigkeit der exakten Definition der Modulschnittstellen hervor.
Ein einfaches Beispiel: Nehmen wir an, wir brauchen einer Routine, die zwei Zahlen quadriert. Ganz einfach:
float quadrat(float x){ return x*x; }
An der Notation in C/C++/Java/...-Syntax erkennt man noch eine weitere Schnittstellenfestlegung: Das intern benutzte Zahlenformat
soll float sein. float ist bei den drei genannten und einigen anderen, aber nicht allen Programmiersprache ein Zahlenformat, was etwa 7 Dezimalstellen
darstellen kann und einen Zahlenbereich bis etwa 10 hoch 38 umfasst. Es gibt auch noch eine Unschärfe um die 0: Die kleinsten
darstellbaren Zahlen liegen bei 10 hoch -38, die 0 gibt es aber auch. Abhängig von Implementierungen gibt es im float-Format
noch einige andere Darstellungen.
Daher muss das äußere Verhalten dieser Routine noch etwas besser spezifiziert werden. Was passiert, wenn eine Zahl quadriert
werden soll, die sehr groß ist, deren Quadrat den Zahlenbereich sprengt. Da gibt es mehrere Möglichkeiten:
a) Es wird eine Begrenzung ausgeführt. Beispielsweise wird quadriert bis 10 hoch 15, Ergebnis ist 10 hoch 30. Alle größeren
Inputs ergeben ebenfalls 10 hoch 30. Das geht in diesem Fall nicht ganz bis an die Grenze der technischen Darstellbarkeit
der Zahl.
b) Es wird eine Exception geworfen und damit die Routine nicht ausgeführt.
c) Es wird der technisch definierte Wert "Infinity" angenommen.
Dieses Verhalten muss spezifiziert sein. Alle drei hier genannten Möglichkeiten machen Sinn. Die Begrenzung ist beispielsweise
zweckmäßig in regelungstechnischen Berechnungen, weil ein Stellglied eben nicht weiter aufgemacht werden kann oder ein Sollwert
in einem begrenzten Bereich liegen muss, auch bei temporär abwegigen Eingangswerten. Die Exception ist dann eine gute Wahl,
wenn es um sensible Zahlen geht. Die Variante c) verschleppt das Fehlerbild, mit dem Wert "Infinity" kann beispielsweise in
Java einfach weitergerechnet werden, ohne dass das zunächst bemerkt wird. Aber diese Variante ist auch die verträglichste,
wenn das genaue Ergebnis sowieso nicht interessiert bei solch großen Zahlen.
Möglicherweise denkt ein Benutzer, dass die Quadradwurzel aus einem Quadrad einer Zahl immer identisch mit der Zahl selbst
ist, und baut darauf seine Software auf. Dann hat er aber ein Verhalten der Quadrierung nach außen nicht beachtet.
Auch wenn die Zahl sehr klein ist, ist etwas zu beachten. Es gilt nicht immer:
x * x / x == x
Dieses Beispiel soll nur demonstrieren, was eigentlich alles beachtet werden muss, auch bei solch einer einfachen Aufgabenstellung.
Aber es soll auch zeigen, dass man an alles denken kann.
1.2 Black / gray / white-box
Topic:.SwEng.Modular..
Der blackbox-Gedanke soll ausdrücken, dass eine Implementierung nicht interessiert, sondern nur das Verhalten nach außen.
Insoweit ist es eine Betonung des Modularitäts- und Schnittstellengedankens und irgendwann in der Entwicklung des Software-Engeneerings
ein ganz wichtiger Gedanke.
Anwender interessieren sich aber oft, was innen vorgeht. In eine White box darf man vollständig hineinschauen, aber selbst
nicht ändern. Das ist ebenfalls ein konsequenter Modularitätsgedanke, aber mit open-source-touch. Gegebenenfalls spart man
sich einiges an Beschreibung, wenn man sagt - schaut doch nach, was realisiert ist. Open vs. Modularität oder doch nur praktische
Denkweise? Gray liegt dazwischen.
1.3 Modular ...
Topic:.SwEng.Modular..
Bei der Programmierung interessieren nebst der Forderung nach Erfüllung der Funktionalität zwei Dinge:
timeToMarket: Bereitstellungszeit, Termine einhalten
Fehlerfreiheit (-armut) der Software.
Bewertet man heute umgängliche Anwendersoftware, dann gibt es zwei Aussagen:
Software läuft stabil und sicher. obwohl es komplexeste Algorithmen sind.
Software verhält sich unerwartet in Ausnahmesituationen seltsam.
Beide Aussagen lassen den Schluss zu:
Sichere Software ist erstellbar, obwohl der Umfang der abgearbeiteten Befehle äußerst hoch ist.
Software kann auch mal falsch sein.
Beide Aussagen wiedersprechen sich nicht. Falsche Software sollte aber nicht zu Verlusten (an materiellen Gütern oder Leib
und Leben) führen, sondern eben nur ärgerlich sein.
Die Modularität richtet sich nach der ersten Aussage:
Einzelne Module können in ihrem Umfang so überschaubar sein, dass sie (möglichst) fehlerfrei programmiert sind.
Werden komplexere Funktionalitäten aus fehlerfreien Modulen nach einem fehlerfreien Entwurf zusammengesetzt, dann ist diese
komplexere Funktionaltät wiederum fehlerfrei.
Damit ist die Modularität der Schlüssel zu fehlerfreier (-armer) komplexer Software.
Die Anforderung an ein Modul ist wie folgt zu stellen:
Ein Modul muss eigenstängig entwickel- und testbar sein. Nach außen sind definierte Schnittstellen auszuweisen.
Ein Modul sollte nur so umfänglich sein, dass es überschaubar bleibt. Submodule können dabei an ihren Schnittstellen als blackbox
betrachtet werden.
2 Module oder Komponenten
Topic:Programming.ModulStructure.ModulOrComponent
Komponenten werden im allgemeinen über den Modulen angesiedelt: Eine Komponente besteht aus mehreren Modulen. Die Komponenten
sollten eher eigenständig aufgefasst, funktionstüchtig oder zu gebrauchen sein. Von einem Modul muss man nicht voraussetzen,
dass es eine unabhängige anwenderorientierte Funktionalität besitzt.
Wo der Schnitt zwischen Komponente und Modulen ist, kommt aber ganz auf die Anwendung an. Das kann unterschiedlich sein. Eine
Einrichtung in einer Fertigungsstraße kann durchaus als Modul bezeichnet werden, aus Sicht der Gesamtfertigung. Daher wird in diesem Artikel der Begriff Modul allgemeingültig verwendet. Alle Aussagen betreffs Modul können auch auf Komponenten bezogen werden. Modularität ist eine allgemeingültige Herangehensweise. Begriffe wie Komponentenorientierter Softwareentwurf können in anderen Sachzusammenhängen durchaus ihre Berechtigung haben. Dieser Artikel bezieht sich auf das Zusammenspiel
von Softwareteilen insgesamt und allgemeingültig.
3 Verknüpfung von Modulen
Topic:Programming.ModulStructure.ModulConjunction
Es gibt mehrere Möglichkeiten der Verknüpfung von Modulen, die zunächst unabhängig entwickelt werden. Die Verknüpfung muss
spätestens zur Laufzeit bei Notwendigkeit vorhanden sein. Gegebenfalls ist eine feste Verknüpfung bereits beim Start einer
Applikation oder Anlage erwünscht, möglicherweise aber schon bei der Erstellung. Man spricht hier von früher oder später Bindung.
Die Verknüpfung von Modulen ist unter verschiedenen Gesichtspunkten zu betrachten. Erstens abhängig von der frühen oder späten
Bindung, zweitens abhängig davon, was unter einem Modul verstanden wird, ob es eine feste räumliche Beziehung gibt oder Module
verteilt komminizieren müssen, drittens hängt es auch von den Konkreta der technischen Ausgestaltung ab. Nachfolgend sind
gängige Mittel und Praktiken genannt, die jeweils ihr Anwendungsgebiet haben.
Die Verbindung von Modulen kann als eng oder weit betrachtet werden, mit folgenden Kriterien:
Anordnung in einer Executable, statisch oder dynamisch gelinkt.
Anordnung in einer Hardwarekomponente, in verschiedenen Executables, aber mit einem gemeinsamen Speicher, Abarbeitung vom
selben Prozessor möglicherweise mit mehreren Cores.
Anordnung in Hardwarekomponenten, die direkt hardwaretechnisch miteinander verbunden sind, aber verschiedene Speicher haben
(verschiedene Prozessoren).
Verteilte Anordnung in einer Anlage oder räumlich stärker getrennt.
Die enge oder weite Bindung hat entscheidende Auswirkungen auf die Beständigkeit der Schnittstellengestaltung. Module, die
in einer Executable zusammengelinkt sind, müssen nur für den Buildprozess dieser Executable passende Schnittstellen haben.
Spätere Builds können auch die Schnittstellen ändern, wichig ist nur das man immer zueinanderpassende Revisionen linkt. Dabei
können formelle Tests sicherstellen, dass alles korrekt ist. - Anders bei weiter Bindung. Hier kann ein Anwender auch beliebig
austauschen oder mixen. Daher ist eine Schnittstellenverträglichkeit über viele Versionen notwendig. Wenn das Zusammenspiel
immer nur für bestimmte Versionen getestet und freigegeben ist und mit anderen Kombinationen in der Tat nicht funktioniert,
ärgert man die Anwender.
Abhängig von enger oder weiter Bindung, statischem oder dynamischen Linken kommt der Schnittstellengestaltung eine höhere Bedeutung zu als der Funktionalität. Schnittstellen müssen/sollten auf Jahrzehnte kompatibel oder abwärtskompatibel bleiben. Positives Beispiel dafür ist das
sonst oft kritisierte Betriebssystem MS-DOS und MS-Windows. Wenn man Schnittstellen festlegt, dann kann man Slots für die
Zukunft einplanen und offenhalten, die zunächst nicht oder nur formell funktionell realisiert werden. Der Softwareentwurf
muss sich mit den Schnittstellen beschäftigen, nicht mit den kleinlichen Details der Funktionalität. Das kommt danach - und
gehört selbstverständlich zu einem abgerundetem Ergebnis. Aber wenn die Schnittstellen nicht gut durchdacht sind, gibt es
zunächst den schnellen Erfolg mit nachfolgenden Desaster in den darauf folgenden Jahren.
Statisches Linken ist der klassische Weg und bereits bei der Assemblerprogrammierung gängige Praxis. Das Prinzip wurde dann
in C übernommen, C ermöglicht das Einbinden von Assemblerprogrammen mit in C formulierten Schnittstellen.
Bei der Compilierung oder Assemblierung entstehen Objectfiles. Diese enthalten als Ergebnis der Übersetzung den Maschinencode
und dazugehörige Symboltabellen. Es gibt Symbole (Labels), die benötigt werden (external) und Symbole, die in diesem Objectfile bereitgestellt werden (public). Die Labels bezeichnen Speicheradressen, entweder für den Startpunkt einer Subroutine oder für einen Speicherbereich (struct, external Variablen).
Der Linker bringt diese Labels zueinander. Etwas, was irgendwo benötigt wird, muss von einem anderen Objectmodul bereitgestellt
werden. Da die Objectmodule in ihrem Maschninencodeanteilen oder Datenbereichen aneinandergehängt werden, ist dann auch die
Adresse, die dem Label zugeordnet wird, bekannt. Bei der Adressbildung muss noch ein Offset für die Ladeadresse berücksichtigt
werden, das soll aber nicht hier detailliert behandelt werden (Locater). Die gebildetet Adresse eines Labels wird dann an
den Stellen, an denen das Label benötigt wird, in den Maschinencode eingetragen. Damit wird der Maschninencode komplettiert,
die Module, hier Inhalte von Objectfiles, sind mit den festen Adressen verbunden. Die Subroutinen aus anderen Modulen können
nun direkt ausgeführt werden, auf die Daten kann direkt zugegriffen werden.
Die andere Aufgabe des Linkes ist, Objectmodule zu sortieren. Das ist insbesondere für Anwendungen im Embedded-Bereich, wo
verschiedene Prozessoren und differenzierte Speicherorganisationsbedingungen vorliegen, entscheident. Auf einem PC ist Speicher
im Allgemeinen reichlich und gleichartig vorhanden. In einer Embedded-Hardware gibt es ROM (Flash)-Speicher auf bestimmten
Speicheradressen, bestimmte RAM-Bereiche, möglicherweise intern im Prozessor mit schneller Zugriffszeit und zusätzlicher Speicher
außen, aber langsamer. Dazu kommen Dual-Port-RAM-Bereiche für die Kopplung mit anderen Hardwarebestandteilen und FPGA-Adressbereiche
oder andere Memory-Mapped-IO-Bereiche. Die Speicherbereiche haben also verschiedene Eigenschaften, Daten und Programm müssen
passend dort plaziert werden.
In C werden die Labels aus den Identifier der jeweiligen Elemente gebildet, als aus den Namen der Routinen und dem Namen der
Datenelemente. In der Regel wird ein Unterstrich vorangestellt, um einen eigenen Namensraum gegenüber manuell in Assembler
vergebenen Labels zu bekommen.
Ob ein Label extern ist, stellt der Compiler selbst fest: Dann wenn es benutzt wird aber nicht definiert wird. Die extern-Deklaration im Headerfile ist nicht direkt dafür verantwortlich, siehe übernächsten Absatz.
Namensräume für Labels: Wenn man Bezeichnungen von Routinen und Daten nach belieben ausführt, dann ist die Wahrscheinlichkeit einer doppelten Benutzung
des selben Labels etwa im mittleren Bereich, muss nicht auftreten. Aber die Gefahr eines Konfliktes ist hoch. Dieser kommt
meist dann, wenn man nicht damit rechnet und ihn nicht gebrauchen kann: Bei kleinen Softwarekorrekturen wegen Bugs. Man bindet
nur schnell noch ein anderes Modul hinzu, das die korrekte Funktion enthält, aber man wusste vorher nicht, dass der Kollege
X die selben Bezeichner für andere Sachen genutzt hat.
Um nicht alle Bezeichner eines Programmes in den Konfliktbereich der doppelten Labels zu bringen, hat man in C mit dem Schlüsselwort
static:
static struct XY data;
static int myRoutine(){...}
die Möglichkeit erfunden, diese Bezeichner nicht als externe Labels in die Sichtbarkeit des Linkers zu bringen. In Assembler
gibt es die Möglichkeit ebenfalls, mittels Weglassen der global-Bezeichnung.
Es gibt in C für die Namenskonflikte keine allgemeingültige Lösung. Üblich ist es oft, alle Bezeichnungen für global sichtbare
Funktionen und Daten mit einem Prä- oder Postfix zu kennzeichnen. Wenn der Prä- oder Postfix projektweit abgestimmt ist, dann
ist dies das Mittel der Namensraumvergabe.
In C++ hat man einiges für die Label-Namensräume getan: Die Labels werden hier nicht mehr aus den einfachen Bezeichnungen gebildet, sondern sind wesentliche länger. Bestandteile
des Labels ist der Klassenname, in deren Kontext eine Routine oder static Daten definiert wurden. Damit brauchen nur noch
die Klassen eindeutig gekennzeichnet sein. Um auch dort Konflikte zu vermeiden, hat man den namespace erfunden: Klassen werden einem benannten namespace zugeordnet, der ebenfalls Bestandteil des Labels ist. Damit braucht projektweit nur noch der namespace abgestimmt werden. Doch was ist, wenn man Quellen aus einem anderen Projekt übernimmt? Eine weltweit eindeutige Abstimmung
ist nicht angedacht (im Gegensatz dazu bei den Java-Packages schon).
Bestandteile des Labels von Methoden sind auch die Typen der Parameter. Damit sind die gleichnamigen aber parameter-unterschiedenen
Methoden möglich.
Letzlich enthält ein Label in C++ noch einige Einstellungen der Art des Aufrufes von Methoden. Damit wird verhindert, dass
Fehler entstehen, wenn verschiedene Module mit verschiedenen Compilierungsoptionen zusammengebunden werden, die an sich nicht
zusammenpassen. Das ist nicht vordergründig ein Problem des Namespaces, aber nutzbar: Man kann dem Linker verschieden compilierte
aber sonst inhaltsgleiche Objectfiles anbieten, er findet das passende.
Die somit gebildetete Labels sind unlesbar-lang, werden aber vom Linker ansonsten genauso wie in C verarbeitet. Man kann bei
Linkerfehlern auch die Labels selbst analysieren, zumindestens in Object- oder Libraryfiles textuell suchen.
Die Deklaration von Daten und Methoden in Headerfiles hat für Labels und Linken keine Bedeutung:
Die extern-Deklaration von Daten oder ein Funktionsprototyp in einem Headerfile erzeugt keine extern-Deklaration dieses Labels im Objectfile,
sondern dient der Überprüfung des Bezeichners beim Compilieren. Sonst würden viele deklarierte Bezeichner von includierten
Headerfiles mit nicht benötigten Bestandteilen den Objectcode aufblähen, tun sie aber nicht. Nicht benötigte Quellzeilen mit
Deklarationen beschäfttigen nur den Compiler mit Rechenzeit, hinterlassen sonst keine Spuren. Der Compiler prüft die Rechtmäßigkeit
eines Bezeichners mit der Deklaration. Ansonsten gilt die Regel: Nur ein irgendwo benötigter Bezeichner wird als extern im Objectfile eingetragen.
Bei der Compilierung ist ein Modul einem anderen zunächst nur als Schnittstelle über den Headerfile bekannt. Die tatsächliche
Verbindung schafft dann der Linker, indem die Aufrufadresse von Routinen oder die Speicheradresse von statischen Daten an
den Aufrufstellen eingetragen wird. Klassisch in C ist das sehr einfach. Maßgebend ist der Name der Routine/der Daten. Der
Linker sucht aufgrund des Vorkommens des Namens in einem beliebigen Object-Modul. Falls irgendwas mit diesem Namen gefunden
wird, dann ist es das. Damit sind aber Fehler möglich. Wenn ein vollkommen falscher oder etwas falscher Headerfile beim Compilieren
benutzt wurde, dann merkt dies der Linker nicht. Man hat dann Datensalat oder Abstürze, die schwer zu finden sind. Daher
wird in C++ das Linklabel nicht einfach aus dem Namen der Routine/der Daten gebildet, sondern enthält weitere Bestandteile.
An sich ist das ein Nebeneffekt der Tatsache, dass der einfache Routinenname sowieso nicht ausreicht, sondern mindestens noch
die zugehörige Klasse. Außerdem müssen Routinen mit verschiedenen Argumenttypen aber gleichem Namen als verschiedene Routinen
erkannt werden. Passen Headerfiles nicht zu Objectmodulen, dann hat man eine größere Chance, dies als Linkerfehler zu bemerken.
Bei der Compilierung werden Segmentnamen vergeben. Damit kann der Linker gleichartige Daten oder Maschinencode aus verschiedenen
Object-Modulen miteinander in einem Speicherbereich vereinen, andere Daten oder Maschinencodes dagegen in den dafür geeigneten
Speicherbereich bringen.
Einem C/C++-Programmierer für den PC begegnen die Segmentnamen nur, wenn er in Dialogboxen hineinschaut, die er meist nicht
braucht. So wie beispielsweise bei dem legendärem Visual-Studio 6 im Dialog
Die Headerfiles enthalten Deklarationen, die dem Compiler ermöglichen, die Richtigkeit einer Verwendung oder einer Definition
zu überprüfen. Damit stellen die Headerfiles für C und C++ die wesentlichsten Schnittstellen der Module dar.
In der Anfangszeit von C war eine Vorwärtsdeklaration von Methoden nicht unbedingt notwendig und wurde auch nicht praktiziert,
wenn eine Methode nur int-Parameter hatte. Jetzt noch ist eine fehlende Vorwärtsdeklaration in C nur eine Warning wert. In C++ ist eine fehlende Deklaration dann endlich ein Compilerfehler. Diese Herangehensweise - automatisch deklarieren
wenn benutzt - war in den Anfängen der Softwareentwicklung üblich: BASIC, PL1. Man wollte Schreibarbeit sparen und die Programme
waren noch zu überschauen.
Eine Verbindung der Module mittels statischem Linken ist möglich, auch wenn es grobe Fehler in den Headerfiles und bezüglich
deren Verwendung gibt. Der Linker arbeitet nicht auf Basis von Informationen in den Headerfiles, sondern kennt nur Labels.
In C kann nicht festgestellt werden, ob eine Subroutine mit einem bestimmten Namen (Label) korrekt aufgerufen wurde. In C++
gibt es diesbezüglich Verbesserungen. Hier werden die Label-Namen aus mehreren Eigenschaften der Definition der Methode oder
der Daten zusammengesetzt.
Nur die richtige Verwendung von Headerfiles sichert, dass der Linker nur Passendes zusammenbindet. Das geschieht aber dadurch,
dass der Compiler unter Kenntnis der Deklarationen nur zueinander passende Labels bildet.
3.3.1 Korrekte Formulierung und Nutzung von Headerfiles
Bezüglich der korrekten Formulierung und Nutzung von Headerfiles beziehungsweise Deklarationen werden häufig grobe Fehler
gemacht, die aber oft Programmierern nicht so auffallen oder nicht im Bewusstsein liegen. Solche Fehler sind:
Fehler: Deklaration des selben Elementes in verschiedenen Headerfiles oder in einem C-File direkt. Meist wird copy'nPaste
verwendet und die Deklarationen sind identisch. Dann ist nichts falsch. Aber bei Softwareänderungen können Deklarationen vergessen
werden zu korrigieren. Dann laufen die Deklarationen auseinander. Ein Fehler fällt oft nicht sofort funktional auf, sondern
dann wenn man beim End-Test ist.
Ursache für diesen Fehler:
Bequemlichkeit: Was benötigt wird ist sowieso bekannt und geklärt und muss nur aus formellen Compilergründen deklariert werden, also am einfachsten
direkt im C-File, selbst verständlich ganz ordentlich in einer extra Abteilung EXTERNALS. Das ist falsch.
Deklaration in einem Header, der bisher nicht eingezogen wurde und mit dem es anderen Ärger (Unverträglichkeit) gibt, also
wird die Deklaration in einen eigenen Header kopiert und schon ist sie zweimal vorhanden.
Richtig: Deklarationen dürfen nur genau einmal in nur einem Header vorhanden sein. Die Headerfiles müssen gut strukturiert
sein, damit ein Includieren nicht Nebenprobleme verursacht. Es muss eine klare Top-down-Ordnung für Header geben. Ansonsten
kann es Probleme mit zyklischen Includes geben. Ist das beachtet, dann ist das Includieren des benötigten Headers auch kein
Problem.
Richtig: Header müssen selbst diejenigen Header includieren, deren Deklarationen sie selbst benötigen. Test: compiliert man
einen Header allein (C-File nur mit dieser #include <test.h>-Zeile, dann muss das ohne Compilerfehler gehen. Das ist die bessere Methode gegenüber der, die Includes im C-File vorzuschreiben.
Sie funktioniert, wenn die Header Top-down organisiert sind.
Richtig: Jeder Header muss mit #ifndef __Name_h__ gegen doppeltes includieren des Inhaltes geschützt sein. Die Bezeichnungen dieses Defines der bedingten Compilierung darf
nicht in verschiedenen Headers dopelt auftreten.
Falsch: In Headerfiles werden Datenelemente definiert oder Routinen definiert. Der Fehler kommt gegebenenfalls auch dadurch
zustande, dass man eine Regel beachtet: Includiert werden dürfen nur Header. Diese unrichtige Regel führt dann dazu, dass man maschinencodebildende Bestandteile, die includiert werden sollen, etwa
wegen Variantenbildung, also in einen Headerfile schreibt.
Richtig: Man kann in einen C-File andere Files mit beliebigen Extensions includieren. Man kann auch andere C-Files includieren,
die dann freilich nicht nochmal compiliert werden dürfen. Günstig ist es, Files, die für das Includieren vorgesehen sind,
passend zu kommentieren oder kennzuzeichnen.
Insbesondere in C++ ist die Verwendung von Dynamic Link Libraries (dll) unter Windows beziehungsweise shared libraries unter UNIX bekannt. Das Konzept solcher Dynamischen Bibliotheken hat einige Vorteile. So kann eine Gesamt-Funktionalität mittels Bereitstellen verschiedener Teil-Bibliotheken als Files zur
Laufzeit variiert werden.
Java verwendet ausschließlich das Konzept des dynamischen Linkens. Alle Klassen sind in Jar-Files oder als einzel-class-Files
vorhanden und insoweit einzeln zusammenstellbar Sie werden geladen, wenn sie benötigt werden. Zur Laufzeit, vor dem Start
oder auch vom zuvor laufenden Programm selbst, kann ausgetauscht werden.
Die etwas höhere Aufrufzeit von Routinen, wenn deren Programmcode noch nicht geladen ist, wird teils von schnellen Filezugriffen
und schnellen Prozessoren wett gemacht. Für zeitkrirische Anwendungen kann aber der entsprechende Programmcode gleich zu Anfang
komplett geladen werden. Dann hat man immer noch den Vorteil der Zusammenstellbarkeit vor dem Programmstart.
Das Thema Kommunikationswege gehört genauso zur Verknüpfung der Module wie das statische und dynamische Linken.
Die Kommunikationswege bei gelinkten Modulen liegen im direkten Datenzugriff im gemeinsamen Speicherbereich (Adresse über
Label verlinkt), in der Tatsache des Aufrufes der richtigen Subroutine zum richtigen Zeitpunkt (das ist ein Event) und der
damit verbundenen Parameterübergabe im Stack. Daten können auch referenziert werden, wenn der Zeiger übergeben wird.
Auch bei direkt gelinkten Methoden, die also im selben Prozessraum ablaufen, ist eine Kommunikation beispielsweise über Socketverbindungen
möglich. Das ist dann zweckmäßig, wenn die Module diese Kommunikationsart sowieso enthalten weil aus anderen Gründen notwendig.
Man muss also nicht eine solche Kommunikation ausbauen, weil es im gleichen Prozessraum einer Applikation nicht notwendig
ist.
Einige Kommunikationsmechanismen sind auch dann einsetzbar, wenn Module räumlich getrennt sind. Der verbreitetste und damit
wichtigste Mechanismus ist hier die Socketkommunikation.
Andere Kommunikationswege sind oft betriebssystemspezifisch und werden gern in betriebssystemangelehnten Applikationen verwendet.
Darauf wird hier nicht weiter eingegangen.
Die genaue Ausprägung einer Kommunikationsverbindung (Protokolle, OSI-Schichten, Events, Remote Procedure Call usw. usf) sind
eigene Themen, die den Zweck dieser Darstellung sprengen. Wichtig ist: Das gehört auch zur Verbindung von Modulen.
Module benötigen häufig Daten. Es gibt Fälle, in denen ein Modul bei Aufruf etwas berechnet, dabei aber weder gespeicherte
Daten benötigt (Parameter) noch statisch vorhandene Daten (über den Aufruf hinweg) verändert. Damit wird ein Paradigma der
Funktionalen Programmierung erfüllt. Module sind aber oft so organisiert, dass sie sich selbst Daten merken, dass nachfolgend aufgerufene Methoden den
zuvor mit anderen Methodenaufruf eingestellten Zustand nutzen können. Das ist ein Paradigma der Objektorientierten Programmierung, was diesbezüglich der [Funktionalen Programmierung]] genau entgegengesetzt steht.
Wenn die notwendigen Daten zu einem Modul angelegt werden, dann entsteht eine Instanz des Moduls. Ein Modul als Ergebnis der
Softwareerstellung ist im Objektorientiertem Sinn als Klasse (class) aufzufassen.
Ein Modul kann sich demnach mehrfach instanziiert finden. Die einmalige Instanziierung wird als singleton bezeichnet und ist ein Sonderfall.
Statische Daten werden angegelegt, in dem in C oder C++ Daten direkt definiert werden:
int x;
int a = 0;
Type data = {0};
Die Daten können sowohl innerhalb einer Subroutine (C-Funktion) angelegt werden und sind dann nur dort sichtbar, dabei ist
das Schlüsselwort static zusätzlich erforderlich, oder die Daten können in einem C-File außerhalb von Funktions-Bodies angelegt werden. Das Beispiel
zeigt drei Varianten:
Anlage einer einfachen Variable ohne Initialiisierung,
Anlage einer einfachen Variable mit Initialisierung,
Anlage eines strukturierten Types mit Initialisierung.
Aus Sicht einer guten Softwaretechnologie ist nur der dritte Fall gut zu gebrauchen.
Insgesamt ist die Verwendung von statischen Instanzen differenziert zu bewerten:
Es handelt sich Objektorientiert um Singeltons. Damit werden Klassen bezeichnet, die nur einmalig instanziiert werden. Singletons sind in einer vielfältigen Softwareumgebung
nur eingeschränkt verwendbar. Gleiche Aufgaben parallel sind mit Singletons nicht zu realisieren. Singleton sind Objektorientiert
nur dann zu vertreten, wenn die Problemstellung singelton ist - nur eine einzige Instanziierung zulässt.
Anders ist es jedoch in C in der Verwendung in Embedded Systemen mit abgegrenztem Funktionsumfang. Hierbei geht es nicht um
Singletons als Software-Charakteristika, sondern schlichtweg darum, dass sowieso nur eine Instanz benötigt wird. Man denkt dabei nicht
über Singletons oder nicht nach, sondern instanziiert einfach.
Der Zufriff auf einzelne Daten aus einer statischen Instanz geschieht auf Maschinencodeebene direkt. Es ist die schnellste
Art, auf Daten zuzugreifen. Dabei macht es keinen Unterschied, ob es sich um einfache Variable handelt (hierbei ist es klar,
dass maschinentechnisch dessen vom Linker festgelegte konstante Adresse direkt benutzt wird) - oder ob es sich um ein Element
in einer Struktur handelt. Auch in diesem Fall berechnet der Compiler die direkte Adresse. Der Maschinencode ist also nicht
anders gestaltet als bei einem Zugriff auf eine einfache statische Variable.
Aus dem letzt dargestellten Sachverhalt ergibt sich die Aussage, dass es keinen Vorteil bringt, einzelne Variable statisch
zu definieren. Man kann besser zusammenhängende Daten in einer struct zusammenfassen und diese struct dann statisch instanziieren. Der Vorteil ist, dass die Zusammengehörigkeit von Daten in der Software klar definiert wird.
Das ist ein starker struktureller softwareentwurfstechnischer Vorteil.
Statisch instanziierte Daten können auch referenziert benutzt werden. Wenn ein anderes Softwaremodul also referenzierte Daten
eines bestimmten Types erwartet, dann kann diesen Subroutinen auch eine Referenz (Zeiger) auf diese Daten übergeben werden.
Eine statische Instanz erzeugt also keinerlei Nachteile für eine referenzierte Verwendung.
Folglich sollten statische Instanzen in zwei Fällen verwendet werden:
Objektorientiert, große universelle Software: Dann, wenn das Problem singleton ist.
Einfach in C, wenn klar ist, dass nur eine Instanz notwendig ist.
Instanzen solten statisch nur dann angesprochen werden, wenn diese Instanzen im Kontext bekannt sind (Singelton-Denkweise). Sind Gründe gegeben, dass mit mehreren Instanzen zu rechnen ist, oder wird der maschinentechnisch optimale Zugriff
nicht benötigt, dann sollten statisch angelegte Daten referenziert angesprochen werden. Also: Es wird nicht mit der statischen
Instanziierung gerechnet. Diese Module können die Daten dann sowohl statisch singleton, als auch multi-instanziiert verarbeiten.
Eine einfache in C populäre Herangehensweise ist die Anlage der Daten neben dem Programmcode eines Moduls im selben C-File:
int store;
int myRoutine(int value)
{ store += value; //kummuliert
return store;
}
Damit sind die Daten gleich mit angelegt, wenn das Modul vom Linker erfasst wird. Alles erledig.
Doch:
Die Verwendung von statischen Variablen innerhalb der Software eines Moduls verhindert eine mehrfache Instanziierung.
Die Daten liegen unstrukturiert flach, möglicherweise im Quellcode verteilt vor.
Die mehrfache Instanziierung mag für einige Anwendungen als nicht notwendig oder gar abwegig erscheinen. Es kommt aber auf
die Einsatzfälle an. Eine bestrittene Notwendigkeit der Mehrfachinstanziierung gilt nur für einen Zeitpunkt und gegebenfalls
nur als Meinung einer Personengruppe. Es zeigt sich in der Praxis häufig, dass die Gewohnheit der einfachen direkten Anlage
von Daten im Modul dann doch die Notwendigkeit der Mehrfachinstanziierung aus neuen Anforderungen resultierend, erschwert.
Auch aus dem zweiten oben genannten Grund sollten alle Daten eines Moduls grundsätzlich in einer gemeinsamen struct in C zusammengepackt werden. Wird diese struct dann statisch instanziiert und nicht referenziert benutzt, dann ergeben sich keinerlei Nachteile. Der maschinencodetechnische
Zugriff auf die Daten ist identisch mit dem Zugriff auf einzelne direkte Daten. Aber es ist mit wenig Umstellungsaufwand möglich,
eine Mehrfachinstanziierung zu realisieren.
Diese Regel der Bildung einer zusammenhängenden Datenstruktur pro Modul entspricht der Objektorientierten Programmierung.
Im Standard-C ist es recht einfach möglich zu notieren:
int myRoutine(int value)
{ static int store = 0;
store += value; //kummuliert
return store;
}
Diese Routine liefert bei Mehrfachinstanzierung des Moduls Ergebnisse, die von allen Modul-Instanzen abhängt. Jeder Aufruf
der Routine unabhängig von der Instanz benutzt den selben Speicherplatz. Zudem ist dieses Verhalten nach außen wenig dokumentiert.
Bitte vermeiden.
In Java sind statische Daten verwendbar, allerdings sind diese Daten im Verband der Klasse definiert und daher geordneter
auffindbar. Eine freie Definitionsmöglichkeit der Daten außerhalb von Klassen gibt es nicht. Die Problematik der nicht-Mehrfachindizierbarkeit
ist die selbe. Jedoch ist in Java die Verwendung von Klassendaten die gängige Programmierpraxis. Statische Daten sind der
fast höhere Aufwand. Die Notation beim Zugriff auf die Daten unterscheidet sich nicht (erkennt der Compiler selbständig),
lediglich das Schlüsselwort static ist zusäztlich erforderlich.
Die Daten einer Applikation sollten so organisiert werden, dass es eine Main-Instanz der Applikation gibt, die alle anderen
Daten entweder enthält (embedded) oder referenziert. Man kann auch die Daten der Module einzeln anlegen und so wie notwendig
miteinander referenzieren. Doch ist damit ein Überblick über die Daten schwerer möglich als bei einer hierarchischen Organisation
3.6.2.1 Struktur von Daten und deren direkte Instanziierung als Singleton
Die Instanziierung der MainData kann so erfolgen, dass diese statisch in einem C-Modul definiert wird. Es entsteht damit ein
Singelton, das entweder referenziert benutzt werden kann (dann ist für die Benutzung eine Anlage im Heap identisch), oder die Daten
werden an geeigneter Stelle direkt als der Singleton-Instanz angesprochen. Damit hat man die schenllste Variante bezüglich
der Verarbeitung im Maschinencode:
extern MainData mainData; //im Headerfile, von allen sichtbar.
mainData.data12 = 34; //direkter Speicherzugriff, ohne Adressarithmetik
MainData* pMain = &mainData; //Zeigerbildung
pMain->data12 = 34; //indizierter Zugriff, kaum länger.
In Java werden Daten grundsätzlich nur im Heap angelegt werden. Die erste Instanz einer Applikation wird in deren Main-Routine
angelegt:
class MainType {
public static void main(String[] args)
{ MainType main = new MainType();
main.execute();
}
...
}
Es geht genauso mit:
class MainType {
static MainType main = new MainType();
public static void main(String[] args)
{ main.execute();
}
...
}
Im zweiten Fall legt der ClassLoader beim Laden der Klasse die Daten im Heap an und speichert die Referenz dazu in der Variablen
main. Man kann einen Haltepunkt an diese Stelle oder in den Konstruktor setzen (Beispiel Eclipse-debugging), der Haltepunkt wird
erreicht bevor main(String[]) aufgerufen wird. Diese Programmierweise ist nicht so sehr üblich in Java, denn in diesem Fall kann die Main-Instanz nicht
mehr abhängig von den Aufrufparametern gebaut werden. Aber ansonsten wird das selbe Resultat erzeugt.
Auch wenn die übergeordnete Datenstruktur des Hauptzweiges nur als Singleton benötigt wird und dauerhaft angelegt bleiben
soll, kann sie im Heap dynamisch beim Hochlauf allokiert werden. Man braucht den Zeiger auf die Daten nirgends global ablegen,
sondern kann den Zeiger jeweils gerufenen Routinen oder anderen danach gestarteten Threads im Stack übergeben (Subroutinenparameter).
Das ist die pure nicht Globaldaten-Lösung. Allerdings ist es für Debugzwecke günstiger, den Zeiger zusätzlich statisch abzulegen.
Man kann dann im Debugger die Haupt.-Datenstruktur leichter finden. dies nur als Praktischer Tip.
Diese Referenz auf die Haupt-Daten soll als Firstlevel-Referenz bezeichnet werden. Man kann eine oder mehrere solcher Firstlevel-Referenzen haben. Klassenorientiert (C++, Java) lässt sich
eine solche Referenz als static-Member anlegen.
Man kann die Daten zu weiteren Modulen ebenfalls statisch anlegen. Dabei ist eine mehrfache Instanzzierung möglich, in dem
man mehrere Daten anlegt, die Module müssen dann diese Daten per Referenz ansprechen. Sind die Module als Singleton gedacht,
dann kann in den Modulen die Daten direkt verwendet werden, vermittels einer Deklaration:
Im Header für das Modul:
extern Modul_X modul_X_Data;
In einer Compilierungseinheit: Anlage der Daten:
Modul_X modul_X_Data;
In der Compilierungseinheit des Moduls:
modul_X_Data.element = 1234;
In diesem Fall ensteht optimaler Maschinencode, aber die Möglichkeit der Mehrfachinstanziierung ist verbaut. Man kann unter
Ausnutzung von defines aber beides haben. Das kann notwendig sein, wenn ein Modul in einer Applikation nur singelton aber
extrem optimal laufen soll, in einer anderen Anwendung dagegen multiinstanziiert. Beispiele: Zielplattform singleton und schnell,
Modultest am PC: Mehrere Module, die sich sonst auf verschiedenen Hardwareeineiten befinden, werden in einer Executable im
Zusammenspiel getestet:
In einem define, dass zielsystemabhängig verschieden ausgewählt wird, hier für die referenzierte Instanz:
#define modul_X (*modul_X_p)
oder für die direkt angesprochene Instanz:
#define modul_X modul_X_data
Die jeweils richtige Variante des Defines wird im Compiliervorgang ausgewählt.
Grundsätzlich sollte wenig mit Defines bzw. Makros gearbeitet werden. In diesem Fall ist es aber notwendig, daher berechtigt,
und einfach, daher zu erlauben.
Daten werden dann statisch instanziiert, wenn sie in Java als final static gekennzeichnet wurden und in der selben Zeile mit new initialisiert werden. Wenn diese Daten mit dem dort vergebenen Namen referenziert werden, dann wird ein statischer Zugriff
(unmittelbare Adressierung) ausgeführt.
Daten werden dann eingebettet in die Struktur der definierenden Klasse, wenn sie in Java als final gekennzeichnet wurden und in der selben Zeile mit new initialisiert werden.
3.6.3.3 Im Heap allokierte und referenzierte Daten
In klassischen C-Programmen für embedded Control ist die Anlage von Daten in einem Head (malloc) eher seltener. In C++-Programmen ist die Nutzung eines Heaps oft gängige Praxis, insbesondere bei Programmen auf dem PC,
bei denen von Haus aus ein entsprechend großer Heap bereitsteht. Der Heap ist der dynamisch allokierbare Speicher, der vom
Betriebssystem verwaltet auch für große Daten genutzt werden kann.
Es kommt also auf die Laufzeitumgebung und die Anforderungen an. Braucht man keine feste Speicherbindung und ist der Heap
genügend groß, kann es sinnvoll sein alle Daten im Heap anzulegen. Die Daten werden dann immer über Referenzen angesprochen.
Es gibt in C und C++ ein paar kleine Probleme zu beachten:
Freigabe des Speicherbereiches: Es gibt zwei Fehlerfälle:
Der Speicher wird freigegeben, obwohl die Referenz auf diesen Speicherbereich noch existiert, es erfolgt nach der Freigabe
noch ein Zugriff. Das kann schwere Störungen im Gesamtsystem verursachen, da der Speicherbereich bereits neu in anderer Größe
allokiert sein könnte. Insbesondere können die Strukturen der Heaporganisation überschrieben werden, dann crasht das gesamte
System.
b) Der Speicher wurde vergessen freizugeben. Dann gibt es bei langer Laufzeit ein Problem mit dem notwendigem Speicherbereich
einer Applikation.
Überschreiben des Speicherbereiches: Fehler in der Programmierung: Zeigerarithmetik, Indexüberlauf können die Speichergrenzen
verletzen. Dann gibt es zusätzlich das Problem, dass die Organisationsdaten des Heaps zerstört werden können. Abhilfe für
sicherheitskritische Programme kann eine Speichersegmentierung mit Schreibschutz sein.
Häufiges Allokieren und Deallokieren verschieden großer Speicherbereiche führt dazu, dass die genutzen Bereiche des Heaps
eher wie ein Flickenteppich aussehen (fragmentiert) und das möglicherweise irgendwann kein zusammenhängender Speicher der
erforderlichen Größe bereitgestellt werden kann, obwohl die Gesamtanzahl der freien Bytes genügend groß ist.
Man kann daher schon dahin tendieren, dass Heap-Bereich nicht für alle kleinen Speicheranforderungen benutzt werden sondern
nur für die großen Komplexe, die nur beim Hochlauf der Applikation angelegt werden müssen. Der Vorteil der Heap-Nutzung liegt
dann darin, dass die Speichergröße beim Anlauf der Applikation von den Anlaufparametern abhängen darf. Statisch angelegter
Speicher ist demgegenüber in seiner Größe zur Compilezeit festgelegt.
Java in der Standardausprägung der virtuellen Maschine (VM) auf einem PC benutzt Speicher grundsätzlich im Heap. Der referenzierte
Speicher ist das Grundkonzept von Java, da damit die größtmöglichste Flexibilität erreicht wird.
Die oben genannten C/C++-Heap-Probleme sind in Java wie folgt gelöst:
Falsche Speicherfreigabe: In Java braucht man die Freigabe nicht selbst zu programmieren. Ein Garbage Collector der Java-Organisation (in der VM) testet im Hintergrund oder bei Speicheranforderungen, ob auf die allokierten Bereiche noch
Referenzen bestehen. Die Freigabe erfolgt dann, wenn keine Referenzen mehr vorhanden sind. Damit ist gegenüber diesem Thema
eine Sicherheit garantiert. Allerdings kann eine Anwendung noch Speicher referenzieren, obwohl die Referenz im weiteren Ablauf
nicht mehr benötigt wird. Dann geht auch bei Java der Speicher aus. Man sollte Referenzen nicht stehenlassen sondern mit null belegen.
Überschreiben des Speicherbereiches: Ist bei Java daher nicht möglich, weil es keine Zeigerarithmetik gibt und indizierte
Zugriffe geprüft werden.
Fragmentierung des Speichers: Da die virtuelle Maschine die Referenzen auf die Speicher kennt, ist es möglich, die Abarbeitung
für eine notwendige Zeit (Millisekunden, kann auch mal Sekunden sein) anzuhalten und den Speicher neu zu organisieren. Damit
ist dieses Problem auch gelöst.
Die Speicherverwaltung in Java ist also sicher gestaltbar. Insbesondere wegen der Defragmentierung ist allerdings die Abarbeitungszeit
nicht garantiert (kein Realtime). Für die typischen Anwendungen der Serverorientierten Architektur ist eine Pause von bis
zu einer Sekunde wegen Defragmentierung nicht kritisch, da das im Bereich verträglicher Antwortzeiten liegt. Ansonsten ist
Java sehr schnell und kann damit den hohen Datendurchsatz bewältigen. Aber für schnelle Echtzeitverarbeitung geht das nicht.
Abhilfe: Es gibt Real-Time-Java-Versionen mit besonderen Mechanismen.
Bei Nutzung von Java2C insbesondere für Realtimeanwendungen wird das Problem der Echtzeitanforderung und Heap wie folgt gelöst:
Es gibt die Möglichkeit, mit statischen oder embedded Instanzen zu arbeiten, bei entsprechender Formulierung im Java-Quellcode.
Die Java-Abarbeitung verwendet also Heap-Speicher, wogegen in der nach C übersetzen Variante statischer oder embedded Speicher
verwendet wird.
Im Java2C-Laufzeitsystem gibt es einen sogenannten BlockHeap, ein Heap, der gleichgroße Blöcke verwaltet. Das ist für Instanzen gedacht, die auch in Realtime-Anwendungen dynamisch allokiert
werden müssen, aber typischerweise dort einen begrenzten Speicherumfang haben. Das sind etwa Event-Daten, aufbereitete Zeichenketten
für Logmeldungen und dergleichen. Dieser Blockheap wird mit einem Garbage-Collector verwaltet. Allerdings kann dieser Garbage-Collector
unterbrochen werden, blockiert also nicht die CPU. Belegte Blöcke werden nicht verändert.
Speicherüberschreiber: Sind immer nicht entdeckte Softwarefehler. Wenn man ein Programm in Java unter möglichst vielen Bedingungen
vortestet, dann werden diese Softwarefehler dort auffallen und korrigiert werden. Die nach C übersetzten Files führen automatisch
keine Indexüberwachung bei Arrayzugriffen aus. Zeigerarithmetikfehler sind deshalb ausgeschlossen, da aus Java heraus solche
nicht programmiert werden, außer in bestimmten ausgetesteten Bedingungen. Hier gilt ebenfalls, dass beispielsweise ein Casting
auf einen abgeleiteten Typ beim Test in Java bereits entdeckt werden sollte und daher im C-Programm korrigiert ist. Instanztyptests
werden auch in C ausgeführt und können die Sicherheit der Programmierung erheblich erhöhen.
Wird eine Composition- oder Aggregation-Beziehung von Modulen über Interfaces benutzt, dann ist der entscheidende Schritt
der Composition der der Instanziierung. Zu einem Interface können verschiedene Modul-Typen bzw. Klassen instanziiert werden,
abhängig von Konfigurationen oder auch verschiedene an unterschiedlichen Stellen. Damit wird eine höhere Flexibilität erreicht
als beim statischen oder dynamischen Binden. Ersteres ist eine Grundlage, die Instanziierung baut darauf auf.
Es gibt nun mehrere Möglichkeiten der Instanziierung:
Instanziierung notwendiger Module im Modul selbst (UML-Composition): Damit muss das Modul seine genutzten Module kennen. Es ergibt sich kein Vorteil zum dynamischen Binden.
Instanziierung notwendiger Module außerhalb. Das Prinzip wird auch als Dependency Injection bezeichnet. Hierbei gibt es sozusagen ein übergeordnetes Modul, dass alle Instanziierungen vornimmt.
Zuordnung von Modul-Verknüpfungen (UML-Aggregations) von außen: Hier setzt der Erbauer / Builder eines Systems die Aggregationen, die in diesem Fall für sichtbar (nicht private oder protected) oder setzbar über Setits...-Methoden sein müssen.
Abfrage der Instanzen für Modul-Verknüpfungen (UML-Aggregations) nach außen und Setzen innen: Hier muss jemand vorhanden sein, der gefragt werden kann und alle Module des Systems kennt.
Die Aktivität kommt aus einem Modul heraus, dieses weiß genau, was es setzen soll, nur nicht womit. Derjenige, der alle Module kennt, kann der Builder sein, oder ein als Broker bezeichenbare Instanz oder Schnittstelle.
Module müssen andere Module kennen, um Daten auszutauschen. In einem Embedded System sind solche Modul-Verbindungen oft stabil. Die Module und deren Verbindungen werden beim Startup festgelegt und bleiben dann
fest. In diesem Sinne sind die Modulverbindungen als Aggregationen nach der UML-Denkweise zu bezeichnen. Mehrere Module sind gemeinsam zu einem gesamten Aggregat verbunden. Ein Modul kann
nicht arbeiten, wenn nicht das andere Modul etwas bereitstellt/entgegennimmt.
Es scheint, dass hiermit ein großer Komplex von in sich verzahnten Modulen entstehen könnte. Das soll nicht sein. In einer
UML-Darstellung (Klassendiagramm) kann sehr genau aufgezeigt werden, wer wen und auf welche Weise kennt. Module, die in einem
Prozessraum zusammengebunden sind und statisch über dynamisch gelinkt sind, kennen sich nur bezüglich der globalen Labels.
Das können auch wenige sein. Globalität beißt sich oft mit Mehrfachinstanziierung und Wiedereintrittsfähigkeit. Die statisch
gelinkte Adresse auf Daten zielt auf globale Daten.
Damit sind die Referenzen zwischen Modulen ein gleichrangiges Thema neben dem Linken und den Schnittstellendeklarationen in
Headerfiles oder Interface-classfiles.
Bei Aggregationsbeziehungen muss der Nutzer nicht alle Details des genutzten Moduls kennen. Es genügt die Kenntnis der Schnittstellen.
Diesbezüglich gibt es in C, in C++ oder in Java sehr verschiedene Konzepte. Die Reduzierung der Aggregationsbeziehungen auf
Schnittstellen ist ein ganz wesentliches Mittel, um Softwareteile (Module) unabhängig bearbeiten zu können.
3.8.1.1 Headerfiles, Funktionsprototypen und Vorwärtsdeklarierte Zeigertypen in C
Im klassischem C gibt es die Headerfiles als Schnittstellendefinition zu anderen Modulen:
Funktionsprototypen definieren eine aufrufbare Subroutine mit ihrem Namen, Parameter und Returnwert, ohne die Implementierung
der Routine mit einzubeziehen. Die Implementierung kann unabhängig geändert werden. Nach Änderungen gibt es keine Auswirkungen
auf den Aufrufer (solange die Schnittstelle nach außen unverändert bleibt).
Referenzierte Datenstrukturen können mit einer Vorwärtsdeklaration als Zeigertyp angegeben werden, ohne dass die tatsächliche Datenstruktur dem Nutzer bekannt sein muss. Es ist also auch diesbezügliche
eine Änderung in einem anderen Modul ohne Auswirkungen auf das nutzende Modul möglich. Dieser Vorteil entfällt bei embedded
Strukturen, aber auch nur wegen der Kenntnis der Gesamtgröße einer eingebetteten Struktur. Wird eine embedded Struktur ebenfalls
über Referenzen den Subroutinen des anderen Moduls übergeben, bewirkt eine Strukturänderung ohne Längenänderung keine Änderung
am Maschinencode des nutzenden Moduls.
Die Verwendung von vorwärtsdeklarierten Zeigern sein an folgendem Beispiel demonstriert:
Header der Schnittstelle zu Modul_B:
Der Bezeichner einer struct eines genutzten Moduls wird deklariert, damit der Compiler diesen kennt.
struct Modul_B_t;
Die Definition der Funktionsprototypen, also die Deklaration der Funktionen (Subroutinen) stehen im Header des Modul_B.h,
der beim Compilieren des Modul_A mit eingezogen wird. Hier ist nicht die Kennnis des Aufbau der struct des Modul_B notwendig.
Das Modul_B wird angelegt, die Instanziierung ist im Modul_B programmiert. Zurückgegeben wird nur der Zeiger. Der Aufbau der
struct Modul_B braucht hier nicht bekannt zu sein.
ownData.myModulB = initModulB(...);
Auf das Modul_B wird zugegriffen. Dazu wird einer Subroutine aus Modul_B die bekannte Referenz auf dessen Daten übergeben.
Auch hier braucht der Aufbau der Daten beim Aufrufer nicht bekannt zu sein:
executeSomethingOfModul_B(ownData.myModulB);
Interner header des Modul_B:
Im Modul_B wird dessen Datenstruktur nun definiert, diese Definition ist nur für die Compilierung des Modul_B notwendig.Sie
kann sich im C-Quelltext befinden, kann aber auch in einem privatem Header angeordnet werden. Der Header, der die Funktionsprototypen
enthält, wird vorher eingezogen.
typedef struct Modul_B_t
{ int x,y;
}Modul_B_s;
Die Definition der Subroutinen selbst ist nun mit dem Bezeichner des typedef ausgeführt. Damit ist gekennzeichnet, dass Internas des Typs nun verwendet werden. Der Compiler erkennt die Richtigkeit der
Zuordnung struct Modul_B_t (die Struct-Tagdefinition) zu der Modul_B_s, der Typdefinition, da er zuvor diese Typdefinition compiliert hat. Es erfolgt also ohne Fehlermeldung, aber mit Check der
Korrektheit, die Compilierung der Subroutinen:
Im Modul wird beispielsweise eine Singletoninstanz statisch angelegt und verwendet. Rückgegeben wird aber der Zeiger darauf.
Damit ist die Frage ob statisch oder nicht nach außen gekapselt. Eine Änderung ist rückwirkungsfrei auf den Nutzer möglich.
Bei der folgenden Routine übergibt der Nutzer die Referenz, da er nichts von der Singeton-Eigenschaft weiß. Nur die derzeitige
Implementierung verwendet Singleton, eine Erweiterung ist ohne Rückwirkung möglich, Wegen dem Singleton wird also in der derzeitigen
Implementierung die Referenz ignoriert.
Regel: Schnittstellen sollten so definiert sein, dass bei einer absehbaren Erweiterung nicht die bisherigen Schnittstellen geändert
werden müssen. Also ist die Verwendung einer Referenz auf ein Modul gerechtfertigt, auch wenn es derzeit nur als Singleton realisiert werden
muss.
Als Beispiel sei noch eine Implementierung gezeigt, die nicht mit Anlage der Daten im Heap arbeitet (weil das Beispiel klassisch
embedded bleiben soll), aber die Referenzen benötigt:
In C++ ist es einfach möglich, objektorientiert zu programmieren. In der Objektorientierung gibt es die Interfaces, wie sie in Java direkt als eigenes Sprachmittel vorliegen. In C++ sind solche Interfaces genauso realisierbar, als ausschließlich
abstrakte Klasse:
Das Interface enthält also ähnliche Informationen wie die Funktionsprototypen in C. Die Eigenschaft der Vorwärtsdeklarierung
wird hier nicht weiter genutzt, da die Interface-class-Definition vom Nutzer sichtbar ist.
Damit hat der Nutzer alle Informationen, wie er das Modul_B kennen soll: Referenz und zwei Methoden. Er kann diese anwenden:
Die Implementierung im Modul_B sieht dann wie folgt aus:
#include "Modul_B_ifc.h"
class Modul_B: public Modul_B_ifc
{
static Modul_B_ifc* initModulB(...);
void executeSomethingOfModul_B();
};
Modul_B_ifc* Modul_B::initModulB(...){
Modul_B* data = new Modul_B();
data->x = 25;
return data; //auto cast to interface type.
}
void Modul_B::executeSomethingOfModul_B(){
data->xy = ...
}
Das Beispiel ist adäquat zu dem C-Beispiel adäquat gehalten. Für die Gestaltung des Quellcodes gibt es einige Syntaxunterschiede.
Funktionell ist aber eine Ähnlichkeit vorhanden.
Die Abarbeitung geht aber gänzlich andere Wege:
Mit dem hier gezeigten Interfacekonzept ist eine Nutzung des Interfaces nicht nur als Interface zu Modul_B möglich, sondern auch zu anderen Modulen, die ein gleiches Interface haben. Im C-Beispiel bezieht sich die Definition der
Funktionsprototypen ausschließlich auf das Modul_B. C++ kann also hier mehr. Das Grundkonzept der Objektorientierung, Polymorphie, wird unterstützt.
Wegen der Polymorphie ist der Aufruf myModulB->executeSomethingOfModul_B(); nicht unbedingt auf die implementierte Methode Modul_B::executeSomethingOfModul_B() bezogen, sondern auf diejenige Methode, die zur implementierenden Klasse gehört. Ein Modul_B2 kann das selbe Interface benutzen und eine adäquate Methode bereitstellen. Da die Information, von welchem Typ die per Interface
referenzierte Instanz ist, nicht bei der Compilierung des Modul_A bekannt ist, kann er nur zur Laufzeit ermittelt werden. Das ist die Zeile
myModulB = Modul_B::initModulB(...);
Hier wird an einer Stelle das Modul_B explizit erwähnt. Das ist meist in der Hochlaufphase. Weitergegeben wird dann nur die Referenz auf das Interface. Die Information
um welchen Typ der Instanz es sich handelt, ist also beim Compilieren weg. Es gibt noch komplexere Mittel der Instanziierung,
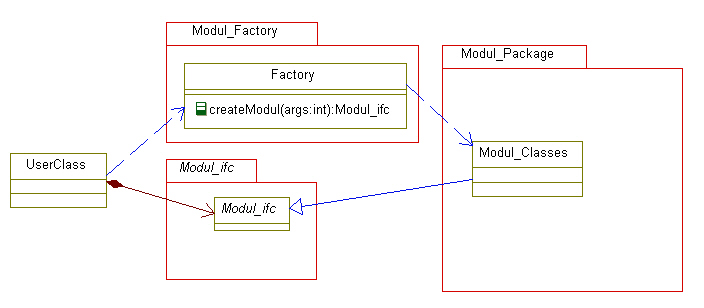
Factory-Pattern, bei dem die tatsächliche Instanz nochmals gekapselt ist.
Die letzliche Instanz steht aber in den Daten, neben den weiteren Daten als Zeiger auf eine sogenannte virtuelle Tabelle (vtbl). Über diese Tabelle werden als Sprungleiste die richtigen Methoden gerufen.
Damit wird bei Aufruf einer Methode immer ein indirekter Aufruf ausgeführt (über Dateninhalte). Es kann nun passieren, dass
ein solcher Aufruf auf einer falschen Adresse landet. Das passiert wenn die Daten wegen einem Softwarefehler unzulässig gestört
sind. In C kann das nie passieren, wenn niemand den Maschinencode überschreibt (einfacher Speicher-Schreibschutz genügt).
Der Mechanismus über die virtuelle Tabelle ist also nicht genügend sicher für einige Anwendungen.
Man kann in C++ grundsätzlich auch so wie in C arbeiten, also die sichere aber weniger flexible Methode wählen.
Etwas mehr Klarheit bei der Klassendefinition (mehr als ein Doppelpunkt: implements. Der Implementierungscode steht in der class, kein extra Headerfile.
class Modul_B implements Modul_B_ifc
{
static Modul_B_ifc* initModulB(...){
Modul_B* data = new Modul_B();
data->x = 25;
return data; //auto cast to interface type.
}
void executeSomethingOfModul_B(){
data->xy = ...
}
};
Die Möglichkeit des direkten Aufrufes ohne Interface gibt es in Java nur, wenn das genutzte Modul_B vor der Compilierung des nutzenden Modul_A bereits compiliert vorliegt. Es muss also im Quelltext fertig sein. Damit entsteht eine direkte Abhängigkeit. Wird Modul_B geändert, dann sollte Modul_A auch re-compiliert werden. In C ist das nicht nötig, da die Headerfiles sich nicht geändert haben (nur neu Linken ist notwendig).
Bei Nutzung eines Interfaces in C++ oder Java ist das auch nicht nötig, da das Interface sich nicht geändert hat.
Die Probleme mit den virtuellen Tabellen und einem möglichen Absturz gibt es insofern nicht, als Java wegen der Prüfmöglichkeiten
der Virtuellen Maschine diesbezüglich immer sauber arbeitet (sofern die VM fehlerfrei ist). Man kann also in Java bedenkenlos
mit den Interfaces arbeiten.
3.8.1.4 Java2C: Interfaces aus Java, aber möglicher Direkt-Aufruf
Bei der Konvertierung von Java nach C ist folgender Weg gegangen:
Die Interfacetechnik mit ihren virtuellen Methoden ist auf Funktionszeigertabellen (Sprungleiste) und einen indirekten Funktionsaufruf abgebildet. Den notwendigen C-Code erzeugt der Java2C-Translator. Der Anwender muss
nichts tun und kann diesbezüglich auch keine Fehler tun.
Wegen dem Problem der Zerstörbarkeit des Zeigers zur Funktionszeigertabelle ist eine zweimalige Sicherheitsabfrage eingebaut:
Der Zeiger auf die Funktionszeigertabellen steht in den Reflection-Informationen im const-Bereich (schreibschützbar). Aber
der Zeiger auf die Reflection steht in den Daten und ist demnach sensibel. Aber bei der Ermittlung beider Zeiger wird getestet,
ob der erste Zeiger grundsätzlich auf Reflection-Informationen zeigt. Der Zeiger auf die Funktionszeiger wird dann auf Signifikanz
getestet. Die Ermittlung eines Zeigers auf den richtigen Interfacebereich dauert dabei etwas länger (kleine Suchschleife).
Damit ist dieser Zugriff wohl hinreichend sicher, aber etwas langsamer. Ein einmal ermittelter Zeiger nur im Stack gespeichert
wird als sicher bezeichnet und daher nicht vor jedem Zugriff nochmals geprüft. Die Folgezugriffe damit sind also schnell, auch bei sehr hohen
Echtzeitanforderungen.
In embedded-Routinen wird ein dynamischer Aufruf (Polymorphie) weniger häufig benötigt. Aber der Entwurf der Software sollte
wegen der Unabhängigkeit der Module über Interfaces erfolgen. Wenn die implementierende Instanz aber bekannt ist, dann kann
sie in Java in einem speziellen Comment-Tag angegeben werden. Der Java2C-Translator erzeugt dann keinen indirekten Aufruf
auf die virtuelle Methode, sondern statt dessen den direkten Aufruf. Damit greifen die in C üblichen Mittel der Prototypendeklaration
und Zeigertypdeklaration. Man kann also so wie in C implementieren und dennoch mit Interfaces entwerfen.
3.8.2 Möglichkeiten der Verknüpfung von Modulen mit Aggregationsbeziehungen
Module arbeiten mit anderen Modulen zusammen. Dies trifft nur nicht zu für Module, die die letzlichen Blätter an dem Gesamtbaum
der Funktionalität darstellen, also einfache unabhängige Funktionalitäten. Es trifft auch zu für Monstermodule, die alles
enthalten also keine anderen Module brauchen. Diese sollte man aber nicht bauen.
Der Unterschied zwischen einer Aggregation und einer Komposition:
Ein Aggregat ist etwas, was ein Modul benötigt, was in einer festen Beziehung von vornherein in einem Modul bekannt sein muss
(vorhanden) und nicht ausgetauscht wird, was aber unabhängig vom Modul gebaut wurde.
Ein Composite ist auch etwas, was ein Modul benötigt. Es wird aber mit diesem Modul angelegt.
Ein Composite könnte also eher aufgelöst werden und im nutzenden Modul verschwimmen. Der Grund,ein extra Submodul zu bauen,
ist zunächst eine gewisse und prinzipielle Strukturierung in Module. Es gibt aber noch einen anderen Grund:
Was dem einen sein Composite ist, ist dem andern sein Aggregate.
Oft ist es so, dass ein Modul mit einem anderen Modul zusammenarbeitet, aber eigentlich dort nur einen Teilaspekt benötigt.
Hat man diesen Teilaspekt als Composite ausgeführt, dann verringert sich die Abhängigkeit: Man muss also nicht ein recht großes
Modul kennen, sondern nur eine kleinere Teilfunktionaltität, dessen Submodul oder eben nur dieses Submodul, egal wo es angeordnet
ist.
Jetzt ist es recht beliebig, ob ein Submodul irgendwo als Composite angelegt wird, oder woanders als Composite, oder auf der
Hauptebene, dann wirklich als Composite weil, einer muss es ja anlegen. Wo das Modul Composite ist, ist also aus anderen Aspekten
heraus zu beantworten als nur dem der Modulstruktur. Möglicherweise gilt die Regel: Wer's zu erst bei sich angelegt hat, hat's
halt. Möglicherweise sind da auch Bearbeiter-Zuordnungen maßgeblicher als es einem Softwareingenieur lieb wäre. Man kann auch
ein Composite umordnen, wenn es notwendig ist.
Es ist günstig, sowohl Aggregationen als auch Kompositionen in Java als final - Referenz zu programmieren.
Dieses final trägt einen Symbolgehalt zur Doku, es zeigt dass es entweder eine Aggregation oder Komposition ist und eben keine
beliebig änderbare Assoziation.
final vermeidet es Programmierfehler, die versehentliche Neubelegung.
final sagt dem weiterführendem Programmierer, dass er nur im Konstruktor nachzuschauen braucht, wie die Referenz belegt wurde.
Sie kann sonst nirgends anders belegt werden.
Das sind also alles nur Vorteile die es zu nutzen gilt.
Andererseits zwingt final zur Belegung im Konstruktor.
Ein wichtiger und manchmal lästiger Aspekt ist die Reihenfolge der Instanziierung.Wenn ein Modul ein anderes als Aggregat
braucht, dann muss das andere Modul zuvor schon instanziiert worden sein, wenn es im final referenziert und also die Referenz
im Konstruktor belegt werden soll. Sonst geht das mit dem final nicht.
Andererseits ist aus anderen Gründen eine Reihenfolge der Instanziierung vollkommen egal. Die Reihenfolge ist also nur von
den Abhängigkeiten bestimmt. Man kann die Reihenfolge drehen, wenn bemerkt wird, dass sie nicht stimmt. Hier hilft der Java-Compiler,
um Fehler aufzudecken:
Wenn im Konstruktor eine final- Referenz benutzt wird, die aber noch nicht belegt wurde, dann meldet der Java-Compiler einen
Fehler. Das funktioniert aber nur bei final-Referenzen, weil nur bei diesen der Compiler dies feststellen kann. Man kann also Zeilen im Konstruktor solange tauschen,
bis keine Fehlermeldungen mehr vorhanden sind. Die Fehlermeldungen deuten jeweils auf die benötigten aber noch nicht instanziierten
Module hin.
Es ist außen am Modul nicht erkennbar, welche Interfaces dieses Modul bereitstellt. Statt dessen werden Interface-Referenzen
intern bereitgestellt, ohne dass an einer Stelle bekannt ist welche.
Im einem Modul innen wird die Instanz bestimmt, mit der eine Aggregation vorgenommen werden soll. Damit muss aber das Modul
Kenntnisse von der Außenwelt besitzen. Die Flexibilität wird vermindert, wenn beispielsweise in einem Testfall eine Zuordnung
geändert werden soll.
4 Präsentation von Software in Libraries
Topic:Programming.ModulStructure.Libs
Eine Library ist ein File, der Software bestimmter Funktionalität enthält. In der klassischen C-Programmierung ist eine Library
eine Zusammenstellung von an sich unabhängigen Objectfiles, die als Ergebnis der Compilierung von Quellen entstanden sind.
In Java ist eine Library eine Zusammenstellung von class-Files, ebenfalls als Ergebnis der Compilierung. Eine Library wird
oft auch als Archiv bezeichnet, was sich an der File-Extension bemerkbar ist (.a für Libraries der GNU-Compilierung, .jar ist ein Java ARchiv.
Eine Library verbirgt den Quelltext. Der Quelltext ist in der Library selbst nicht mehr präsent. Allerdings enthält eine Library
alle global notwendigen Bezeichner (Identifier) aus dem ursprünglichen Quelltext. Damit ist eine Rekonstruktion des Inhaltes mindestens etwas erleichtertert. Java-class-Files
lassen sich formal in einen Java-Quellcode zurückübersetzen, adäquat wie Maschinencode zu Assembler. Allerdings fehlen Kommentare,
einige Konstrukte können in der Rückübersetzung mehrdeutig dargestellt werden.
Eine Library kann dynamisch verwendet werden. Der statische Fall liegt vor, wenn der Linker Objectfiles aus der Library fest in eine Executable einbindet.
Dabei werden immer nur die notwendigen Object-Bestandteile, nie prinzipiell die gesamte Library eingebunden. Eine Library
kann also sehr groß sein und bestimmt damit nicht, dass auch die Executable groß sein muss.
Dynamisch wird eine Library verwendet, wenn Bestandteile erst beim Ablauf, und dann erst wenn notwendig geladen werden. Das
bedingt das Vorhandensein eines Loaders. In Windows sind die DLLs üblich. In Java werden alle class-Files dynamisch geladen.
Man kann das Laden in der Startphase oder in einer Ruhephase ausführen, in dem man den ClassLoader anspricht oder inital eine
Methode der jeweiligen Klasse aufruft. Dann geht es beim ersten Aufruf schneller.
Das dynamische Laden ermögllicht den Austausch der Library vor dem Start ohne einen neuen Generierprozess zu erfordern. Ein
zweiter Aspekt des dynamischen Ladens ist die Verwendung des selben Codes von verschiedenen Applikationen (Code sharing).
Statisch gebunden ist ein Code in der Applikation fest verankert, und in einer anderen gegebenenfalls gleichzeitig ablaufenden
Applikation ebenfalls, damit doppelt im Speicher vorhanden. Ein dynamisch geladener Code kann von mehreren Applikationen verwendet
werden, wenn der Lader dies unterstüzt. Allerdings gibt es gegebenfalls das Problem von Versionskonflikten.
4.1 Der Zuschnitt von Libraries
Topic:Programming.ModulStructure.Libs.lib_spec
Libraries sind zunächst nur eine Ansammlung verschiedener unabhängiger Ergebnisse von Compilierungseinheiten (Objectfiles, class-Files). Diese Teile müssen nicht in irgendeinen Zusammenhang stehen. Die Rolle von Libraries, sich als
etwas Ganzheitliches zu repräsentieren, ist nicht formeller Natur sondern vom inhaltlichen Zusammenhang der zusammengebundenen
Files bestimmt. Man kann also auch Libraries bilden ohne wirklichen inhaltlichen Zusammenhang. Meist werden Libraries jedoch
als ein Modul oder eine Softwareschicht verstanden., die in dieser Form der Anwendung repräsentiert wird.
4.2 Zusammenhang zwischen Libraries, Quellen und Makefiles
Häufig werden die Quellfiles und die zugehörigen Make-Files zusammengefasst und als Quellen einer bestimmten Library aufgefasst.
In einer unifizierten Umgebung wie beispielsweise als Bestandteil eines Betriebssystems wie UNIX oder LINUX ist das oft praktisch.
Man kann Software entweder per Quelltext verteilen und einziehen, in dem man die Libraries selbst compiliert und dann verwendet,
oder man kann Binärcode, nur die Library einziehen, wobei Headerfiles dazu passen müssen. Der Weg über den Quelltext hat den Vorteil der Anpassbarkeit
von Details, beispielsweise abgeänderten Strukturdefinitionen für Schnittstellen.
In einer Embedded-Controll-Umgebung muss der Zusammenhang von Quellen und Libraries aber etwas modifiziert gesehen werden:
Quellen sollen möglicherweise wiederverwendet werden. Das kann bedeuten, verschiedene Embedded-Controll-Plattformen oder verschiedene
Applikationen sollen die selben Quellen verwenden.
Oftmals soll die Funktionalität, die in Libraries embedded eingesetzt werden soll, auf einem PC getestet werden. Dabei wird
die korrekte Funktionalität der Quellen getestet.
Damit ist der Zusammenhang Quelle - Makefiles- Library nicht mehr ein direkter. Quellen sind eigenständig, können und sollen
in verschiedenen Zusammenstellungen verwendet werden. Die Makefiles gehören jedoch zur Library oder zu einer Applikation.
4.3 Zuschnitt von ähnlichen Libraries für verschiedene Anwendungen
Topic:Programming.ModulStructure.Libs.SpecialSrc
Libraries für verschiedene Zielsysteme und Anwendungen sollten dennoch den gleichen Zuschnitt der Funktionalitäten aufweisen,
wenn sie für einem adäquaten Kontext angeboten werden. Dies ist zwar nicht grundsätzlich technisch erforderlich, erleichtert
aber die Anwendung. Günstig ist es, genau die selben Schnittstellen, sprich Subroutinen auf Maschinenebene oder interfaceimplementierende
Klassen etwa für Java-Archive zu haben. Das bedeutet aber nicht, dass alle Implementierungen identisch sein müssen, sprich
aus den selben Quellen gebildet werden.
Die meisten Funktionalitäten sollten aus den selben Quellen gebildet werden. Dann ist der Test der Software auf Quellbasis
für ein Zielsystem oft schon ausreichend für den Test der Quellen an sich und deren Anwendung in einer Library. Jedoch können
Unterschiede notwendig sein. Beispielsweise kann in einem Zielsystem eine Fehlermeldung für Debugzwecke einfach mit printf(...) ausgegeben werden. Ein anderes Zielsystem verfügt aber über keinerlei Monitor, daher kann diese Debug-Fehlermeldung dort
statt dessen in einen bestimmten Puffer im RAM abgelegt werden, der anderweitig kontrolliert wird.
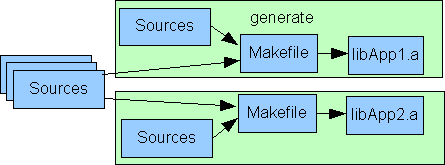
Das Bild soll solche Verhältnisse andeuten: Die meisten Sources werden aus einem einheitlichem Quell-Pool entnommen. Bestimmte,
meist wenige Sources gehören jedoch zu der Implementierungsplattform und daher zum Source-Pool der Library-Bildung zusammen
mit den Makefiles. Diese Pools sind wichtig für eine Source-Konfigurations- und Versionsverwaltung.
5 Abhängigkeiten
Topic:Programming.ModulStructure.Dependencies
Die Beachtung von Abhängigkeiten in der Software sind ein wichtiges Thema der Softwarepfege, oft unterschätzt. Intuitiv erstellte
Software ohne Abhängigkeitsprüfung und Diskussion läuft zunächst nach einer gewissen Inbetriebnahmephase, doch bei Änderungen
an der einen Stelle gibt es oft unerwartete Nebeneffekte... Software, bei der Abhängigkeiten richtig designed sind, kann man
an einer Stelle korrigieren, und hat entweder keine Nebenwirkungen, oder Korrekturen an allen ähnlichen betreffenden Stellen
gratis mit, bevor dort Fehler überhaupt auffalllen.
Die formalen Abhängigkeiten sind sichtbar als Meldungen beim Compilieren, Linken oder Ablauf, wenn man bestimmte Variationen
der Bedinungen vornimmt. Formale Abhängigkeiten werden dann nicht entdeckt, wenn alle Quellen und Libraries einer komplexen
Applikation vorliegen. Die formalen Abhängigkeiten fallen erst dann auf, wenn beispielsweise ein Einzeltest eines bestimmten
Moduls ausgeführt wird und dazu nur die Dinge bereitgestellt werden, die für dieses Modul vermeintlich notwendig sind. Das
sollten jeweils möglichst wenige sein, da jedes Moduls nur jeweils deterministische Abhängigkeiten aufweisen sollte.
Wird bereits bei der Compilierung festgestellt, das Headerfiles fehlen, mit denen man an dieser Stelle nicht gerechnet hat,
dann liegen nicht erwartete Abhängigkeiten vor. Möglicherweise werden Header aber nur unnötigerweise includiert, es liegen
also nur formelle und keine tatsächlichen Abhängigkeiten vor.
Ähnlich ist es mit Libraries oder anderen Modulen, die zur Runtime vorliegen müssen. Wenn in einem toten Code Subroutinen
gerufen werden, dann muss ein Linker diese formell finden, tatsächlich werden sie aber nicht benötigt.
Die formalen Abhängigkeiten haben den Vorteil, dass sie - bei geeigneter Gestaltung - beim Compilier- und Linkprozess auffallen
ohne dass ein funktioneller Test ausgeführt werden braucht.
5.1.2 Problem der zusätzlichen Funktionale Abhängigkeiten
Wenn es formale Abhängigkeiten gibt, sind funktionale Abhängigkeiten zu erwarten. Wenn Modul A auf Funktionen von Modul B
aufbaut, dann ist es notwendigerweise formal von B abhängig als auch selbstverständlich funktionell.
Zusätzliche funktionelle Abhängigkeiten, mit denen man möglicherweise nicht gerechnet hat und die sich bei Softwareänderungen
als Problem erweisen, entstehen entweder durch versteckte Schnittstellen oder nicht exakter Definition einer Funktionalität
an den Schnittstellen. Die Möglichkeit, solche Dinge versehentlich oder fahrlässig zu bauen, sind relativ groß:
Wenn relativ allgemeingehaltene Schnittstellen benutzt werden, dann ist deren formale Erfüllung recht einfach möglich. Angenommen,
eine Funktion wird formell wie folgt definiert:
float y = commonFunction(float x, float p1, float p2, int command);
Was die Funktion genau auszuführen hat, ist hier nicht formell spezifiziert, sondern möglicherweise nur verbal festgelegt.
Es kann nicht formal kontrolliert werden. Dieser Prototyp ist als Schnittstelle überall ganz gut einsetzbar.
So offensichtlich ungünstig wird aber oft nicht programmiert. Die Dinge sind komplexer und treten unerwartet auf. Ein einfaches
Beispiel: Ein Modul bereitet einen Wert auf und liefert zyklisch einen stetigen Wert. Ein anderes Modul verlässt sich auf
den Zyklus und den stetigen Anstieg, ohne dass dies jedoch irgendwo an einer Schnittstelle festgeschrieben wurde. Werden nun
mit einer Softwareänderung alternierende Werte geliefert, ist dies bei dem nutzenden Modul möglicherweise nie ausgetestet
wurden. Eine Änderung im Modul X bewirkt damit ein Fehlverhalten im Modul Y.
Funktionale Abhängigkeiten bei nicht vorhandenen formalen Abhängigkeiten gilt es zu vermeiden, da möglicherweise niemand diese
Abhängkeiten ahnt. Funktionalitäten müssen an Schnittstellen genau definiert werden.
Es ist günstiger, wenn funktionale Bedingungen an Schnittstellen getestet werden und ein nicht vereinbartes Verhalten mit
einer deutlichen Fehlermeldung versehen wird. Die Tolerierung von Abweichungen mit einer möglichst zweckmäßigen Reaktion ist dagegen eine Aufweichung von Schnittstellendefinitionen, die sich im nachhinein als weniger günstig erweisen
könnte.
5.2 Horizontale und vertikale Abhängigkeiten (Layer)
Eine allgemein anerkannte Software-Architektur-Regel besagt, dass Abhängigkeiten von Modulen nur von oben nach unten oder
horizontal vorliegen dürfen. Damit wird Ordnung in die Verknüpfung von Modulen gebracht. Spezialisierte oder End-Funktionalität
baut immer auf vorher definierten und/oder vorhandenen Basis-Funktionalitäten auf.
Es entstehen damit Layer (Schichten) oder Schalen des schon in den 70-ger Jahren gängigen Schalenmodells der Software. Die meist kreisförmigen Schalen eignen sich nur für einfache Übersichtsdarstellungen, Layer können großflächiger gezeichnet
und gedacht werden.
Für jedes Layer gibt es Verantwortungsbereiche: Der Lieferant der Systemsoftware für das Betriebssystemlayer (was wiederum
auch aus Schichten besteht), die Abteilung, die sich um die Kommunikationsdienste kümmert usw. usf. bis zum Projektierer,
der im obersten Layer direkt Kundenwünsche manifestiert.
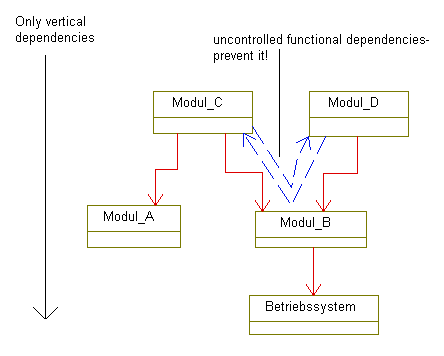
Abhängigkeiten sollten immer nur zu weiter unten liegenden Modulen bestehen: Modul A liefert seine Funktionalität ohne jegliche
Abhängigkeit zu anderen Modulen, beispielsweise ist es eine einfache Aufbereitung von Daten aus Inputs. Modul B setzt zwar
bestimmte Betriebssystemdienste voraus, beispielsweise Speichern von Daten in Files, sonst aber nichts. Modul C verknüpft
dann die Funktionalitäten von Modul A und Modul B, steht also über diesen beiden ersten Modulen.
So weit, so einfach und gut. Man kann also Modul A und Modul B unabhängig testen. Um Modul C zu testen, ist ein getestetes
und schnittstellenabgestimmtes Modul A und Modul B vorausgesetzt.
Nun kann es ein Modul D geben, dass ebenfalls Modul A und Modul B benutzt, aber für andere Funktionalitäten. Das ist eine
zweite vertikale Abhängigkeit von oben nach unten, die aber die selben Module trifft. Wenn das Verhalten eines unteren Mouduls
abhängig von der Aussteuerung von oben ein anderes Verhalten nach oben beeinflusst, dann gibt es versteckte funktionale Abhängigkeiten
ohne formale Abhängigkeiten, die zu vermeiden sind.
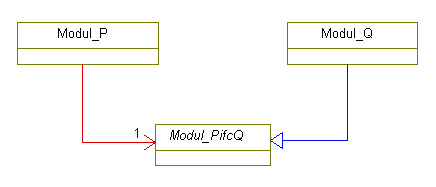
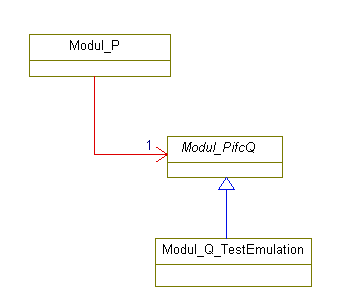
Bild: Schnittstelle zwischen 2 horizontalen Modulen Wie ist es mit einer horizontalen Verknüpfung von Modulen? Eine Teilfunktinalität wird von Modul P erledigt, Modul Q erledigt
parallel dazu eine andere Funktionalität, die abgestimmt ist. Dann müssen Modul P und Modul Q eine definierte Schnittstelle
haben. Die Schnittstelle ist unabhängig von den Modulen festlegbar und liegt damit formal weiter unten. Damit ist hier auch
nur eine vertikale Abhängigkeit vorhanden. Nach dem gezeigten Bild könnte man das Modul Q auch unterhalb von P angeordnet
sehen. Das Bild zeigt aber nur einen Ausschnitt. Angenommen es gibt weitere Module und mehrere Schnittstellen zwischen diesen,
dann kann die Parallelität von P und Q deutlicher werden. Außerdem wird die Layer-Anordnung nicht formal bestimmt, sondern
möglicherweise funktional: Die Aufgaben von Modul P und Q liegen auf dem gleichen Layer.
Bild: Test eines Moduls mit Schnittstelle zu einem horizontalen Modulen Die Richtigkeit der vertikalen Anordnung Modul-Schnittstelle zeigt sich auch an den Testmögllichkeiten: . Das Modul P ist
unabhängig von Q testbar, für den Test von P wird die Funktionalität, die die Schnittstelle zu erfüllen hat, mit einem Testmodul
ausgefüllt. Unabhängig davon wird man in der Praxis aber oft den Aufwand einer eigenen Testumgebung für jedes Modul einsparen
wollen. Die Module werden miteinander getestet, in dem jedes seine vor-durchdachte Funktionalität erfüllen sollte und das
Verhalten an der Schnittstelle kontrolliert wird.
Aus Sicht des einzelnen Moduls gibt es nur die vertikalen Schnittstellen. Aus Sicht der Gesamt-Funktionalität bestehen aber Funktionsbeziehungen zwischen Modulen aus dem selben oder gleichen Layer. Daher ist es aus dem Aspekt der Gesamtfunktionalität berechtigt, Modulbeziehungen horizontaler Art zuzulassen, formal sind
aber nur vertikale Beziehungen von oben nach unten zu gestalten.
Eine allgemein anerkannte Software-Architektur-Regel besagt, dass Abhängigkeiten von Modulen nur von oben nach unten oder
horizontal vorliegen dürfen. Die Variante, ein Modul weiter unten (Basisfunktionalität) nutzt Funktionalitäten, die weiter
oben, näher an der End-Anwendung definiert werden, wird ausdrücklich nicht empfohlen.
Diese Regel hat ihre Daseinsberechtigung unter anderem auch deshalb, weil ansonsten eine Basis-Funktionalität eine bestimmte
Anwenderfunktionalität voraussetzen würde. Außerdem könnte man beim Test der Basisfunktionalität keine Zusicherungen machen,
weil unbekannt ist, wie später dazukommende Teile im Zusammenhang mitspielen.
Andererseits, Funktionalitäten der Betriebssystemschicht wie fprintf(...) nutzen Funktionalitäten, die ganz oben im Anwendersystem und dann noch sehr verschieden realisiert sind: Die auszugebenede
Zeichenkette kann an einem Drucker erscheinen, dessen Installation ganz unterschiedlich ist, oder über eine Pipe wo ganz anders
weiterverarbeitet werden. Diese Technik ist verbreitet, etabliert und notwendig. Es ist also nicht so, dass aus Sicht der
Gesamtfunktionalität eine strikte Top-Down-Struktur eingehalten werden muss. Warum funktionieren solche Techniken? Weil die
Schnittstellen, die benutzt werden, unabhängig von einer konkreten Verarbeitung hier eine File-Ausgabe sehr wohl definiert
sind. Die Software enthält nur Top-Down-Strukturen: Immer in Richtung eines bereits definierten und getesteten Teils (Moduls,
Schnittstelle). Wenn an einer Schnittstelle dann ein neues unbekanntes Modul implementierenderweise verbunden ist, dann wird
diese Top-Down-Softwarestruktur nicht durchbrochen. Es sind ähnliche Verhältnisse wie in der Betrachtung der horizontalen
Verbindungen. Die Horizont-Linie darf also auch etwas nach oben gehen, oder steil nach oben.
Bereits bei der horizontalen Verbindung stellt sich die Frage der Verbindung der Module. Bei vertikalen Abhängigkeiten von
oben nach unten ist es immer möglich, bei der Instanziierung eines weiter oben stehenden Moduls die vorhandene Instanz eines
unteren Modul mitzuteilen. Bei horizontalen Verbindungen muss es möglicherweise ein Modul darüber geben, was für die Verbindung
der horizontalen Module zuständig ist. In dieser einfachen Art weitergedacht muss eine Verbindung von unten nach oben von
einem Modul ausgehen, was sich noch darüber befindet. Doch es gibt noch wesentlich mehr Möglichkeiten der softwaretechnischen
Ausgestaltung, wie Module miteinander verbunden werden können. Diese Frage ist im Kapitel $chapter dargestellt.
5.3 Formelle Abhängigkeiten bei Compilieren, Linken, Laden
Abhängigkeiten der Compilierung sind offensichtlich: Für einen Compilerlauf müssen andere Module vorhanden sein, sonst gibts Fehler. In C und C++ sind das Headerfiles, die includiert werden. Man kann auch c/cpp-Files includieren, für die Abhängigkeitsdiskussion ist das
derselbe Sachverhalt. Die Prüfung erfolgt hier formell, Schnittstellen auf Compilersyntaxlevel müssen stimmen.
In Java sucht der javac-Compiler aufgrund des angegebenen -sourcepath und -classpath - Aufrufargumentes die benötigten Files. Entweder sie liegen bereits compiliert als class-Files vor, oder die gefundene source.java wird zwischendrin compiliert. Im class-File sind dann die Schnittstellen bytecode-codiert enthalten und werden vom javac-Compiler herausgelesen.
Abhängigkeiten bei der Compilierung führen dazu, dass bei Änderung der Schnittstelle (Headerfile, clazz-File) eine erneute
Compilierung durchgeführt werden muss. Das wird von einem Maker oder einem Versionsmanagement-System erkannt. Auch wenn sich
ein Headerfile nur formal ändert, beispielsweise in einem Kommentar, ist aus File-Zeitstempel-Vergleichssicht die erneute
Compilierung notwendig.
Abhängigkeiten beim statischen Linken: In C und C++ muss eine Executable neu gelinkt werden, wenn ein Objektmodul neu compiliert wurde oder sich eine Library geändert
hat. Das wird ebenfalls von einem Maker oder Versionsmanagementsystemen organisiert. Erneutes Erzeugen eines Executables bedeutet
aber auch: Testen, Ausliefern, also ein gegebenenfalls hoher Folgeaufwand. Womöglich ist eine Library aber nur in einer nicht
hier zutreffenden Funktionalität geändert. Dann muss dies aber erkannt und geprüft werden. Je besser Software-Module voneinander
unabhängig sind, desto weniger formeller Aufwand entsteht.
In Java liegt bezüglich einer "Excecutable" vergleichbare Verhältnisse wie in C++ mit dynamischen Libraries (dll) vor: Es gibt keinen
Linker, die Verbindung der Module wird zur Abarbeitungszeit realisiert. Man kann Klassen in verschiedenen jar-Files speichern.
Beim Aufruf eines Java-Programmes wird der CLASSPATH oder Aufrufargument -cp angegeben, er kann verschiedene jar-Files oder Verzeichnisse mit class-Files enthalten, wobei die Reihenfolge einzelner Path-Bestandteile
eine Rolle spielt. Damit ist es möglich, für die eine oder andere Abarbeitung auf einen Anwendersystem, auf dem noch ganz
andere Java-Software mit anderen Versionen laufen muss, die Versionen passend zusammenzustellen. Das wird man nicht in der
Regel machen, in der Regel sind alle Bestandteile in einem jar-File zusammengefasst und es werden System-jar-Files benutzt,
aber es geht. Damit kann man Versionskonflikte beherrschen. Man kann auch einzelne clazz-Files auf vorhandenen (fremden) jar-Files
löschen oder ersetzen. Jar-Files sind einfache zip-Files und mit jedem zip-Programm, wie es beispielsweise der Total Commander eingebaut bereits kann. Hierbei ist natürlich die Kenntnis der Abhängigkeiten (Welches Modul braucht welches) wichtig.
Einerseits kann ein System meist nicht so gebaut werden, dass ein Modul auf vorhandenen anderen Modulen aufbaut, vielmehr
gibt es Module auf gleichem Level, die zusammengeschaltet werden müssen. Andererseits kann ein Modul, dass als Voraussetzung
für ein anderes Modul gilt, gegebenenfalls noch nicht fertig entwickelt sein oder es soll ausgetauscht werden können. Letzlich
gibt es auch notwendigerweise gegenseitige Verbindungen von Modulen, oder komplexere zirkulare Abhängigkeiten (A braucht B,
B braucht C, C braucht aber A).
Demzufolge müssen Abhängigkeiten gebrochen werden, sonst ist keine unabhängige Entwicklung von Modulen möglich. Klassischerweise
stellt ein Headerfile in C/C++ bereits einen solchen Break dar: Ein Headerfile enthält nur die Schnittstelle zu einem Ablaufcode,
der Ablaufcode selbst, im C-File, interessiert formell nicht. Die Verbindung schafft dann der Linker, aber auch nur formell
über Einsprunglabels. Es gibt mehrere solcher Mechanismen:
5.4.1 Interfacekonzept in Java und C++ als Dependency-Break
Das Interfacekonzept, wie es in Java Sprachbestandteil ist und von daher als Grundkonzept der Objektorientierung angesehen werden kann, ist ein
bekanntes und leistungsfähiges Mittel zum Aufbrechen von Abhängigkeiten: Ein Interface beschreibt formell eine Schnittstelle.
Der Aufrufer kann diese Schnittstelle verwenden, ohne dass bereits definiert ist, wie die Implementierung aussehen wird. Es
ist vorab eine Musterimplementierung möglich, die für einen Modultest benutzt werden kann. Es ist ein Austausch der Implementierung
bei unveränderter Schnittstelle möglich, ohne dass dies zur Notwendigkeit einer Neucompilierung führt.
Wenn man so will, ist die Aufteilung von Header- und C-Files in C ein Urvater des Interfacekonzeptes: Im Headerfile wurden
Schnittstellen deklariert, die dann zur Linktime mit den implementierenden Modulen besetzt wurden. Das ist allerdings statisch.
Das Interfacekonzept ist dynamisch:
Es ist möglich, in der selben Executable ein Interface mehrfach zu verwenden, aber jedesmal dahinter eine andere Implementierung
anzubinden.
Es ist möglich, die Implementierung eines Interfaces zur Laufzeit auszutauschen.
Basis dafür sind die so genannten virtuellen Methoden in C++ bzw das dynamische Binden von Methodenaufrufen. Ein solches Verhalten ist auch im reinen C implementierbar, mit Aufruf
von Subroutinen über Funktionszeiger, gegebenenfalls in Methoden-Adresstabellen (Sprungleisten) organisiert.
Der Mechanismus bei Verwendung von Basisklassen, die abstrakt sein können oder nicht, ist hinsichtlich des Aufbruchs von Abhängigkeiten
formell der selbe wie mit Interfaces. In C++ sind Interfaces und Basisklassen formell auch nicht unterschieden. Klassen in
C++ entsprechen dem Java-Interfacekonzept, wenn sie nur abstrakte Methoden enthalten, keine Klassen-Daten und keine implementierten
Methoden. Der Unterschied von Interfaces und Basisklassen liegt an anderer Stelle, im Bereich der Implementierung, Mehrfachvererbungsprobleme
und dergleichen. Allerdings ist aus Software-Design-Sicht für die Abhängigkeitsdiskussion schon ein Unterschied vorhanden.
Ein Interface definiert nur eine Schnittstelle, keinerlei Implementierung wird vorausgesetzt.
Wenn ein Modul über eine Basisklasse angesprochen wird, dann wird eine Grundeigenschaft vorausgesetzt, zwar noch nicht die
komplette Implementierung, aber eine gewisse Implementierung.
Auch wenn sich eine Klasse nur über Interfaces oder Basisklassen nach außen zeigt, so muss sie doch an einer Stelle in ihrer
ganzen Vollständigkeit bekannt sein: Bei ihrer Instanziierung. Es sei denn, man benutzt eine Factory.
Wenn eine Klasse bei ihrer Instanziierung bekannt sein muss, dann muss dasjenige Modul, das instanziiert, neu compiliert und
ausgeliefert werden, wenn sich die instanziierte Klasse, in einem anderen Modul ändert. Damit sind dynamische Konzepte nicht
gut nutzbar. Oder es werden Fehler gemacht: In C oder C++ kann sich ein Headerfile ändern. Es wird aber vergessen erneut zu
compilieren. Damit sind Daten und/oder virtuelle Methoden verschoben. Beim Linken wird der Fehler nicht bemerkt. Der Fehler
wird womöglich zunächst gar nicht bemerkt, weil die Verschiebung nicht für alle Funktionalitäten auffällt.
Bild: einfache Factory Eine einfache Factory funktioniert so, dass eine statische Methode oder auch nicht-statische Methode einer Factoryklasse
gerufen wird. Die Factoryklasse muss die zu instanziierende Klasse kennen, das instanziierende Modul muss die Factoryklasse
kennen. Die Factoryklasse kann aber wesentlich stabiler - nicht von Änderungen betroffen sein, da sie eigentlich nur die Factorymethode,
sonst nichts weiter enthält. Die Factoyklasse gehört zu dem Modul, dessen Klassen sie instanziiert. Factories können aber
in eigenen Packages geführt werden, Abhängigkeiten können dann auf gesamte Packages bezogen werden. Die Instanz wird dem Aufrufer
"nur" über ein Interface oder eine Basisklasse bekanntgegeben. Das reicht für den Zugriff. Damit ist eine weitestgehende Entkopplung
erreicht.
Ein komplexes Factory-Pattern beherrscht noch die Fabrikation zueinandergehöriger Instanzen, im Schulbeispiel oft mit "Fischgericht"
und den zugehörigen Bestecks dargestellt. Das ist aber ein anderer Gesichtspunkt.
Es gibt noch eine weitere Abstraktion, bei der nicht einmal die Factoryklasse compilertechnisch bekannt sein braucht: Die
Instanziierung mittels textueller Angabe des Namens/Packagepfades der Factoryklasse. Das Suchen und Instanziieren der Factoryklasse
wird dann vom Laufzeitsystem, in Java von der Virtuellen Maschine, vorgenommen. Die Factoryklasse muss die bekannte Factory-Methode
bereitstellen, die Instanz muss sich über ein Interface repräsentieren. Mehr ist seitens der formellen Abhängigkeit nicht
notwendig - eine weitestgehende Entkopplung geeignet für unabhängige Module.
5.4.4 Dependency Injection - Außeneinprägung der Abhängigkeit
Nach dem Factory-Pattern gibt es noch eine weitergehende Vermeidung von Abhängigkeit. Mit dem Factory-Pattern braucht zwar
ein Modul keine Detailkenntnis dessen, was instanziiert werden soll, es muss aber wissen was es instanziiert. Damit ist vorbestimmt,
dass Modul A ein Modul Y mit dem Interface y benutzt, und nicht etwa Y1oder Z. Besser wäre es aber, das Modul kennt nur die
Schnittstelle. Alles andere ist Sache einer darüberliegenden Schicht. Diese kann beispielsweise aufgrund verschiedener Konfigurationsangaben
das eine oder andere Modul instanziieren und zuordnen. Das Konzept erweist sich auch für den Modul-Test als essentiell: Normalerweise
wird Modul Y benutzt. Im Test aber statt dessen ein Modul Y_test, ohne dass an dem zu testenden Modul etwas geändert wird.
Auch für eine unabhängige Entwicklung ist die Dependency-Injection ein gutes Mittel: Modul A wird fertiggestellt, ohne dass
Modul Y dazu irgendwie benötigt wird, man kann bis zur Integration einen einfachen Ersatz mit selber Schnittstelle benutzen.
Entwicklerteams können unabhängig voneinander arbeiten. Dependency-Injection kann daher als ein Muss einer guten Entwicklung angesehen werden.
Schnittstellen beschreiben das Verhalten eines Moduls nach außen. Schnittstellen sind ein Vertrag -Kontrakt, und damit reines
Papier, kein Maschinencode.
Papier ist natürlich Software. In der Software sind Schnittstellen
Datendefinitionen, in C struct in Headerfiles.
Konstantendefinitionen, in C define oder enum-Konstanten in Headerfiles.
Subroutinendefinitionen, in C Funktionsprototypen in Headerfiles.
In Java interfaces, in C++ classes mit ausschließlich virtuellen abstracten Methoden und Konstantendefinitionen.
Das interfaces in Java keine Daten enthalten sollen, liegt einerseits an dem Wunsch nach Kapselung der Daten (ist also eher
nicht von einem Schnittstellengedanken, sondern einem Programmiergedanken geprägt). Andererseits liegt es aber daran, dass
damit realisierungstechnisch die Probleme der Mehrfachvererbung vermieden werden. Java-interfaces und C++-classes ohne Daten
mit ausschließlich abstracten Methoden belegen in den implementierenden Klassen nur eine Position als Zeiger auf die sogenannte
virtuelle Tabelle (vtbl), mehr nicht. Sind Daten im Spiel, muss der Compiler noch einiges mehr beachten wie unter anderem
eine mehrdeutige Bezeichnung bei Mehrfachvererbung, oder den Umfang von Speicherbereichen. Sind nicht abstracte Methoden im
Spiel, dann gibt es zur C++-Schnittstellenklasse noch eine Implementierung. Das ist aber dann keine Schnittstelle mehr.
Eine Schnittstelle ist nur Kontrakt, keine Realisierung.
Damit sind Schnittstellen formal syntaktisch fassbar. Aber das reicht nicht.
Eine Anmerkung am Rande: Oft werden Dokumentationen geschreiben, die umständlich ausgedrückt Schnittstellen zwischen Partnern
juristisch sicher beschreiben sollen, dabei aber schnell an unverständlicher und ungenaue Formulierungsgrenzen stoßen. Werden
solche Dokumente mit Headerfiles als Anhang, die mitgelten, komplettiert, dann ist das Ganze oft einfacher und klarer.
Ist die Compilersyntax von Schnittstellen definiert, dann ist etwa die Hälfte in trockenen Tüchern. Die andere Hälfte ist
der Kontrakt, wie das Verhalten hinter der Schnittstelle ist.
Wenn eine add-Routine bei Inputwerten 3 und 5 eine 8 liefern soll, dann ist dies nur in der verbalen Beschreibung der Routine
formulierbar. Was ist aber, wenn der Leser voraussetzt, selbstverständlich wird eine 8 geliefert, aber die Beschreibung sagt
etwas anderes.
Noch komplexer ist es, wenn ein Modul ein Verhalten hat, sich einen Zustand merkt. Dann ist die Reaktion auf Inputs abhängig
vom inneren Zustand, der ist aber von vorigen Inputs bestimmt. Für diesen Zweck hat man in der UML bzw. SysML die interface-statecharts erfunden. Diese dokumentieren das Verhalten des Moduls an den Schnittstellen.
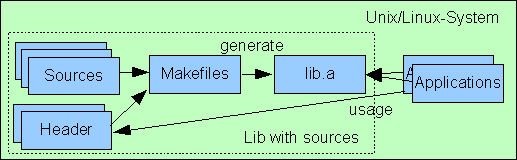 Bild: Sources und Libraries Linux
Bild: Sources und Libraries Linux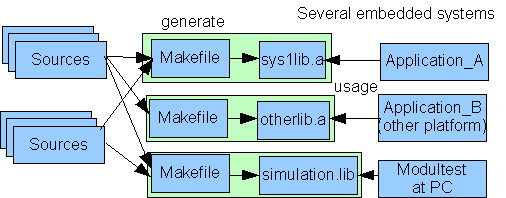 Bild: Sources and Libraries in Embedded Systemen
Bild: Sources and Libraries in Embedded Systemen